안녕하세요,
알리바바는 텍스트 생성 모델뿐만 아니라 다양한 이미지 생성 기술을 지속적으로 확장해왔으며, 특히 이미지 보정과 요소 변경에 특화된 모델을 꾸준히 선보여왔습니다. 이러한 개발 흐름 속에서 2025년 11월에는 새로운 버전의 이미지 수정 모델이 업데이트되어 공개되었습니다.
이번 글에서는 해당 모델인 Qwen-Image-Edit 모델을 ComfyUI 환경에서 활용하는 기본 절차와 실사용 방법을 중심으로 정리하여 소개합니다.
Qwen-Image-Edit-2511
Qwen-Image-Edit-2511 모델은 알리바바 AI 팀이 공개한 이미지 편집 특화 오픈소스 모델이며, 이전 버전인 Qwen-Image-Edit-2509의 기능을 확장·개선한 형태입니다. 이 모델은 기존 이미지에 텍스트 지시를 바탕으로 수정 작업을 수행하도록 설계되어 있으며, 자연어 기반의 편집 지시를 통해 객체 추가·삭제, 스타일 변화 등 다양한 편집 작업을 처리할 수 있습니다.
- Qwen 허깅페이스 : https://huggingface.co/Qwen/Qwen-Image-Edit-2511
Qwen/Qwen-Image-Edit-2511 · Hugging Face
💜 Qwen Chat | 🤗 Hugging Face | 🤖 ModelScope | 📑 Tech Report | 📑 Blog 🖥️ Demo | 💬 WeChat (微信) | 🫨 Discord | Github Introduction We are excited to introduce Qwe
huggingface.co
주요 특징
- 향상된 일관성 유지 : Qwen-Image-Edit-2511은 편집 과정에서 이미지 드리프트(원본 특징이 흐려지는 현상)를 완화하며, 특히 인물 중심 편집 시 정체성과 시각적 특성 유지 성능이 크게 강화되었습니다. 여러 인물이 포함된 장면에서도 다중 인물 일관성을 보다 안정적으로 유지합니다.
- LoRA 통합 지원 : 기존 커뮤니티에서 개발된 인기 있는 LoRA(경량 적응 모델) 스타일 및 기능이 기본 모델에 내장되어 있으며, 추가 튜닝 없이도 다양한 표현 가능성을 활용할 수 있도록 설계되어 있습니다.
- 산업 응용 및 기하학적 추론 : 산업 디자인 관련 편집, 배치 작업 등 실용적 편집 워크플로우가 강화되었으며, 기하학적 안정성을 고려한 추론 능력이 확장되었습니다. 이를 통해 전문적인 디자인 수정에도 효과적으로 활용할 수 있습니다.
- 자연어 기반 지시 처리 : 텍스트 지시를 입력하면 모델이 시각적·텍스트적 의미를 함께 고려하여 정밀한 편집 작업을 수행할 수 있으며, 초급 사용자도 비교적 직관적으로 활용할 수 있는 접근성을 갖추고 있습니다.
라이선스
Qwen-Image-Edit-2511 모델은 Apache 2.0 라이선스로 공개되어 있어 상업적 활용이 가능하다는 점이 중요한 특징입니다. Apache 2.0은 기업과 개인 모두가 모델을 자유롭게 수정·배포하고 제품이나 서비스에 포함할 수 있는 구조로 설계된 범용 라이선스이며, 별도의 로열티가 요구되지 않습니다. 다만 활용 과정에서 라이선스 명시와 저작권 고지를 유지해야 하므로, 관련 표기를 문서나 안내 페이지에 포함하는 방식으로 요건을 충족할 수 있습니다. 이러한 조건을 기반으로 Qwen-Image-Edit-2511 모델은 실무 환경에서도 무리 없이 적용할 수 있으며, 로컬 환경에 설치하여 직접 이미지 편집 워크플로우를 구성하는 방식으로도 활용 가능합니다.
이제부터는 ComfyUI를 활용하여 해당 모델로 이미지를 수정하는 과정을 단계별로 정리한 실전 가이드를 소개합니다.
실전 가이드 (ComfyUI를 활용하여 Qwen-Image-Edit 모델로 이미지 편집하기)
이 내용은 ComfyUI와 Qwen-Image-Edit-2511 모델을 이용해 로컬 환경에서 이미지 편집 작업을 수행하는 절차를 설명합니다.
목차
1. 실행 환경
2. ComfyUI 다운로드
3. Workflow 및 모델 다운로드
4. 영상 생성
1. 실행 환경
- 운영체제 : Windows 11
- ComfyUI : 0.7.0
- ComfyUI-Manager : V3.30
- Python : 3.10.11
- torch : 2.9.1 + cu128
- GPU : NVIDIA GeForce RTX 4060 Ti (vram : 16GB)
2. ComfyUI 설치
아래 링크를 통해 사용 중인 PC 환경에 맞는 버전을 선택하여 ComfyUI를 다운로드 및 설치합니다.
- ComfyUI 다운로드 : https://www.comfy.org/download
3. Workflow 및 모델 다운로드
최신 ComfyUI에서는 웹 UI 내에서 워크플로우를 간편하게 불러올 수 있습니다.
- ComfyUI를 실행
- 왼쪽탭에서 "Templates" 버튼 클릭
- "Image" 항목에서 "Qwen Image Edit 2511 - Material Replacement" 클릭

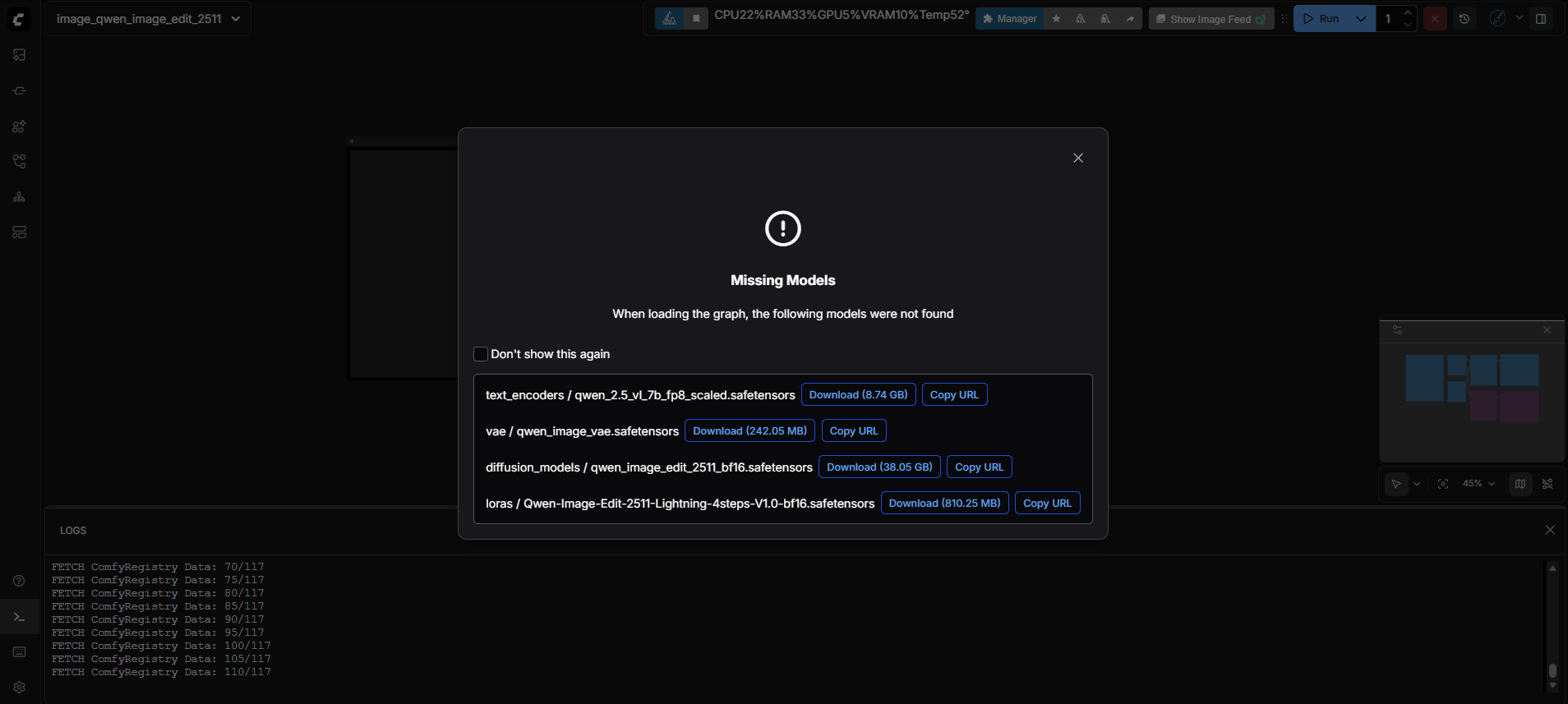
ComfyUI에서 워크플로우 파일을 불러오면, 해당 모델을 자동으로 탐색하며, 로컬에 모델이 없는 경우 다운로드 링크를 안내해줍니다. 이 링크를 통해 손쉽게 필요한 모델 파일을 다운로드할 수 있습니다.
모델 다운로드가 완료되면, 아래와 같이 지정된 폴더 구조에 맞게 파일을 이동해 줍니다. 모든 모델 파일을 다운로드한 후에는 위 구조에 맞게 해당 위치로 옮겨야 합니다.
📂 ComfyUI/
├── 📂 models/
│ ├── 📂 text_encoders/
│ │ └── qwen_2.5_vl_7b_fp8_scaled.safetensors
│ ├── 📂 loras/
│ │ └── Qwen-Image-Edit-2511-Lightning-4steps-V1.0-bf16.safetensors
│ ├── 📂 diffusion_models/
│ │ └── qwen_image_edit_2511_bf16.safetensors
│ └── 📂 vae/
│ └── qwen_image_vae.safetensors
4. 이미지 수정
Qwen-Image-Edit-2511 모델을 활용하여 실제 이미지 편집을 진행하였습니다. 해당 모델을 안정적으로 사용하기 위해서는 최대 약 30GB 이상의 VRAM이 필요했고, 한 장의 이미지를 생성하는 데 약 1분 30초가 소요되었습니다. 이 모델은 하나의 이미지를 자연어 기반으로 직접 수정하는 방식과 두 장의 이미지를 활용하여 하나의 이미지로 합성하는 방식 모두를 지원합니다.
아래에는 단일 이미지 편집과 복합 이미지 편집 사례를 각각 소개합니다.
1) 단일 이미지 포즈 변경 편집
[입력 프롬프트 1]
Change the woman from image 1 into a new pose with both arms raised above her head, holding a rectangular sign that reads ‘Marcus' Story’. Keep her facial features, hairstyle, and overall appearance consistent. Maintain the original clothing style, adjusting the sleeves naturally to match the raised-arm pose. Ensure the body proportions remain realistic, and integrate the sign naturally into her hands. Preserve lighting and shading for a cohesive and natural look.
[생성 결과 1]


2) 두 장의 이미지를 활용한 배경 합성 편집
[입력 프롬프트 2]
Place the woman from image 1 naturally on the left sidewalk of the London city background from image 2. Ensure she is standing on the pedestrian walkway, aligned with the perspective of the street. Keep her proportions, pose, and details unchanged. Match the lighting and shadows to blend her seamlessly with the surroundings, without placing her on the road.
[생성 결과 2]



Qwen-Image-Edit-2511 모델은 이미지 내 특정 요소를 자연스럽게 수정하거나 여러 장의 이미지를 결합해 새로운 장면을 구성하는 과정에서 높은 활용성을 보여주는 도구입니다. 자연어 기반의 지시만으로 포즈 변경, 배경 합성, 재질 교체 등 다양한 편집 작업을 수행할 수 있으며, 복잡한 워크플로우 없이도 직관적으로 원하는 결과를 얻을 수 있다는 점이 특징입니다. 실제 실험 과정에서도 단일 이미지 편집과 복합 이미지 생성 모두 안정적으로 처리되었으며, 다양한 편집 요구에 유연하게 대응한다는 점을 확인할 수 있었습니다.
생성된 결과를 보면 상당히 자연스러운 편집이 이루어졌음을 알 수 있습니다. 높은 수준의 품질을 구현하기 위해 다소 큰 VRAM이 필요했지만, 이 정도의 완성도 있는 이미지를 간단한 입력만으로 생성할 수 있다는 점은 인상적이었습니다. 이러한 기술의 발전은 콘텐츠 제작과 디자인뿐 아니라 개인 창작 활동 전반에 새로운 편집 경험을 제공하는 기반으로 이어질 것으로 기대됩니다.
감사합니다. 😊
'ComfyUI > 이미지 생성 및 수정' 카테고리의 다른 글
| [ComfyUI] 나노 바나나 프로에 견줄만한 오픈소스 이미지 생성 모델, Z-Image 소개 | 로컬환경 (0) | 2025.12.05 |
|---|---|
| [ComfyUI] Lodestones에서 공개한 고성능 이미지 생성 모델, Chroma1을 소개합니다. | 오픈소스 AI (2) | 2025.10.02 |
| [AI 이미지 편집] Qwen-Image + ControlNet 활용 가이드|ComfyUI로 쉽게 따라하기 (2) | 2025.09.08 |
| [ComfyUI + Qwen-Image-Edit] AI 이미지 편집 가이드|빠르고 간편한 활용 방법 (6) | 2025.08.25 |
| [ComfyUI + Qwen-Image] 로컬 환경 고품질 이미지 생성 가이드 | 오픈소스 AI 활용 | (4) | 2025.08.11 |



