안녕하세요,
최근 이미지 생성 모델 분야에서 커다란 변화가 일어나고 있습니다. 구글의 나노 바나나 프로(Nano Banana Pro) 모델이 등장하며 업계의 새로운 기준으로 주목받고 있습니다. 이에 대응하듯 알리바바에서도 강력한 성능의 오픈소스 이미지 생성 모델을 공개하였습니다. 해당 모델은 오픈소스임에도 불구하고 탁월한 표현력과 세밀한 이미지 품질을 제공하는 것으로 평가되고 있습니다.
이번 글에서는 알리바바가 새롭게 선보인 이미지 생성 모델 Z-Image의 주요 특징과 ComfyUI를 사용하여 로컬에서 사용하는 방법에 대해 살펴보겠습니다.
Z-Image 모델이란
2025년 11월 26일, 알리바바 그룹 산하 Tongyi Lab에서 새로운 텍스트-이미지 생성 모델, Z-Image를 공개했습니다. 이 모델은 약 60억 개의 파라미터(6B)로 구성되어 있으며, 효율적인 구조를 통해 고품질의 이미지를 생성할 수 있도록 설계되었습니다. 이 모델은 단순히 대규모 모델로 성능을 끌어올리는 기존의 방향에서 벗어나, 경량화와 표현력의 균형을 이루는 것을 목표로 하고 있습니다.
또한 Z-Image는 모델 가중치뿐만 아니라 코드와 온라인 데모까지 함께 공개하여 누구나 접근할 수 있도록 지원하고 있습니다. 이를 통해 연구자와 개발자는 물론, 일반 사용자도 직접 모델을 활용하고 실험할 수 있는 개방형 생태계를 조성하고 있습니다. 나아가 이미지 생성뿐 아니라 편집 기능까지 포함된 파생 모델을 함께 제공하여, 오픈소스 이미지 생성 기술의 실용성을 한층 강화하였습니다.
- Z-Image 프로젝트 페이지 : https://tongyi-mai.github.io/Z-Image-blog/
[모델 정보 요약]
| 모델명 | Z-Image-Turbo |
| 파라미터 수 | 6B (60억) |
| 개발사 | Alibaba Group (Tongyi Lab) |
| 아키텍처 | Scalable Single-Stream Diffusion Transformer (S3-DiT) |
| 특징 | - 8스텝 샘플링 기반의 고속 추론 - 포토리얼리스틱 이미지 품질 - 중국어·영어 텍스트 렌더링 - 이미지 생성 및 편집 지원 |
| 라이선스 | Apache-2.0 라이선스 |
| 모델 경로 (허깅페이스) |
https://huggingface.co/Tongyi-MAI/Z-Image-Turbo |
주요 특징
- 단일 스트림 Diffusion Transformer 구조 : Z-Image는 텍스트 임베딩, 이미지 토큰, 노이즈 잠재 벡터를 하나의 시퀀스로 결합하여 Transformer에 입력하는 단일 스트림 구조(Single-Stream Diffusion Transformer)를 채택하고 있습니다. 이 구조는 텍스트와 이미지 간의 상호작용을 자연스럽게 유지하면서 계산 효율을 높이고 메모리 사용량을 절감하는 특징을 갖추고 있습니다.
- 고속 추론과 소수 스텝 샘플링 : Z-Image-Turbo는 약 8스텝 내외의 짧은 과정만으로도 고품질 이미지를 생성할 수 있도록 설계되었습니다. 이를 통해 기존 확산 모델 대비 빠른 추론 속도를 제공하며, 개인용 GPU 환경에서도 원활히 작동할 수 있습니다.
- 사실적인 이미지 품질 : Z-Image는 조명, 질감, 색감 등의 시각적 요소를 정밀하게 표현하여 포토리얼 수준의 이미지를 생성합니다. 인물, 사물, 풍경 등 다양한 장면에서도 높은 사실감과 디테일을 유지합니다.
- 텍스트 렌더링 및 다언어 프롬프트 지원 : 이미지 내 중국어와 영어 텍스트를 자연스럽게 렌더링할 수 있으며, 복잡한 장면 구성이나 다중 객체 관계를 포함한 프롬프트도 정확하게 반영합니다.
- 이미지 생성 및 편집 기능 통합 : Z-Image-Edit 모델은 기존 이미지를 입력받아 자연어 명령에 따라 객체 수정, 배경 변경, 스타일 조정 등 다양한 편집 작업을 수행할 수 있습니다.
- 경량 구조와 오픈소스 접근성 : 약 60억 개의 파라미터로 구성된 경량 구조를 통해 낮은 자원 환경에서도 구동이 가능하며, 모델과 코드가 오픈소스로 공개되어 누구나 연구와 응용에 활용할 수 있습니다.
라이선스
Z-Image 모델은 Apache License 2.0을 따르고 있습니다. 이 라이선스는 오픈소스 라이선스 중에서도 상업적 활용이 명확히 허용되는 가장 자유로운 형태의 라이선스에 해당합니다. 사용자는 모델을 자유롭게 연구, 수정, 배포, 상업적 제품에 통합할 수 있으며, 별도의 사용료나 로열티를 지불할 필요가 없습니다.
다만, Apache-2.0은 다음과 같은 조건을 준수해야 합니다.
- 모델 또는 수정된 버전을 재배포할 경우, 원 저작권 표기와 라이선스 전문을 함께 포함해야 합니다.
- 모델을 수정하거나 재가공한 경우, 해당 변경 사항을 명확히 표시해야 합니다.
- 상표권(Trademark)에 대한 권리는 포함되지 않으므로, “Z-Image”라는 명칭을 상업적으로 사용할 때는 별도의 허락이 필요할 수 있습니다.
즉, Z-Image는 상업적 프로젝트나 제품 내 탑재가 법적으로 가능하며, 기업이나 개인 개발자가 자사 서비스에 모델을 통합하여 사용할 수 있습니다. 단, 재배포 시 저작권 고지와 라이선스 명시 의무를 반드시 준수해야 합니다.
실전 가이드 (ComfyUI에서 Z-Image모델로 이미지 생성하기)
이 포스팅에서는 ComfyUI와 HuMo 17B 모델을 사용하여 영상 생성 방법에 대해 알아보겠습니다.
목차
1. 실행 환경
2. ComfyUI 다운로드
3. Workflow 및 모델 다운로드
4. 영상 생성
1. 실행 환경
- 운영체제 : Windows 11
- ComfyUI : 0.3.76
- ComfyUI-Manager : V3.30
- Python : 3.10.11
- torch : 2.9.1 + cu128
- GPU : NVIDIA GeForce RTX 4060 Ti (vram : 16GB)
2. ComfyUI 설치
아래 링크를 통해 사용 중인 PC 환경에 맞는 버전을 선택하여 ComfyUI를 다운로드 및 설치합니다.
- ComfyUI 다운로드 : https://www.comfy.org/download
3. Workflow 및 모델 다운로드
최신 ComfyUI에서는 웹 UI 내에서 워크플로우를 간편하게 불러올 수 있습니다.
- ComfyUI를 실행
- 왼쪽탭에서 "Templates" 버튼 클릭
- "Image" 항목에서 "Z-Image-Turbo Text to Image" 클릭


ComfyUI에서 워크플로우 파일을 불러오면, 해당 모델을 자동으로 탐색하며, 로컬에 모델이 없는 경우 다운로드 링크를 안내해줍니다. 이 링크를 통해 손쉽게 필요한 모델 파일을 다운로드할 수 있습니다.
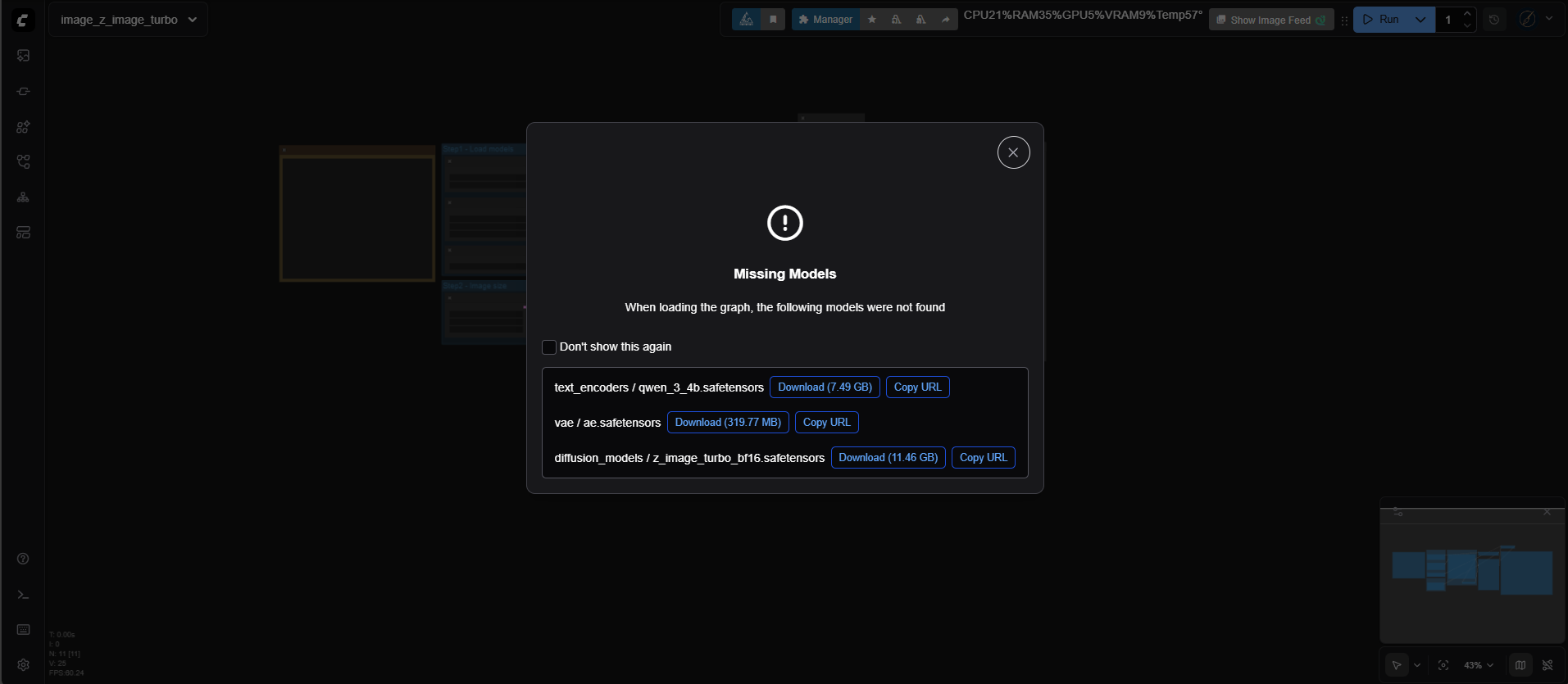
모델 다운로드가 완료되면, 아래와 같이 지정된 폴더 구조에 맞게 파일을 이동해 줍니다. 모든 모델 파일을 다운로드한 후에는 위 구조에 맞게 해당 위치로 옮겨야 합니다.
ComfyUI/
├───📂 models/
│ ├───📂 diffusion_models/
│ │ ├─── z_image_turbo_bf16.safetensors
│ ├───📂 text_encoders/
│ │ └─── qwen_3_4b.safetensors
│ ├───📂 vae/
│ │ └── ae.safetensors
4. 이미지 생성
Z-Image-Turbo 모델을 활용하여 실제 이미지 생성을 진행하였습니다. 실제 테스트 환경에서 사용된 Vram은 약 20GB가 사용되었으며, 약 25초 내외의 시간으로 이미지를 완성하였습니다. 테스트로 생성한 이미지는 아래 두가지 프롬프트를 사용하여 생성하였습니다.
[입력 프롬프트]
- Latina female with thick wavy hair, harbor boats and pastel houses behind. Breezy seaside light, warm tones, cinematic close-up.
- Golden retriever running along the seaside, mid-leap with splashing seawater around its paws. Soft morning light, gentle waves, warm coastal tones, cinematic action shot with shallow depth of field.
Z-Image-Turbo 모델은 짧은 생성 시간에도 불구하고 세밀한 질감 표현과 자연스러운 색조 균형을 보여주었습니다. 인물 장면에서는 빛의 방향과 피부 질감, 머리카락의 흐름이 사실적으로 표현되었고, 배경의 항구 풍경이 부드러운 파스텔톤으로 조화되었습니다.
또한 강아지 이미지는 바닷물의 튀김, 모래의 질감, 역동적인 움직임이 생생하게 구현되어, 정지 이미지임에도 강한 동적 느낌을 전달했습니다.
특히, 최근 가장 주목받는 이미지 생성 모델인 나노 바나나 프로(Nano Banana Pro)와 비교하더라도, Z-Image-Turbo는 품질과 생성 속도 모두에서 뒤처지지 않는 경쟁력을 보여주었습니다. 그럼에도 불구하고 이 모델은 오픈소스 형태로 공개되어 누구나 쉽게 사용할 수 있습니다.
[생성 결과]


Z-Image-Turbo 모델은 효율적인 구조와 높은 표현력을 결합하여, 오픈소스 이미지 생성 기술의 새로운 기준을 제시하였습니다. 대규모 상용 모델에 견줄 만한 품질과 속도를 확보하면서도, 누구나 접근 가능한 개방형 형태로 공개되었다는 점에서 기술 발전의 방향성을 잘 보여주고 있습니다.
이러한 접근은 인공지능 이미지 생성의 대중화를 앞당기고, 개인 창작자와 개발자 모두가 고품질 시각 콘텐츠를 손쉽게 제작할 수 있는 환경을 마련하였습니다. 앞으로 Z-Image와 같은 개방형 모델의 발전은 상업적 독점 구조를 완화하고, 창의적 생산성과 기술 공유의 균형을 이루는 중요한 계기가 될 것으로 기대됩니다.
감사합니다. 😊
'ComfyUI > 이미지 생성 및 수정' 카테고리의 다른 글
| [ComfyUI] Lodestones에서 공개한 고성능 이미지 생성 모델, Chroma1을 소개합니다. | 오픈소스 AI (2) | 2025.10.02 |
|---|---|
| [AI 이미지 편집] Qwen-Image + ControlNet 활용 가이드|ComfyUI로 쉽게 따라하기 (2) | 2025.09.08 |
| [ComfyUI + Qwen-Image-Edit] AI 이미지 편집 가이드|빠르고 간편한 활용 방법 (6) | 2025.08.25 |
| [ComfyUI + Qwen-Image] 로컬 환경 고품질 이미지 생성 가이드 | 오픈소스 AI 활용 | (4) | 2025.08.11 |
| 포토샵처럼 이미지 수정하는 AI, OmniGen2를 소개합니다. | ComfyUI | 오픈소스 | 로컬환경 (2) | 2025.07.10 |



