안녕하세요,
최근 국내 인공지능 스타트업 모티프 테크놀로지스(Motif Technologies)에서 자사 연구를 통해 개발한 대형 언어 모델 Motif 2를 공개했습니다. 이 모델은 한국어 중심의 언어 이해와 자연스러운 문장 생성을 목표로 설계되었으며, 자체 개발한 병렬화·효율화 기술을 통해 높은 연산 효율과 추론 성능을 구현했습니다.
이번 포스팅에서는 Motif 2 모델의 구조적 특징, 성능, 그리고 실제 사용 방법까지 자세히 살펴보겠습니다.
Motif 2 모델
국내 인공지능 기업 모티프테크놀로지스(Motif Technologies)가 차세대 대형언어모델 Motif 2를 공식 공개했습니다. 이번 모델은 약 127억 개(12.7B) 의 매개변수를 지닌 최신 언어모델로, 인간의 지시문을 이해하고 복잡한 추론 과정을 수행할 수 있도록 설계되었습니다. 특히 학습 효율화 기술과 병렬화 구조를 자체 개발해 기존 동급 모델 대비 뛰어난 성능을 달성했습니다.
- 모티프 테크놀로지 공식페이지 : https://motiftech.io/ko/
Motif Technologies
Motif offers optimized cloud infrastructure and tailored AI models — from daily tasks to enterprise-scale applications.
motiftech.io
[모델 정보 요약]
| 항목 | 모델 버전 |
|
| 모델명 | Motif-2-12.7B-Instruct | Motif-2-12.7B-Base |
| 파라미터 수 | 12.7B | |
| 개발사 | 모티프테크놀로지스(Motif Technologies) | |
| 아키텍처 | Transformer 기반 | |
| 학습 프레임워크 | 지도학습(SFT) 기반 조정 버전 | 사전학습된 베이스 모델 |
| 특징 | • “SFT variant”로서 베이스 모델 위에 지시문-응답 스타일로 미세조정됨 • 최대 시퀀스 길이 32K 토큰 대응 가능 • 벤치마크 상 동급 대비 평균 약 +14.48% 성능 향상 (vs Gemma 3 12B) |
• 벤치마크에서 MMLU 5-shot 78.1 등 우수한 기본 성능 공개 |
| 라이선스 | Apache 2.0 | Apache 2.0 |
| 모델 경로 (허깅페이스) | https://huggingface.co/Motif-Technologies/Motif-2-12.7B-Instruct/tree/main | https://huggingface.co/Motif-Technologies/Motif-2-12.7B-Base/tree/main |
주요 특징
- 한국어 특화 모델 : 국내 기업 모티프테크놀로지스에서 독자 개발한 대형언어모델로, 한국어 데이터 중심의 학습을 통해 한국어 이해와 생성 능력에서 높은 정밀도를 보여줍니다. 국내 환경과 사용 패턴을 반영해 설계되어, 한국어 질의응답·문서 요약·대화형 응답 등에서 자연스럽고 일관된 결과를 제공합니다.
- 연산 효율성과 학습 병렬화 기술 : 그룹 단위 차등 어텐션(Grouped Differential Attention, GDA) 과 뮤온 옵티마이저(Muon Optimizer) 기술을 적용해 연산 효율을 극대화했습니다. 이를 통해 동일한 연산량으로 더 높은 표현력을 확보하고, 멀티노드 환경에서 통신 병목과 동기화 지연을 최소화하여 GPU 활용률을 높였습니다.
- SFT 기반 추론 성능 : 강화학습(RL) 없이 지도학습(SFT)만으로도 고도의 추론 능력을 확보했습니다. 사용자의 질문 특성에 따라 ‘Think(깊은 사고)’와 ‘No-Think(즉시 응답)’ 모드를 자동 전환해 상황에 맞는 응답을 제공합니다.
- 우수한 벤치마크 성능 : MMLU, BBH, GSM8K 등 주요 평가에서 Gemma-3 (12B) 대비 평균 +14.48 % 향상된 결과를 기록했으며, Qwen 2.5 72B 모델을 능가하는 성능을 보여 모델 구조와 학습 효율 최적화의 우수성을 입증했습니다.
벤치마크 성능
Motif 2모델은 12.7B 규모의 한국어 중심 대형언어모델로, MMLU 78.1, GSM8K 93.9, MATH 73.6, BBH 81.3 등에서 Qwen3-14B(14B) 와 대등하거나 일부 항목에서는 상회하는 성능을 보여주었습니다. 특히 수학적 추론(GSM8K, MATH)에서 매우 높은 수치를 기록하며, 동급 모델 대비 효율적인 구조와 학습 품질을 입증했습니다. 또한 Gemma-3-12B 대비 전 항목에서 뚜렷한 우위를 보여, 한국어 기반 LLM 중 가장 완성도 높은 수준의 범용 추론 성능을 확보한 모델로 평가됩니다.
[Motif-2-12.7B-Base 벤치마크]
| Benchmark | Evaluation setting | Motif-2-12.7B | Qwen3-14B | Gemma-3-12B |
| MMLU | 5-shot | 78.1 | 81.05 | 74.5 |
| BBH | 3-shot (CoT) | 81.3 | 81.07 | – |
| GSM8K | 4-shot (CoT) | 93.9 | 92.49 | – |
| MATH | 4-shot (CoT) | 73.6 | 62.02 | 43.3 |
| HumanEval | 0-shot | 65.9 | – | 45.7 |
| BoolQ | 0-shot | 78.5 | – | 78.8 |
| ARC-C | 25-shot | 69.6 | – | 68.9 |
| ARC-E | 0-shot | 84.1 | – | 88.3 |
| Winogrande | 5-shot | 79.6 | – | 74.3 |
출처 : Motif-2-12.7B-Base 허깅페이스
- MMLU : 다양한 학문 분야(역사, 수학, 생물 등)에 대한 지식 이해력을 평가하는 벤치마크로, 모델의 종합적 지식 수준과 언어 이해 능력을 측정합니다.
- BBH : Big-Bench Hard의 약자로, 추론·논리 문제 중심의 난이도 높은 과제를 다루며 모델의 복합적 사고력과 문제 해결 능력을 평가합니다.
- GSM8K : 초등 수준의 수학 문장 문제 데이터셋으로, 단계적 논리 전개와 수학적 계산 능력을 측정하는 대표적인 추론 평가 항목입니다.
- MATH : 고등 수준의 수학 문제를 다루는 벤치마크로, 복잡한 계산과 수학적 개념 이해 능력을 평가합니다.
- HumanEval : 파이썬 프로그래밍 문제를 통해 코드 생성과 논리적 구현 능력을 평가하며, 모델의 실질적인 코딩 지능을 확인합니다.
- BoolQ : “참(True)/거짓(False)” 형태의 질문으로 구성된 벤치마크로, 지문 이해력과 사실 판단 정확도를 평가합니다.
- ARC-C : 과학·상식 중심의 복합 선택형 문제로 구성되어 있으며, 추론력과 과학적 사고 기반의 문제 해결 능력을 측정합니다.
- ARC-E : ARC의 쉬운 버전(Easy)으로, 일반 상식과 언어적 논리 판단 능력을 평가합니다.
- Winogrande : 문맥상 올바른 단어를 선택하는 테스트로, 상황 이해와 언어 추론 능력을 평가하여 모델의 문맥 이해 수준을 파악합니다.
라이선스
Motif 2 모델은 Apache License 2.0 하에 공개되어 있습니다. 이 라이선스는 상업적·비상업적 목적 모두에서 자유롭게 모델을 사용, 수정, 배포할 수 있도록 허용하는 가장 개방적인 오픈소스 라이선스 중 하나입니다.
단, 다음과 같은 기본 조건을 준수해야 합니다.
- 원저작자의 저작권 및 라이선스 고지문을 명시해야 합니다.
- 모델을 수정하거나 재배포할 경우, 변경 사항을 명확히 표시해야 합니다.
- 상표권, 특허권, 서비스 마크 등은 별도의 허가 없이 사용할 수 없습니다.
즉, Apache 2.0 라이선스는 개발자와 기업이 모델을 기반으로 자체 서비스나 응용 모델을 제작·상용화할 수 있는 자유를 보장하면서도, 원저작자의 권리와 투명성을 유지하도록 설계된 안정적이고 신뢰도 높은 오픈소스 라이선스 체계입니다.
간단한 사용 예시
Motif 2 모델은 현재 모티프테크놀로지스 공식 웹 플랫폼과 허깅페이스 양쪽에서 모두 이용할 수 있습니다. 사용자는 별도의 복잡한 설정 없이 웹 환경에서 바로 모델을 체험하거나, 모델 파일을 직접 다운로드하여 로컬 환경에서 실행할 수도 있습니다.
[웹 플랫폼]
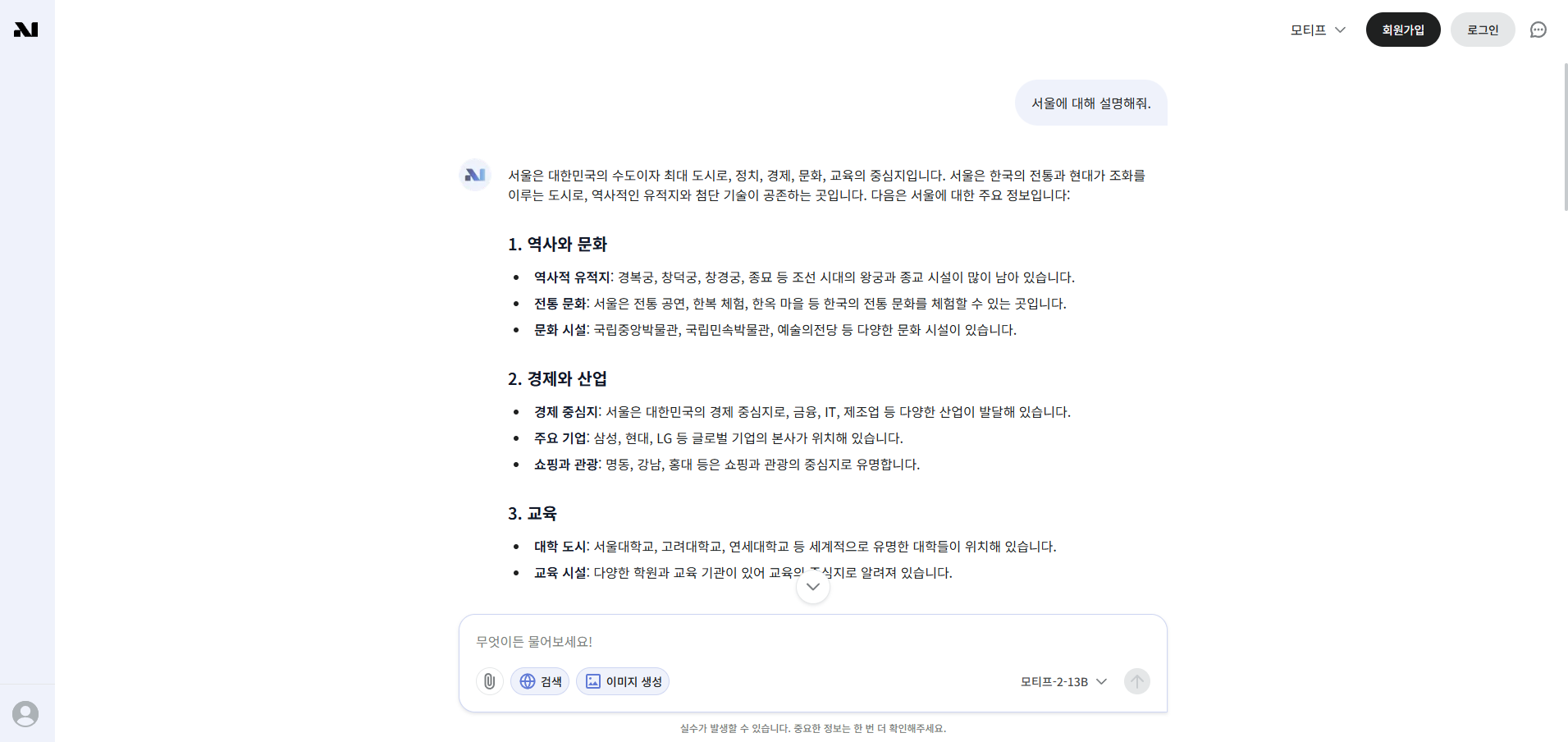
모티프테크놀로지스의 공식 웹 플랫폼에서는 회원가입 없이 Motif 2 모델을 체험할 수 있습니다. 프롬프트를 입력하면 모델이 즉시 응답을 생성하며, 기본적인 대화 기능뿐 아니라 웹 검색과 이미지 생성 등 기능도 제공됩니다. 이를 통해 단순한 대화형 모델을 넘어 정보 탐색, 콘텐츠 생성, 시각적 결과 표현까지 한 번에 수행할 수 있습니다. 사용자는 설치나 로그인 과정 없이 접속만으로 Motif 2의 성능과 활용 가능성을 손쉽게 확인할 수 있습니다.
- 모티프테크놀로지스 웹 플랫폼 : https://chat.motiftech.io/
[로컬 실행]
허깅페이스 모델 페이지에서는 Motif 2의 두 가지 버전(Base / Instruct) 이 모두 공개되어 있습니다. 이 중 Motif-2-12.7B-Instruct는 사용자 지시에 맞춰 세밀하게 조정된 인스트럭트형 모델로, 로컬 환경에서 직접 실행하여 대화형 응답 생성이나 지시문 기반 작업 처리를 수행할 수 있습니다. 이 모델은 GPU 연산 효율을 극대화하기 위해 Flash Attention이라는 고성능 어텐션 가속 라이브러리를 사용하며, 해당 라이브러리는 리눅스(Ubuntu) 환경에 최적화되어 있습니다.
아래는 로컬 환경에서 Motif 2 모델을 직접 다운로드하고 실행하는 기본 예시입니다.
1. 실행 환경
2. Motif-2-12.7B-Instruct 모델 및 패키지 설치
3. 코드 작성
4. 실행
1. 실행 환경
- 운영체제 : Ubuntu (리눅스)
- Python : 3.10.19
- CUDA : 12.1
- torch : 2.3.1 + cu121
- transformers : 4.57.1
- flash-attn : 2.8.3
2. Motif-2-12.7B-Instruct 모델 및 패키지 설치
Motif-2-12.7B-Instruct 모델은 아래 모티프 테크놀로지 허깅페이스에서 다운로드할 수 있습니다.
아래 명령어를 통해 해당 모델을 실행하는데 필요한 패키지를 모두 설치해줍니다.
# 패키기 설치
pip install torch==2.8.0 torchvision==0.23.0 --index-url https://download.pytorch.org/whl/cu126
pip install transformers psutil accelerate flash_attn
3. 코드 작성
아래 작성된 코드는 공식 예제를 참고하여 작성되었습니다.
# Python
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
model_load = "/Path/to/Motif-2-12.7B-Instruct" # 사용자 환경에 맞게 수정
model = AutoModelForCausalLM.from_pretrained(
model_load,
trust_remote_code = True,
_attn_implementation = "flash_attention_2",
dtype = torch.bfloat16,
device_map="auto",
offload_buffers=True,
)
tokenizer = AutoTokenizer.from_pretrained(
model_load,
trust_remote_code = True,
)
query = "서울에 대해 간단히 설명해줘. 대상은 외국인 관광객이야." # 사용자 환경에 맞게 수정
input_ids = tokenizer.apply_chat_template(
[
{'role': 'system', 'content': 'you are an helpful assistant'},
{'role': 'user', 'content': query},
],
add_generation_prompt = True,
enable_thinking = False, # or True
return_tensors='pt',
).to(model.device)
output = model.generate(input_ids, max_new_tokens=256, pad_token_id=tokenizer.eos_token_id)
output = tokenizer.decode(output[0, input_ids.shape[-1]:], skip_special_tokens = False)
print(output)
4. 실행
Motif-2-12.7B-Instruct 모델은 16GB 이상의 VRAM이 필요하며, 실제 실행 과정에서는 VRAM이 초과되어 일부 연산이 CPU로 오프로딩되었습니다. 이로 인해 처리 속도가 크게 저하되어, 약 256 토큰의 간단한 출력에도 10분가량이 소요되었습니다. 출력된 문장은 한국어 문법과 표현이 자연스럽고 일관성이 있었으나, 전체적인 성능 평가는 PC 사양 한계로 인해 정확히 검증하기 어려웠습니다.
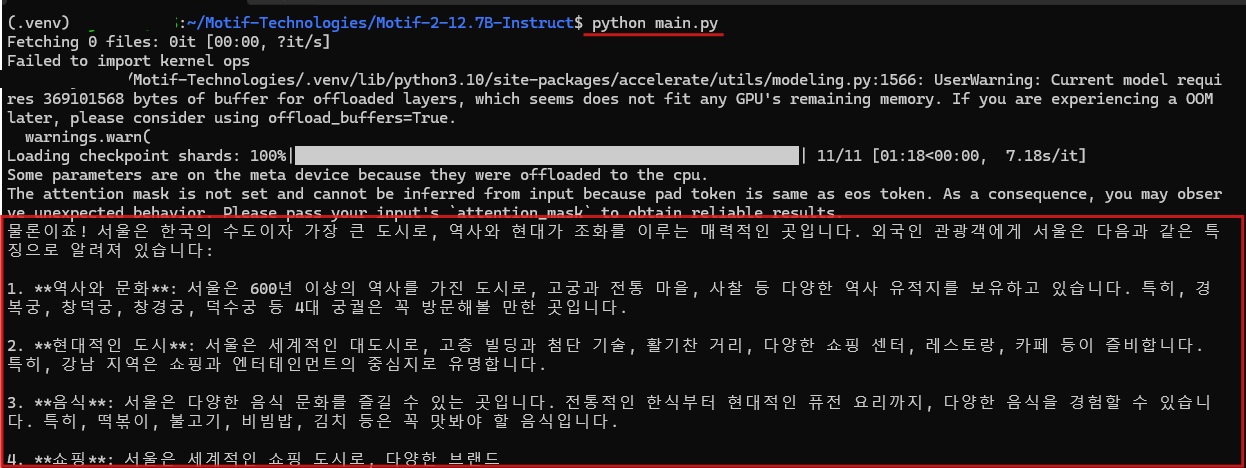
Motif 2 모델은 국내 기업 모티프테크놀로지스가 독자적으로 개발한 대형 언어 모델로, 한국어 중심의 문장 이해와 생성 능력이 돋보입니다. 다만, 테스트 환경의 성능 제약으로 인해 모델의 실제 처리 속도와 응답 품질을 온전히 확인하지 못한 점은 아쉬움으로 남습니다.
앞으로 Motif와 같은 한국어 특화 모델들이 지속적으로 등장해, 국내 언어 데이터에 최적화된 AI 기술이 더욱 발전하길 기대합니다. 이러한 시도들은 한국어 AI 생태계의 자립성과 기술 경쟁력을 강화하는 중요한 출발점이 될 것입니다.
감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [오픈소스 AI] ChronoEdit, NVIDIA가 선보인 최신 이미지 수정 모델 (0) | 2025.11.06 |
|---|---|
| [오픈소스 AI] 최고 성능의 OCR 모델, Chandra-OCR를 소개합니다. (1) | 2025.11.03 |
| [오픈소스 AI] 중국 MiniMax의 초거대 언어모델, MiniMax-M2를 소개합니다. (1) | 2025.10.31 |
| [오픈소스 AI] 1GB 미만의 초소형 비전-언어 모델, LFM2-VL을 소개합니다. (0) | 2025.10.30 |
| [오픈소스 AI] DeepSeek에서 공개한 이미지를 인식하는 AI 모델, DeepSeek-OCR을 소개합니다. (1) | 2025.10.24 |



