안녕하세요,
최근 인공지능 분야에서는 문서 인식(OCR) 기술이 빠르게 발전하며, 단순한 텍스트 추출을 넘어 문서의 구조와 의미까지 이해하는 지능형 인식 모델들이 등장하고 있습니다. 특히 Deepseek에서 공개한 OCR 모델을 능가하는 성능을 갖춘 차세대 LLM 기반 OCR 모델, Chandra-OCR이 새롭게 공개되어 주목받고 있습니다.
이번 포스팅에서는 Chandra-OCR 모델의 주요 특징과 성능, 그리고 실제 테스트 결과를 중심으로 이 모델이 기존 OCR 기술과 어떤 차별성을 가지고 있는지 자세히 살펴보겠습니다.
Chandra-OCR 란
2025년 10월, DataLab-TO에서 LLM 기반 OCR(광학 문자 인식) 모델인 Chandra-OCR을 공개하였습니다. 이 모델은 이미지나 PDF 형식의 문서를 입력받아, 원본의 레이아웃 정보를 최대한 보존한 상태로 HTML, Markdown, JSON 등과 같은 구조화된 형식으로 변환하도록 설계되었습니다. 특히 복잡한 표나 양식, 손글씨가 포함된 문서를 정밀하게 처리할 수 있으며, 40개 이상의 다국어를 지원하는 것이 주요 특징입니다.
- Chandra-OCR 깃허브 : https://github.com/datalab-to/chandra
GitHub - datalab-to/chandra: OCR model that handles complex tables, forms, handwriting with full layout.
OCR model that handles complex tables, forms, handwriting with full layout. - datalab-to/chandra
github.com
[모델 정보 요약]
| 항목 | Chandra-OCR 모델 |
| 파라미터 수 | 9B |
| 개발사 | Datalab.to |
| 아키텍처 | LLM 기반 Vision-Language 구조 (문서 이해 + OCR + Layout 분석 통합) |
| 학습 프레임워크 | PyTorch + Flash Attention 2 + vLLM |
| 특징 | - 이미지·PDF 기반 문서 인식 및 레이아웃 분석 지원 - LLM을 활용한 문맥 재구성 및 Markdown/HTML 변환 - 표, 수식, 필기체, 헤더/푸터 등 복잡한 문서 처리 가능 - 로컬(--method hf)·원격(--method vllm) 모드 모두 지원 |
| 라이선스 | Apache 2.0 / OpenRAIL-M (모델 가중치) |
| 모델 경로 (허깅페이스) | https://huggingface.co/datalab-to/chandra |
주요 특징
- 이아웃 보존 출력 : 입력 문서의 구조(표, 컬럼 구분, 머리말·바닥글 등)를 최대한 유지하면서 HTML, Markdown, JSON 등의 형식으로 변환할 수 있습니다.
- 양식 및 체크박스 인식 : 체크박스나 입력란이 포함된 양식 문서도 정확히 인식하여 구조를 복원할 수 있습니다.
- 복잡한 표 처리 : 다단 구성, 표, 수식 등 복잡한 레이아웃을 가진 문서도 정밀하게 분석하고 변환할 수 있습니다.
- 손글씨 인식 지원 : 인쇄된 텍스트뿐만 아니라 손글씨 형태의 문자도 인식할 수 있습니다.
- 다국어 지원 : 40개 이상의 언어를 인식할 수 있어, 다양한 언어권 문서에 대응할 수 있습니다.
- 두 가지 추론 모드 제공 : 로컬 환경(HuggingFace 기반)과 원격 서버(vLLM 기반) 중 선택하여 사용할 수 있습니다.
- 우수한 벤치마크 성능 : 자체 평가에서 종합 점수(Overall) 83.1 수준의 높은 정확도를 기록하였습니다.
벤치마크 성능
Chandra-OCR 모델은 공개된 벤치마크에서 Overall Score 83.1점을 기록하며, 동종 OCR 모델 중 가장 높은 성능을 보였습니다. 이 점수는 표 인식, 문서 레이아웃 보존, 다국어 인식 정확도 등 다양한 항목을 종합한 결과이며, Deepseek OCR, Mistral OCR, GPT-4o Anchored, Gemini Flash 2 등의 경쟁 모델을 모두 상회하는 성능입니다. 특히 DataLab 자체 모델(Maker 시리즈 및 olmOCR)을 포함한 비교군에서도 가장 높은 점수를 기록하여, 구조적 문서 분석과 복잡한 레이아웃 복원 측면에서 우수한 결과를 입증하였습니다.

라이선스
Chandra-OCR 모델은 현재 OpenRAIL 라이선스를 기반으로 공개되었습니다. 이 라이선스는 인공지능 모델의 책임 있는 활용과 공정한 재배포를 목적으로 하며, 연구 및 비상업적 사용 범위 내에서는 자유롭게 이용할 수 있습니다.
다만, 안전하고 윤리적인 사용을 보장하기 위해 다음과 같은 제한 사항이 명시되어 있습니다.
- 악용 금지 : 허위 정보 생성, 불법 행위, 프라이버시 침해, 차별적 목적 등의 사용 금지
- 재배포 시 고지 의무 : 모델을 재배포하거나 파생 모델을 공개할 경우, 동일한 OpenRAIL 조건을 명시해야 함
- 상업적 이용 시 승인 필요 : 특정 형태의 상업적 서비스에 모델을 직접 활용하려면 별도의 사용 허가 또는 계약이 필요함
이와 같은 라이선스 정책은 Chandra-OCR 모델이 개방성과 책임성을 동시에 지닌 AI 생태계 내에서 활용될 수 있도록 설계된 것입니다.
간단한 사용 예시
Chandra-OCR 모델은 이미지나 PDF 문서를 입력받아, 레이아웃을 유지한 상태로 텍스트를 구조화하여 반환하도록 설계되었습니다. 로컬 환경에서 간단히 모델을 직접 실행하는 방법에 대해 알아보겠습니다.
1. 실행 환경
2. Chandra-OCR 모델 및 패키지 설치
3. 코드 작성
4. 실행
1. 실행 환경
- 운영체제 : Window 11
- Python : 3.10.11
- torch : 2.8.0 + cu126
- transformers : 4.57.1
- chandra-ocr : 0.1.8
2. Chandra-OCR 모델 및 패키지 설치
Chandra-OCR 모델은 아래 Datalab-To 허깅페이스에서 다운로드할 수 있습니다.
- Datalab-To 허깅페이스 : https://huggingface.co/datalab-to/chandra/tree/main
아래 명령어를 통해 해당 모델을 실행하는데 필요한 패키지를 모두 설치해줍니다.
# 패키기 설치
pip install chandra-ocr==0.1.8
pip install torch==2.8.0 torchvision==0.23.0 --index-url https://download.pytorch.org/whl/cu126
3. 코드 작성
아래 작성된 코드는 공식 예제를 참고하여 작성되었습니다.
# Python
from transformers import AutoModelForImageTextToText, AutoProcessor
from chandra.model.hf import generate_hf
from chandra.model.schema import BatchInputItem
from chandra.output import parse_markdown
from PIL import Image
import torch
# 1. 모델 불러오기
model = AutoModelForImageTextToText.from_pretrained(
"Path/to/chandra", # 사용자 환경에 맞게 수정
dtype=torch.bfloat16,
device_map="auto",
)
model.processor = AutoProcessor.from_pretrained("Path/to/chandra") # 사용자 환경에 맞게 수정
# 2. 이미지 로드
image = Image.open("Path/to/image.png") # 사용자 환경에 맞게 수정
batch = [
BatchInputItem(
image=image,
prompt_type="ocr_layout"
)
]
# 3. 추론
model.eval()
with torch.no_grad():
result = generate_hf(batch, model)[0]
# 4. 결과 파싱
markdown = parse_markdown(result.raw)
# 5. 출력
print(markdown)
4. 실행
이제 Chandra-OCR 모델을 활용하여 실제 테스트를 진행하였습니다. 아래는 테스트에 사용한 입력 이미지와 그 결과에 대한 요약입니다.


[성능 및 실행 정보]
- GPU 메모리 사용량(VRAM) : 약 15.7GB
- 처리 속도 : 이미지의 복잡도 및 텍스트 밀도에 따라 달라짐
| 테스트 항목 | 처리 시간 |
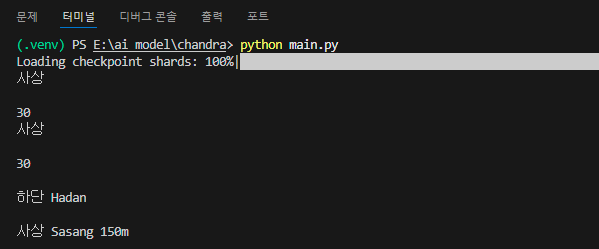
| 첫 번째 이미지 (간단한 표지판) | 약 2분 |
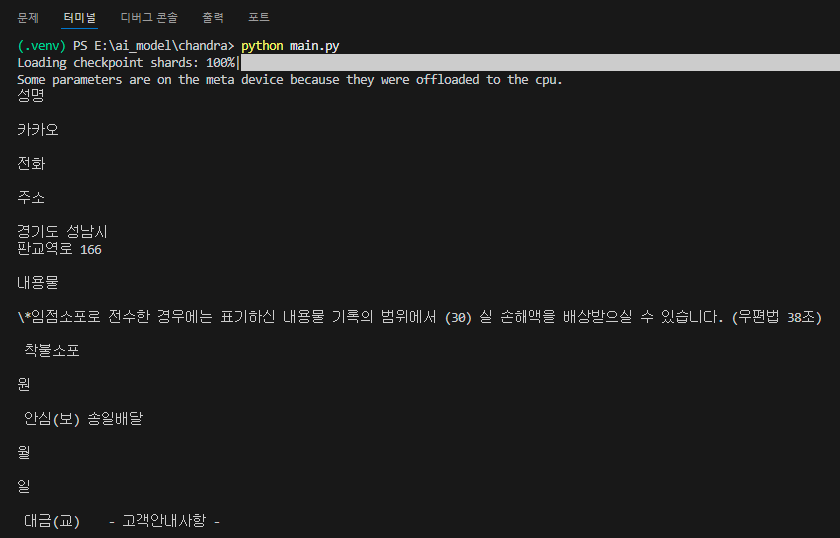
| 두 번째 이미지 (택배 송장) | 약 13분 |
공식 예제를 그대로 실행할 경우 VRAM 사용량이 32GB 이상으로 크게 증가하였기 때문에, 이번 테스트에서는 메모리 사용 효율을 높이는 방향으로 코드 구조를 일부 수정하였습니다. 이 과정에서 추론 속도는 다소 느려졌지만, 상대적으로 적은 VRAM으로 모델을 안정적으로 실행할 수 있었습니다.
모델은 테스트 이미지에서 한글 텍스트도 문제없이 인식하였으며, 간단한 이미지의 경우에도 결과가 출력되기까지 약 2분이 소요되었습니다. 속도는 다소 느렸지만 정확도는 매우 우수한 수준을 보였으며, 전반적인 글자 인식률 또한 높은 수준을 유지하였습니다.
특히 두 번째 테스트에 사용된 택배 송장 이미지의 경우, 글씨 크기가 작고 일부 영역이 흐릿했음에도 불구하고 모델이 대부분의 문자를 정확하게 인식하였습니다. 일부 글자에서 미세한 인식 오류가 있었지만, 전체적인 인식 정확도는 여전히 매우 우수했으며, 아래 결과를 통해 그 성능을 직접 확인할 수 있습니다.

Chandra-OCR 모델과 같은 인공지능 기술의 발전은 단순히 문서를 인식하고 분석하는 수준을 넘어, 인간의 정보 접근 방식과 업무 효율성 전반을 새롭게 변화시키고 있습니다. 복잡한 문서 구조나 다국어 환경에서도 높은 정확도를 보여주는 이러한 모델들은, 사람이 직접 수행하기 어려웠던 반복적이고 정밀한 작업을 대신 처리함으로써 시간과 자원의 낭비를 줄이고, 더 창의적이고 가치 있는 일에 집중할 수 있는 환경을 만들어주고 있습니다.
앞으로도 AI 기술이 지속적으로 발전함에 따라, 우리의 삶은 더욱 편리하고 효율적으로 변화할 것입니다. Chandra-OCR 모델의 사례는 그 가능성을 보여주는 대표적인 예이며, AI가 인간의 한계를 보완하고 새로운 기회를 여는 긍정적인 방향으로 발전하고 있음을 상징하는 의미 있는 전환점이라 할 수 있습니다.
감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [한국어 AI 모델] 모티프 테크놀로지 Motif 2 특징과 간단한 사용 가이드 | 로컬환경 | 오픈소스 AI (0) | 2025.11.07 |
|---|---|
| [오픈소스 AI] ChronoEdit, NVIDIA가 선보인 최신 이미지 수정 모델 (0) | 2025.11.06 |
| [오픈소스 AI] 중국 MiniMax의 초거대 언어모델, MiniMax-M2를 소개합니다. (1) | 2025.10.31 |
| [오픈소스 AI] 1GB 미만의 초소형 비전-언어 모델, LFM2-VL을 소개합니다. (0) | 2025.10.30 |
| [오픈소스 AI] DeepSeek에서 공개한 이미지를 인식하는 AI 모델, DeepSeek-OCR을 소개합니다. (1) | 2025.10.24 |



