안녕하세요,
우리나라 기업, 카카오에서 텍스트와 이미지를 동시에 이해할 수 있는 경량 멀티모달 언어모델, Kanana-1.5-v-3b를 공개했습니다. 이 모델은 약 36억 개의 파라미터를 기반으로 설계되어, 한국어와 영어 모두에 대응하며, 이미지 속 텍스트까지 정확하게 분석할 수 있는 기능을 갖추고 있습니다.
이번 포스팅에서는 Kanana-1.5-v-3b의 핵심 기능과 실제 로컬 환경에서의 실행 결과를 중심으로, 한국어 이미지 인식 정확도, 응답 속도, VRAM 사용량 등을 직접 검증해 본 내용을 소개합니다. 국산 멀티모달 모델의 실용성을 확인하고자 하시는 분들께 유용한 정보가 될 수 있습니다.
Kanana-1.5-v-3b 란
2025년 7월 24일, 카카오는 자사의 독자 기술로 개발한 경량형 멀티모달 언어모델 Kanana-1.5-v-3b를 공식 공개했습니다. 이 모델은 텍스트뿐만 아니라 이미지 입력까지 동시에 처리할 수 있도록 설계된 것이 특징이며, 다양한 형태의 정보를 종합적으로 이해하고 응답할 수 있는 능력을 갖추고 있습니다. 약 36억 개의 파라미터를 기반으로 학습된 이 모델은 경량 구조임에도 불구하고 강력한 언어 처리 능력을 발휘하며, 한국어와 영어를 모두 자연스럽게 처리할 수 있는 이중 언어 지원 기능을 제공합니다. 특히 Kakao의 자체 기술로 From Scratch 방식으로 개발되었기 때문에, 한국어 환경에 최적화된 멀티모달 성능을 기대할 수 있습니다.
- 카카오 공식 블로그 : https://tech.kakao.com/posts/714
카카오의 경량 멀티모달 언어모델 ‘Kanana-1.5-v-3b’ 개발부터 공개까지 - tech.kakao.com
카카오의 멀티모달 언어모델 ‘Kanana-v’의 개발과 오픈소스 공개 소식을 공유...
tech.kakao.com
주요 특징
- 멀티모달 이해력 : 이미지·텍스트 혼합 입력을 자연스럽게 처리 가능 (사진 기반 장소 추론 가능)
- 다양한 활용 가능성 : 이미지·글자 인식, 동화 및 시 창작, 문화유산‧관광지 해설, 도표 분석, 수학 문제 풀이 등 광범위하게 활용 가능
- 경량형이지만 고성능 : 파라미터 수 대비 뛰어난 컴퓨팅 효율성, 모바일·IoT 환경에서도 배포 가능한 최적화 구조
- 강화된 지시 수행 능력 : 한국어·영어 혼합 문장에 대한 지시 이행 정확도가 우수
벤치마크 성능
Kanana‑1.5‑v‑3b는 다양한 멀티모달 태스크에서 동급 모델 중 가장 뛰어난 성능을 기록하였습니다. 약 3~4B 파라미터 규모의 멀티모달 모델들과 비교한 결과, 모든 항목에서 우수한 결과를 보여주었습니다.
- 전체 평균 점수 기준으로 Kanana‑1.5‑v‑3b는 경쟁 모델들을 앞서며 가장 높은 점수를 기록하였습니다.
- 영어 이미지 이해 부문에서는 Qwen2.5-VL-3B-Instruct 및 InternVL2.5-4B와 유사한 수준의 우수한 성능을 나타냈습니다.
- 한국어 이미지 이해에서는 타 모델 대비 현격히 높은 점수를 기록하며, 한국어 멀티모달 처리에 특화된 성능을 입증하였습니다.
- 특히 영어/한국어 멀티모달 지시 이행(Multimodal Instruction Following) 항목에서, Kanana‑1.5‑v‑3b는 모든 모델을 압도하며 최고 점수를 기록하였습니다. 이는 이미지와 텍스트가 혼합된 복잡한 지시를 정확하게 이해하고 수행하는 능력이 탁월함을 의미합니다.

라이선스
Kanana-1.5-v-3b는 카카오에서 공개한 모델로, Kanana License Agreement에 따라 사용할 수 있습니다. 비상업적 연구 및 자체 서비스 개발에는 자유롭게 사용할 수 있으며, 출력물에 대한 권리는 사용자에게 있습니다.
다만, API 제공, 클라우드 기반 서비스, 온프레미스 판매 등 상업적 활용에는 카카오의 별도 상업 라이선스가 필요합니다. 월간 활성 사용자 수가 1천만 명을 초과하는 경우에도 상업 라이선스 계약이 요구됩니다. 모델을 재배포하거나 파생 모델을 공개할 경우, 'Powered by Kanana' 문구와 함께 라이선스 고지문을 명시해야 합니다.
모델 실행 가이드
카카오 허깅페이스에서 공개된 모델과 데이터를 활용하여 로컬환경에서 간단한 사용 테스트를 진행해보겠습니다.
[실행 환경]
- 운영체제 : Windows 11
- python : 3.10.11
- torch : 2.7.1
- transformers : 4.53.3
- accelerate : 1.9.0
- GPU : NVIDIA GeForce RTX 4060 Ti
[모델 다운로드]
아래 카카오 허깅페이스에서 kanana-1.5-v-3b-instruct 모델을 다운로드하실 수 있습니다. 아래 이미지에 표시된 파일을 모두 다운로드하여 동일한 디렉토리에 저장합니다.

[패키지 설치]
아래 명령어를 통해 해당 모델을 실행하는 데 필요한 패키지를 설치합니다.
# Windows PowerShell
pip install transformers accelerate timm omegaconf einops
pip install torch==2.6.0 torchvision==0.21.0 --index-url https://download.pytorch.org/whl/cu126
[코드 작성]
필요한 패키지 설치가 완료되면, 아래와 같이 모델을 실행하기 위한 코드를 작성합니다.
from PIL import Image
import torch
from transformers import AutoModelForVision2Seq, AutoProcessor
MODEL = "Path/to/kanana-1.5-v-3b-instruct" # kanana-1.5-v-3b 모델 경로 (사용자 환경에 맞게 수정)
model = AutoModelForVision2Seq.from_pretrained(
MODEL,
torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
model.eval()
# Load processor
processor = AutoProcessor.from_pretrained(MODEL, trust_remote_code=True)
# Prepare input batch
batch = []
for _ in range(1): # dummy loop to demonstrate batch processing
image_files = [
"Path/to/kanana-1.5-v-3b-instruct/examples/waybill.png" # 예시 이미지 (사용자 환경에 맞게 수정)
]
sample = {
"image": [Image.open(image_file_path).convert("RGB") for image_file_path in image_files],
"conv": [
{"role": "system", "content": "The following is a conversation between a curious human and AI assistant."},
{"role": "user", "content": " ".join(["<image>"] * len(image_files))},
{"role": "user", "content": "사진에서 보내는 사람과 받는 사람 정보를 json 형태로 정리해줘."}, # 입력 프롬프트
]
}
batch.append(sample)
inputs = processor.batch_encode_collate(
batch, padding_side="left", add_generation_prompt=True, max_length=8192
)
inputs = {k: v.to(model.device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
# Set the generation config
gen_kwargs = {
"max_new_tokens": 2048,
"temperature": 0,
"top_p": 1.0,
"num_beams": 1,
"do_sample": False,
}
# Generate text
gens = model.generate(
**inputs,
**gen_kwargs,
)
text_outputs = processor.tokenizer.batch_decode(gens, skip_special_tokens=True)
print(text_outputs)
[실행 결과]
Kanana-1.5-v-3b-instruct 모델을 로컬 환경에서 직접 실행해 본 결과, 경량 모델임에도 불구하고 전반적으로 빠르고 안정적인 응답 성능을 보여주었습니다. 특히 이 모델은 비전 인식이 가능한 멀티모달 모델로, 이미지 속 한국어 텍스트를 높은 정확도로 인식하는 것이 인상적이었습니다. 실험은 허깅페이스에서 제공하는 샘플 이미지 외에도, 별도로 준비한 한국어 표지판 이미지를 활용하여 진행하였습니다. 실질적인 테스트 시, 이미지에 대한 질문을 입력한 후 응답을 받아오는 데 약 5~8초 내외의 처리 시간이 소요되었으며, 이 과정에서 약 8.7GB의 VRAM이 사용되었습니다.
모델은 입력한 프롬프트를 정확히 이해하고, 의도에 부합하는 응답을 안정적으로 생성하였습니다. 특히 이미지 내 한글 텍스트를 정확히 식별하고, 해당 정보를 바탕으로 자연스럽고 구조화된 응답을 제공하는 점에서 높은 완성도를 확인할 수 있었습니다.
아래는 테스트에 사용된 두 가지 프롬프트와 그에 따른 응답 예시입니다.
- 첫 번째 프롬프트: "사진에서 보내는 사람과 받는 사람 정보를 json 형태로 정리해줘."
- 두 번째 프롬프트: 사진 정보를 설명해줘."


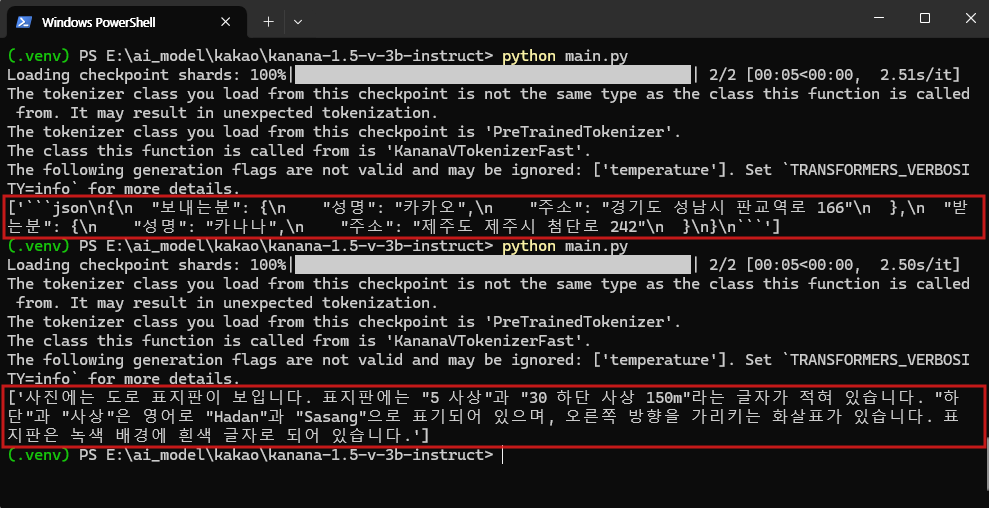
이와 같이 Kanana-1.5-v-3b-instruct는 경량 구조임에도 불구하고 이미지 인식과 지시 이행 능력에서 매우 우수한 성능을 보여주었습니다. 특히 한국어 이미지 처리에 강점을 보이며, 멀티모달 입력에 대한 안정적인 응답 속도와 정확도를 바탕으로 실사용 가능성을 충분히 입증하였습니다.
앞으로 다양한 입력 유형과 실제 서비스 환경에서의 테스트를 통해 활용 범위를 더욱 넓혀갈 수 있을 것으로 기대됩니다. 경량 멀티모달 모델을 찾고 있는 사용자에게 매우 유용한 대안이 될 수 있습니다.
감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [오픈소스AI] NC소프트의 한국형 AI, VARCO‑VISION 2.0 모델을 소개합니다. (5) | 2025.07.30 |
|---|---|
| 네이버 HyperCLOVA X SEED 14B Think 오픈소스 공개 | 한국형 AI | KLLM | (1) | 2025.07.29 |
| 코난테크놀로지의 한국형 AI, Konan-LLM-OND 로컬 실행기 | 한국형 AI | KLLM (2) | 2025.07.24 |
| 애플이 공개한 디퓨전 기반 LLM, DiffuCoder 모델 소개 및 사용법 (4) | 2025.07.23 |
| 엔비디아 오디오 AI 모델 공개 - Audio Flamingo 3와 Canary-Qwen-2.5B 비교 | 오픈소스 AI | 오디오 AI (4) | 2025.07.22 |



