안녕하세요,
최근 들어 많은 테크 기업들이 AI 모델 개발에 적극적으로 투자하고 있으며, 그 중에서도 애플은 새로운 접근 방식을 적용한 dLLM(diffusion Language Model)을 공개하여 주목받고 있습니다. 이 모델은 기존의 LLM과는 다른 구조를 기반으로 작동하며, 정확도와 대규모 데이터 처리 측면에서 뛰어난 성능을 보이는 것으로 알려져 있습니다.
이번 포스팅에서는 애플이 공개한 DiffuCoder 모델에 대해 살펴보고, 간단한 사용 예시를 통해 실제로 어떻게 활용할 수 있는지도 함께 알아보겠습니다.
DiffuCoder란
DiffuCoder는 Apple에서 공개한 오픈소스 코드 생성 모델이며, Masked Diffusion Model(MDM)을 기반으로 한 대형 언어 모델입니다. DiffuCoder는 diffusion 방식의 장점을 언어 모델에 접목한 새로운 유형의 LLM으로, 이러한 계열을 종합적으로 dLLM(diffusion Language Model)이라고 부릅니다. dLLM은 생성 과정을 반복적인 디노이징 단계로 구성함으로써, 기존 언어 모델보다 더 유연하고 구조적인 생성이 가능하다는 특성을 가집니다.
GitHub - apple/ml-diffucoder: DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation - apple/ml-diffucoder
github.com
기존 LLM과 DiffuCoder의 차이점
기존의 LLM은 대부분 Autoregressive 방식을 따릅니다. 이는 문장이나 코드와 같은 시퀀스를 생성할 때, 가장 처음 토큰부터 시작하여 왼쪽에서 오른쪽으로 순차적으로 다음 토큰을 하나씩 예측하며 생성하는 방식입니다. 예를 들어 첫 번째 단어를 예측한 후, 이를 기반으로 두 번째 단어를 예측하고, 그 결과를 바탕으로 세 번째 단어를 생성하는 식으로 이어집니다. 이처럼 생성된 결과는 앞선 예측에 전적으로 의존하게 되며, 초기에 잘못 예측된 토큰이 이후 전체 결과에 영향을 미치는 문제가 존재합니다.
반면, DiffuCoder는 이러한 Autoregressive 구조와는 전혀 다른 디퓨전(diffusion) 기반 생성 방식을 따릅니다. 이 방식은 전체 시퀀스를 무작위한 노이즈 상태로 초기화한 뒤, 여러 단계에 걸쳐 점진적으로 디노이즈하며 최종적인 문장이나 코드를 복원하는 방식으로 작동합니다. 즉, 생성 과정을 단일 방향이 아닌 전역적인 관점에서 반복적으로 다듬어 나가는 형태이며, 한 번에 전체 구조를 고려하면서 더 일관되고 완성도 높은 출력을 생성할 수 있는 특징이 있습니다. 이를 통해 초기 실수가 전체 결과에 미치는 영향을 줄이고, 복잡한 코드 구조도 보다 자연스럽게 생성할 수 있도록 설계되어 있습니다.
주요 특징
- 전체 코드 구조를 고려한 생성 : 코드 전체를 한 번에 보고, 여러 단계에 걸쳐 점점 다듬어가는 방식으로 생성합니다.
- 유연한 생성 순서 : 토큰을 정해진 순서 없이 다양한 방식으로 생성할 수 있어, 더 다양한 결과를 만들 수 있습니다.
- 성능 향상용 강화학습 적용 : Coupled-GRPO라는 기법을 사용해 코드 품질과 안정성을 높였습니다.
- 사용 가능한 모델 제공 : 다양한 버전의 모델(Base, Instruct 등)이 Hugging Face에 공개되어 있으며, PyTorch 기반으로 쉽게 실행할 수 있습니다.
라이선스
DiffuCoder 모델은 Apple Inc.의 샘플 코드 라이선스에 따라 배포되며, 해당 라이선스는 상업적 사용을 명시적으로 제한하지 않습니다. 따라서 연구, 제품 개발, 서비스 구현 등 상업적인 목적으로도 자유롭게 활용할 수 있습니다. 다만, Apple의 이름, 로고, 상표 등을 사용하는 경우에는 Apple의 사전 서면 동의가 반드시 필요합니다. 또한, 본 라이선스는 특허권을 포함하지 않으므로, 상업적 활용 시 특허와 관련된 법적 검토는 사용자 책임 하에 진행해야 합니다.
사용 방법
DiffuCoder 모델은 애플 허깅페이스에서 다양한 버전으로 공개되어 있습니다. 이번 테스트에서는 그중 DiffuCoder-7B-Instruct 모델을 활용하여 사용 방법을 살펴보겠습니다.
[모델 다운로드]
아래 허깅페이스에서 DiffuCoder-7B-Instruct 모델을 다운로드 합니다.
- 애플 허깅페이스 모델 페이지: https://huggingface.co/apple/DiffuCoder-7B-Instruct/tree/main
[패키지 설치]
아래 명령어를 통해 DiffuCoder-7B-Instruct 모델을 실행하는 데 필요한 패키지를 설치합니다.
# Windows PowerShell
pip install transformers accelerate
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
[코드 작성]
다음 코드를 작성하면 모델을 실행할 수 있습니다. 코드 내 "query" 변수에 원하는 프롬프트를 입력하여 사용할 수 있습니다.
# Python
import torch
from transformers import AutoModel, AutoTokenizer
model_path = "Path/to/DiffuCoder-7B-Instruct" # AI 모델 폴더 (사용자 환경에 맞게 수정)
model = AutoModel.from_pretrained(model_path, torch_dtype=torch.bfloat16, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = model.to("cuda").eval()
query = "Write a function to find the shared elements from the given two lists."
prompt = f"""<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
{query.strip()}
<|im_end|>
<|im_start|>assistant
""" ## following the template of qwen; you can also use apply_chat_template function
TOKEN_PER_STEP = 1 # diffusion timesteps * TOKEN_PER_STEP = total new tokens
inputs = tokenizer(prompt, return_tensors="pt")
input_ids = inputs.input_ids.to(device="cuda")
attention_mask = inputs.attention_mask.to(device="cuda")
output = model.diffusion_generate(
input_ids,
attention_mask=attention_mask,
max_new_tokens=256,
output_history=True,
return_dict_in_generate=True,
steps=256//TOKEN_PER_STEP,
temperature=0.3,
top_p=0.95,
alg="entropy",
alg_temp=0.,
)
generations = [
tokenizer.decode(g[len(p) :].tolist())
for p, g in zip(input_ids, output.sequences)
]
print(generations[0].split('<|dlm_pad|>')[0])
[실행 결과]
DiffuCoder-7B-Instruct는 프로그래밍 언어를 기반으로 학습된 모델로, 코드 생성에 특화되어 있습니다. 따라서 이번 테스트에서는 실제로 코드를 생성하는 방식으로 사용해보겠습니다. 생성할 코드는 파이썬 언어의 이진 탐색(Binary Search) 알고리즘이며, 정렬된 리스트와 탐색할 값을 입력으로 받는 구조로 요청하였습니다. 사용한 입력 프롬프트는 다음과 같습니다.
- 입력 프롬프트 : "Implement a binary search algorithm in Python. It should take a sorted list and the value to search for as input."
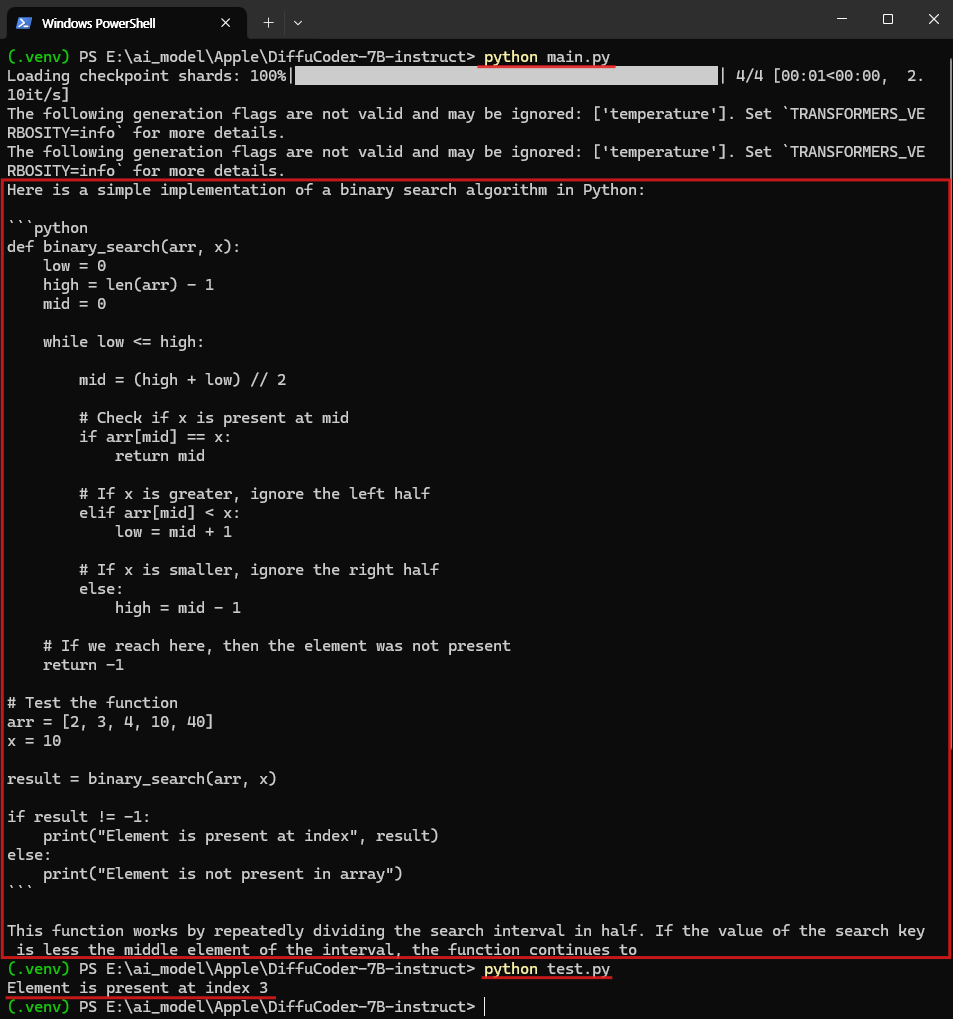
위 이미지는 main.py를 통해 DiffuCoder-7B-Instruct 모델을 실행한 결과를 보여주는 화면입니다. 모델 구동에는 약 16.1GB의 GPU VRAM이 사용되었으며, 전체 응답까지 약 1분 정도 소요되었습니다. 출력의 마지막 부분이 약간 잘리긴 했지만, 요청한 이진 탐색(Binary Search) 알고리즘은 정상적으로 생성되었습니다.
생성된 알고리즘이 제대로 동작하는지 확인하기 위해 별도의 test.py 파일로 테스트를 진행하였고, [2, 3, 4, 10, 40] 리스트에서 값 10의 위치를 정확히 index 3으로 출력하는 결과를 확인할 수 있었습니다. 이를 통해 모델이 요구한 조건에 맞는 코드를 정확히 생성했음을 알 수 있습니다.
DiffuCoder는 기존 LLM 방식의 한계를 넘어서는 dLLM(diffusion Language Model)의 가능성을 보여주는 대표적인 사례입니다. 디퓨전 기반 언어 모델은 생성 과정을 보다 유연하고 정교하게 만들어주며, 향후 다양한 분야에 응용될 수 있는 잠재력을 지니고 있습니다. 이처럼 dLLM은 단순한 기술의 변화가 아니라, AI 모델의 작동 방식 자체를 전환하는 새로운 흐름이라고 생각됩니다. 앞으로도 다양한 구조와 목적을 가진 모델들이 계속해서 개발되어, 우리의 삶을 더욱 편리하고 창의적으로 만들어주는 도구가 되기를 기대합니다.
감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| 카카오 AI, Kanana-1.5-v-3b: 이미지·텍스트 동시 이해하는 국산 모델 소개 (2) | 2025.07.25 |
|---|---|
| 코난테크놀로지의 한국형 AI, Konan-LLM-OND 로컬 실행기 | 한국형 AI | KLLM (2) | 2025.07.24 |
| 엔비디아 오디오 AI 모델 공개 - Audio Flamingo 3와 Canary-Qwen-2.5B 비교 | 오픈소스 AI | 오디오 AI (4) | 2025.07.22 |
| Kimi-K2란? Moonshot AI가 만든 초대형 오픈소스 언어 모델 정리 | 오픈소스 AI | 중국 AI 모델 | (0) | 2025.07.18 |
| LG에서 공개한 한국형 AI, EXAONE 4.0를 소개합니다. | 오픈소스 AI | 한국형 AI | 로컬 환경 (2) | 2025.07.16 |



