안녕하세요,
최근 생성형 AI 기술의 발전으로, 텍스트만 입력해도 고해상도 이미지와 영상을 손쉽게 생성할 수 있는 시대가 열렸습니다. 그중에서도 이번에 소개할 모델은 NVIDIA에서 공개한 Cosmos-Predict2로, 강력한 성능을 자랑하는 멀티모달 생성 AI입니다. Cosmos-Predict2는 로컬 환경에서도 실행이 가능하며, 적절한 GPU 사양만 갖춰진다면 누구나 직접 고품질 이미지와 영상을 생성해볼 수 있습니다.
그럼 지금부터 ComfyUI 환경에서 Cosmos-Predict2 모델을 실행하는 방법을 단계별로 살펴보겠습니다.
Cosmos-Predict2란
Cosmos-Predict2는 NVIDIA가 개발한 차세대 월드 파운데이션 모델(World Foundation Model, WFM)로, 물리 기반 AI(Physical AI)를 포함해 자율주행, 로보틱스, 산업 자동화 등 다양한 분야에서 실제 세계의 동적 상태와 상호작용을 예측하고 생성하는 데 최적화된 모델입니다.
- NVIDIA 소개페이지 : https://research.nvidia.com/labs/dir/cosmos-predict2/
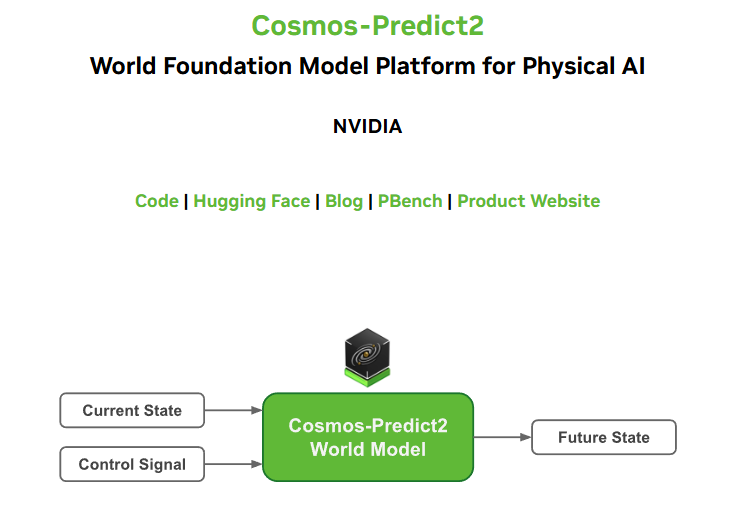
Cosmos-Predict2는 다양한 버전으로 제공되고 있습니다. 각 버전의 모델은 텍스트, 비디오, 행동 데이터 등 다양한 입력을 바탕으로 정교한 세계 예측 및 생성 능력을 제공합니다.
- Cosmos-Predict2-2B-Text2Image : 소형 2B 파라미터 모델로, 텍스트 기반 이미지 생성에 특화된 모델
- Cosmos-Predict2-14B-Text2Image : 대형 14B 파라미터 모델로, 고해상도 및 정밀한 텍스트 기반 이미지 생성에 최적화된 모델
- Cosmos-Predict2-2B-Video2World : 2B 파라미터 모델로, 비디오와 텍스트를 입력받아 미래의 시각적 세계를 생성하는 모델
- Cosmos-Predict2-14B-Video2World : 14B 파라미터 모델로, 더 정교하고 복잡한 비디오+텍스트 기반 미래 예측에 적합한 모델
- Cosmos-Predict2-14B-Sample-GR00T-Dreams-GR1 : GR00T Dreams GR1 데이터셋으로 후훈련된 14B 파라미터 모델로, 비디오+텍스트 기반 미래 세계 예측에 특화
- Cosmos-Predict2-14B-Sample-GR00T-Dreams-DROID : GR00T Dreams DROID 데이터셋으로 후훈련된 14B 파라미터 모델로, 로봇 환경에서의 미래 예측에 최적화
- Cosmos-Predict2-2B-Sample-Action-Conditioned : Bridge 데이터셋으로 후훈련된 2B 파라미터 모델로, 행동 조건을 기반으로 미래의 시각적 세계를 생성하는 데 특화
주요 특징
- 멀티모달 입력 지원 : 텍스트, 이미지, 비디오 등 다양한 형태의 입력을 받아 실제 세계의 시각적 상태(이미지, 비디오 등)로 변환할 수 있습니다.
- 현실 기반 물리적 사실성 : 생성된 결과물은 중력, 충돌, 마찰 등 실제 물리 법칙을 최대한 반영하여 자연스러운 상호작용을 구현합니다.
- 대규모 합성 데이터 생성 : 자율주행, 로보틱스 등 실제 환경에서 수집하기 어려운 복잡한 시나리오를 모사하여, 고품질의 합성 데이터를 대량 생성할 수 있습니다.
- 높은 확장성 및 빠른 처리 속도 : 최신 아키텍처를 기반으로 모델의 확장성과 연산 속도가 대폭 향상되었으며, 다양한 해상도와 프레임 속도 옵션을 유연하게 지원합니다.
라이선스
Cosmos-Predict2 모델은 상업적 용도로 자유롭게 활용할 수 있도록 허용된 오픈 모델입니다. 사용자는 해당 모델을 기반으로 다양한 연구나 제품 개발은 물론, 상업적 서비스에 통합하여 활용하는 것도 가능합니다. 또한, 이 모델은 파생 모델(Derivative Models)의 생성 및 배포를 공식적으로 허용하고 있어, 사용자가 자신의 목적에 맞게 모델을 수정하거나 확장하여 재배포하는 것도 가능합니다. Cosmos-Predict2 및 그 파생 모델을 통해 생성된 출력 결과물(예: 이미지, 영상 등)에 대해서는 NVIDIA가 소유권을 주장하지 않으며, 해당 결과물은 전적으로 사용자에게 귀속됩니다. 이러한 조건은 Cosmos-Predict2가 연구 개발은 물론, 상용 환경에서도 폭넓게 활용될 수 있도록 설계되었음을 보여줍니다.
아래 링크를 통해 NVIDIA의 공식 라이선스 내용을 확인할 수 있습니다.
- NVIDIA Open Models License : https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
사전준비사항
이 포스팅에서는 ComfyUI를 활용하여 Cosmos-Predict2 모델로 이미지와 영상을 생성하는 방법을 소개합니다. 본문을 따라 하기 전에 아래의 필수 항목들을 미리 설치해 주시기 바랍니다.
이번 글에서는 Text-to-Image 모델과 Text-to-Video 모델을 중심으로, 텍스트 입력을 기반으로 한 이미지 및 영상 생성 과정을 단계별로 안내드립니다.
[Stabiliy Matrix&ComfyUI 설치하기] (포스팅에서 사용한 방식)
- ComfyUI 설치: [Marcus' Story] - [ComfyUI] 초보자도 쉽게 따라하는 Stability Matrix 활용하기
- ComfyUI-Manager 설치: [Marcus' Story] - [ComfyUI] Stability Matrix에 ComfyUI-Manager 설치하기
[로컬에 직접 ComfyUI 설치하기]
- ComfyUI 설치: [Marcus' Story] - [ComfyUI] [로컬 환경] ComfyUI 로컬 환경에 설치 및 실행 방법
- ComfyUI-Manager 설치: [Marcus' Story] - [ComfyUI] [로컬 환경] ComfyUI 관리 도구, ComfyUI-Manager 설치하기
목차
1. 실행 환경
2. ComfyUI 사용 노드
3. 이미지 생성 모델
4. 영상 생성 모델
1. 실행 환경
- 운영체제 : Windows 11
- ComfyUI : 0.3.41
- ComfyUI-Manager : V3.30
- Python : 3.10.11
- torch : 2.7.1 + cu128
- GPU : NVIDIA GeForce RTX 4060 Ti (vram : 16GB)
2. ComfyUI 사용 노드
이번 포스팅에서는 별도로 다운로드해야 할 커스텀 노드 없이 진행됩니다. 하지만 ComfyUI를 최신 버전으로 업데이트하는 것이 중요합니다. 최신 버전으로 업데이트하면 모델과의 호환성을 극대화할 수 있으며, 성능 개선 및 버그 수정을 통해 최적의 결과를 얻을 수 있습니다.
- Stability Matrix를 사용하는 경우 → Stability Matrix 화면에서 "Update" 버튼을 클릭하여 간편하게 업데이트할 수 있습니다.
- ComfyUI를 로컬에 설치한 경우 → ComfyUI-Manager에서 "Update ComfyUI" 버튼을 눌러 최신 버전으로 업데이트하세요.
3. 이미지 생성 모델
Cosmos-Predict2 모델은 현재 Hugging Face를 통해 다양한 버전으로 제공되고 있으며, 사용 목적과 컴퓨팅 환경에 맞게 적절한 모델을 선택하여 다운로드할 수 있습니다. 이번 포스팅에서는 그중 cosmos_predict2_2B_t2i 모델을 사용하여 텍스트 기반 이미지 생성 과정을 소개하겠습니다.
1) ComfyUI Workflow
아래 ComfyUI 공식 블로그에서 워크플로우 파일을 다운로드할 수 있습니다.
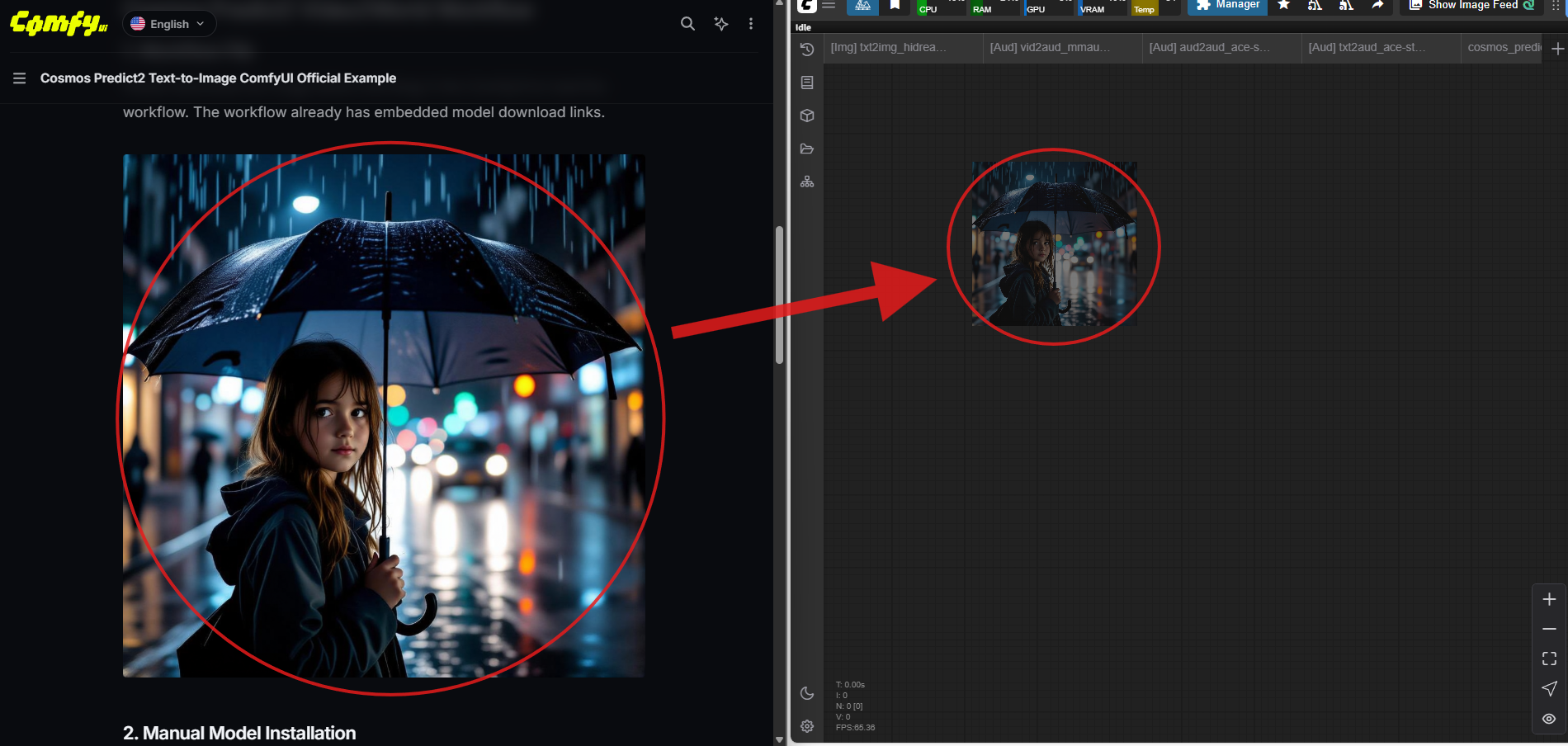
해당 페이지에서 워크플로우 파일(이미지 형식)을 다운로드한 후, ComfyUI 실행 화면으로 드래그 앤 드롭하면 자동으로 워크플로우가 불러와집니다.
아래 이미지는 워크플로우 사용 예시를 보여주는 참고용 이미지입니다.
2) 모델 파일 다운로드
ComfyUI에서 워크플로우 파일을 불러오면, 해당 모델을 자동으로 탐색하며, 로컬에 모델이 없는 경우 다운로드 링크를 안내해줍니다. 이 링크를 통해 손쉽게 필요한 모델 파일을 다운로드할 수 있습니다.

모델 다운로드가 완료되면, 아래와 같이 지정된 폴더 구조에 맞게 파일을 이동해 줍니다.
📂 ComfyUI/
├──📂 models/
│ ├── 📂 diffusion_models/
│ │ └─── cosmos_predict2_2B_t2i.safetensors
│ ├── 📂 text_encoders/
│ │ └─── oldt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └── 📂 vae/
│ └── wan_2.1_vae.safetensors
모든 모델 파일을 다운로드하셨다면, 위와 같은 폴더 구조에 맞춰 각 파일을 옮겨줍니다. 만약 StabilityMatrix를 통해 ComfyUI를 실행 중이라면, [StabilityMatrix → Data → Packages] 경로 내부에서 ComfyUI 폴더 위치를 먼저 확인한 후, 동일하게 위 폴더 구조로 파일을 배치하시면 됩니다.
3) 실행 (이미지 생성)
cosmos_predict2_2B_t2i 모델을 활용하여 이미지를 생성한 결과, 해상도 1024x1024의 고퀄리티 이미지를 약 1분 이내의 짧은 시간에 생성할 수 있었습니다. 이 과정에서 사용된 VRAM은 약 8.6GB였으며, 일반적인 소비자용 GPU 환경에서도 충분히 실행 가능한 수준이었습니다. 짧은 시간 안에 이 정도 수준의 이미지를 생성할 수 있다는 점에서 모델의 효율성과 품질 모두 매우 인상적이었습니다.
아래는 실제로 생성된 이미지 예시입니다.

cosmos_predict2_14B_t2i 모델의 성능이 궁금하여 직접 실행해보았습니다. 해당 모델은 해상도 1024x1024의 고퀄리티 이미지를 약 7~8분에 걸쳐 생성했으며, 이 과정에서 약 15.4GB의 VRAM이 사용되었습니다. 생성된 이미지는 확실히 매우 정교하고 디테일이 뛰어난 결과물이었지만, 예상보다 다소 긴 처리 시간이 소요된 점은 아쉬움으로 남았습니다. 일반적인 소비자용 GPU 환경에서는 2B 모델도 충분할 것으로 보입니다.
아래는 실제로 생성된 이미지 예시입니다.


4. 영상 생성 모델
이번에는 cosmos_predict2_2B_video2world_480p_16fps 모델을 활용하여 텍스트(및 이미지)를 기반으로 한 영상 생성을 진행해보겠습니다.
이 모델은 초기 시작 이미지를 입력해 영상으로 확장하는 Image-to-Video 방식과, 텍스트만으로 영상을 생성하는 Text-to-Video 방식을 모두 지원합니다. 이를 통해 다양한 형태의 시각적 시퀀스를 유연하게 생성할 수 있습니다.
1) ComfyUI Workflow
아래 링크에서 ComfyUI 공식 블로그를 통해 워크플로우 파일을 다운로드할 수 있습니다
- ComfyUI 공식 블로그 : https://docs.comfy.org/tutorials/video/cosmos/cosmos-predict2-video2world#1-workflow-file
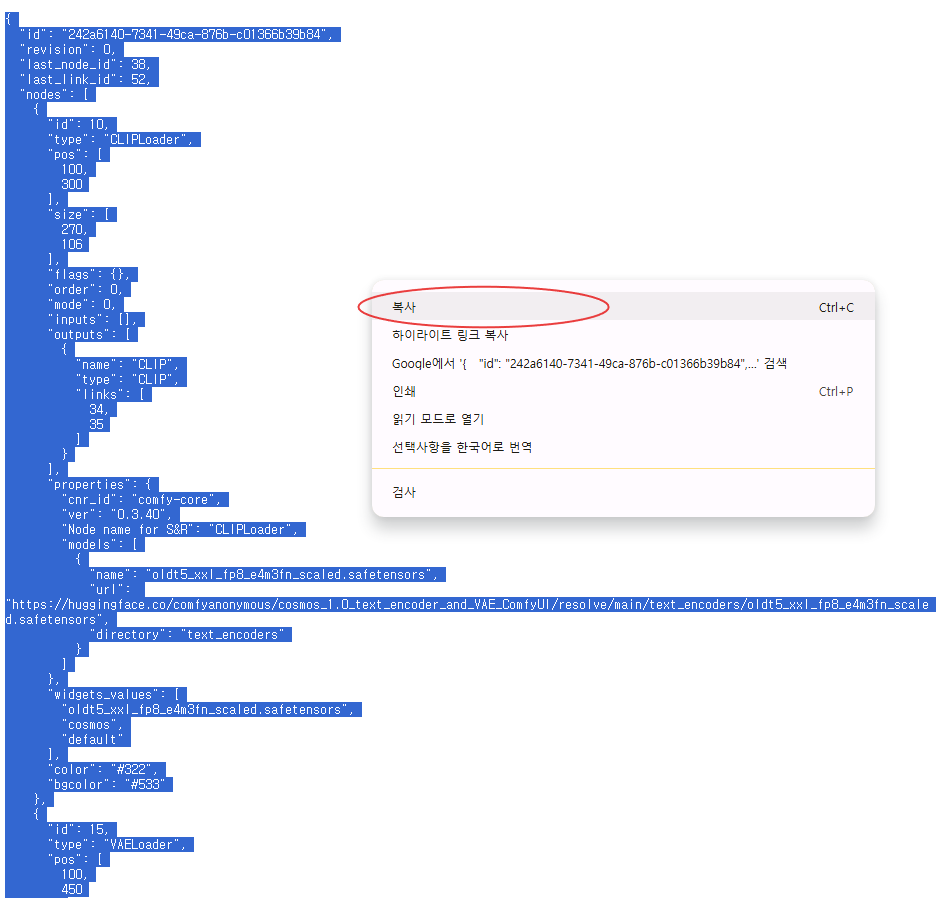
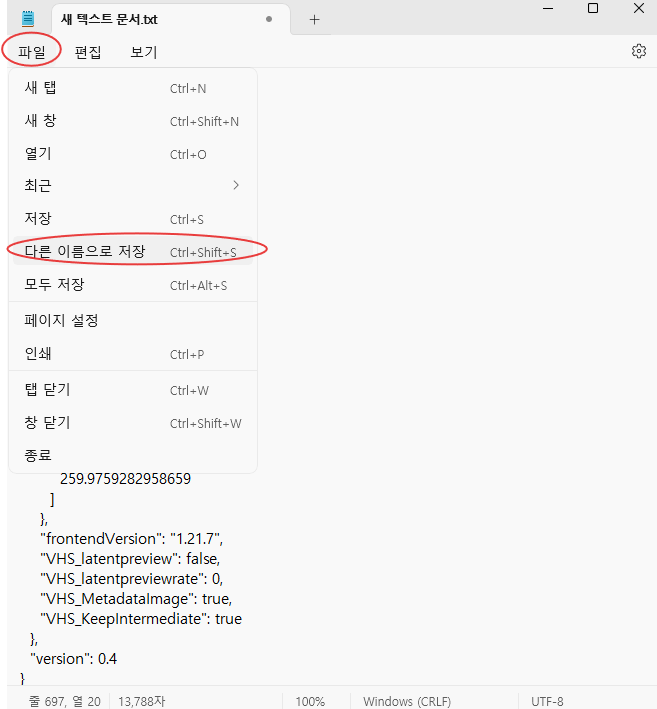
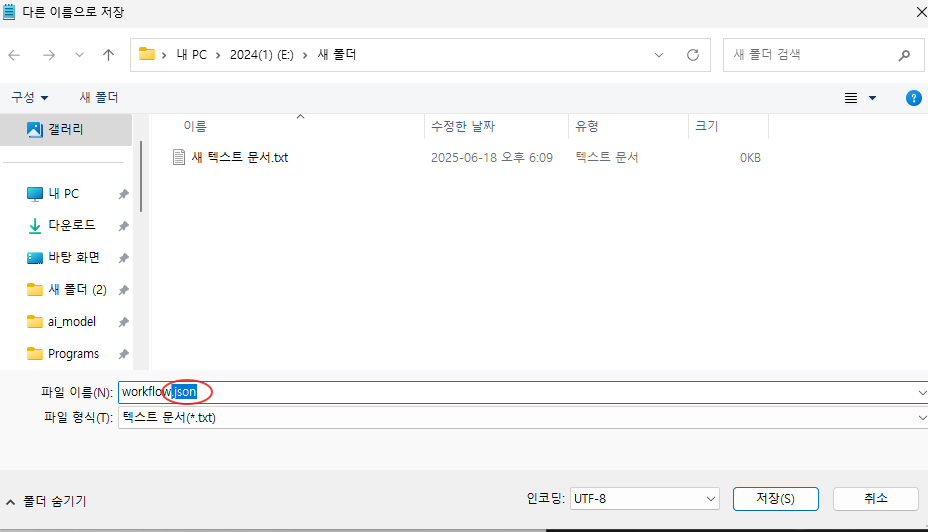
해당 워크플로우는 JSON 형식의 텍스트 파일로 제공되며, 이를 메모장 등 텍스트 편집기에 복사해 붙여넣은 뒤 파일 확장자를 .json으로 저장하시면 됩니다. 저장한 .json 파일을 ComfyUI 실행 화면으로 드래그 앤 드롭하면 워크플로우가 자동으로 불러와집니다.
2) 모델 파일 다운로드
이미지 생성 모델에서 한것과 동일안 방법으로 모델 다운로드를 해줍니다. 그리고 모델 다운로드가 완료되면, 아래와 같이 지정된 폴더 구조에 맞게 파일을 이동해 줍니다.
📂 ComfyUI/
├──📂 models/
│ ├── 📂 diffusion_models/
│ │ └─── cosmos_predict2_2B_video2world_480p_16fps.safetensors
│ ├── 📂 text_encoders/
│ │ └─── oldt5_xxl_fp8_e4m3fn_scaled.safetensors
│ └── 📂 vae/
│ └── wan_2.1_vae.safetensors
모든 모델 파일을 다운로드하셨다면, 위와 같은 폴더 구조에 맞춰 각 파일을 옮겨줍니다. 만약 StabilityMatrix를 통해 ComfyUI를 실행 중이라면, [StabilityMatrix → Data → Packages] 경로 내부에서 ComfyUI 폴더 위치를 먼저 확인한 후, 동일하게 위 폴더 구조로 파일을 배치하시면 됩니다.
3) 실행 (영상 생성)
cosmos_predict2_2B_video2world_480p_16fps 모델을 활용하여 Image to Video 방식으로 영상을 생성해보았습니다. 해상도 848x480, 길이 5초 분량의 영상을 생성하는 데 약 20분의 시간과 12.4GB의 VRAM이 소요되었습니다. 이전 버전에 비해 VRAM 사용량과 생성 시간 모두 개선되었으며, 일반적인 소비자용 GPU 환경에서도 무리 없이 실행 가능한 수준이었습니다. 생성 시간은 다소 긴 편이지만, 로컬 환경에서 고품질 영상을 안정적으로 생성할 수 있다는 점은 매우 인상적이었습니다.
아래는 실제로 생성된 영상 예시입니다.
이번 포스팅에서는 Cosmos-Predict2 모델을 ComfyUI 환경에서 활용하는 방법을 소개했습니다. 텍스트 입력을 기반으로 이미지와 영상을 생성하는 과정을 단계별로 살펴보았으며, 특히 cosmos_predict2_14B_t2i와 cosmos_predict2_2B_video2world_480p_16fps 모델을 직접 실행하면서 이미지 및 영상의 품질과 성능, VRAM 사용량 등의 실측 결과도 함께 공유드렸습니다.
직접 모델을 활용해 보시고 궁금한 점이나 나만의 팁, 유용했던 경험 등을 댓글로 남겨주시면 큰 도움이 될 것 같습니다.
읽어주셔서 감사합니다. 😊
'ComfyUI > 영상 생성' 카테고리의 다른 글
| [ComfyUI] 오디오·이미지 기반 AI 영상 생성 모델, Wan2.2-S2V 가이드 (2) | 2025.09.19 |
|---|---|
| [ComfyUI + Wan 2.2] AI 영상 생성 오픈소스, Wan 2.2 사용법 | ComfyUI로 로컬에서 실행하기 (6) | 2025.08.08 |
| [ComfyUI + Wan2.1-VACE] AI 하나로 Text to Video부터 Video 편집까지!|오픈소스|영상 생성 AI (2) | 2025.06.10 |
| [ComfyUI × 영상 생성 AI] 6GB VRAM으로도 가능한 고품질 영상 생성 AI, FramePack을 소개합니다. (2) | 2025.05.02 |
| [ComfyUI] HunyuanVideo보다 8.5배 빠른 영상 생성 AI, AccVideo를 소개합니다 (0) | 2025.04.09 |



