안녕하세요,
최근 AI 모델들은 점점 더 고성능화되고 있지만, 높은 연산 요구사항과 비용이 부담되는 경우가 많습니다. 특히, 로컬 환경에서 AI를 실행하려는 사용자들에게는 강력한 성능과 효율적인 리소스 활용이 중요한 요소가 됩니다.
이러한 요구에 부응하여 Mistral에서 새롭게 출시한 SLM(Small Language Model), Mistral Small 3 모델이 큰 주목을 받고 있습니다. 이번 글에서는 이 모델의 특징을 살펴보고, 직접 로컬에 설치하여 실행하는 과정을 소개하겠습니다.
Mistral Small 3 모델
Mistral Small 3 AI 모델은 Mistral AI에서 2025년 1월 30일에 발표한 240억 개의 매개변수를 가진 고성능·저지연 AI 언어 모델입니다. 이 모델은 오픈 소스로 공개되었으며, 뛰어난 연산 최적화를 통해 빠른 응답 속도가 중요한 애플리케이션과 실시간 인터랙션이 필요한 서비스에 최적화되어 있습니다. 또한, 대규모 모델과 견줄 만큼의 강력한 성능을 제공하면서도 상대적으로 가벼운 연산 요구사항을 갖춰, 로컬 환경에서도 효율적으로 구동될 수 있도록 설계되었습니다.
- Mistral Small 3 공식 소개페이지 : https://mistral.ai/en/news/mistral-small-3
Mistral Small 3 | Mistral AI
Mistral Small 3: Apache 2.0, 81% MMLU, 150 tokens/s
mistral.ai
주요 특징
1) 고성능
Mistral Small 3는 Llama 3.3 70B나 Qwen 32B와 같은 대형 모델과 경쟁할 수 있으며, GPT4o-mini와 같은 독점 모델의 강력한 대안으로 제시됩니다.
2) 다국어 지원
영어, 프랑스어, 독일어, 스페인어, 이탈리아어, 중국어, 일본어, 한국어, 포르투갈어, 네덜란드어, 폴란드어 등 다양한 언어를 폭넓게 지원하여 글로벌 환경에서도 활용이 가능합니다.
3) 낮은 지연 시간
레이어 구조를 최적화하여 전방 패스 시간을 단축했으며, 그 결과 MMLU 벤치마크에서 81% 이상의 정확도를 기록하고, 초당 150 토큰 이상의 처리 속도를 달성했습니다.
성능 비교

위 그래프는 언어 모델의 성능(MMLU-Pro)과 지연 시간(ms/token) 간의 관계를 나타냅니다. X축(가로축)은 지연 시간(토큰당 처리 시간)을 의미하며, 왼쪽으로 갈수록 처리 속도가 빠른 모델을 나타냅니다. Y축(세로축)은 성능(MMLU-Pro 점수)을 나타내며, 위로 갈수록 더 높은 성능을 가진 모델을 의미합니다. 따라서, 왼쪽 상단에 위치한 모델일 수록 이상적인 모델임을 나타냅니다.
Mistral Small 3는 약 11ms/token의 지연 시간을 기록하며, 그래프에서 가장 빠른 모델 중 하나로 나타납니다. 성능 또한 65점 이상으로, GPT-4o Mini보다 더 높은 성능을 제공하면서도 지연 시간은 더 짧아 효율성이 뛰어난 모델입니다. Qwen-2.5 32B는 더 높은 성능(약 70점)을 보이지만, 지연 시간이 약 16ms/token으로 Mistral Small 3보다 45% 정도 더 느립니다. 반면, Gemma-2 27B는 지연 시간이 더 길고 성능도 낮아 Mistral Small 3에 비해 효율성이 떨어지는 것을 확인할 수 있습니다.
라이선스
Mistral Small 3는 Apache 2.0 라이선스로 제공되며, 상업적 사용이 가능합니다. Apache 2.0 라이선스는 자유롭게 수정, 배포 및 상업적 활용이 가능한 오픈 소스 라이선스로, 기업 및 개발자들이 제한 없이 사용할 수 있습니다. 또한, 라이선스 조건에 따라 원본 라이선스를 유지하고, 수정 사항을 명시하면 자유롭게 모델을 활용할 수 있습니다. 따라서, Mistral Small 3는 기업, 연구 기관, 스타트업 등에서 상업적 서비스 및 애플리케이션 개발에 사용할 수 있는 강력한 오픈 소스 AI 모델입니다.
목차
1. 실행 환경
2. Mistral Small 3 설치 (ollama 활용)
3. Mistral Small 3 실행
1. 실행 환경
- 운영체제 : Windows 11
- ollama : 0.3.12
- GPU : NVIDIA GeForce RTX 4060 Ti
2. Mistral Small 3 설치 (ollama 활용)
Mistral Small 3 모델을 로컬에 설치하여 사용하는 방법으로 Ollama를 활용한 설치 및 실행 방법을 소개하려 합니다.
그 이유는 두 가지입니다. 첫째, Ollama를 통해 모델을 다운로드하면 과정이 간편하고 오류 없이 안정적으로 작동합니다. 둘째, Ollama에서 제공하는 모델은 양자화(Quantization)되어 있어, 더 낮은 컴퓨팅 사양에서도 원활하게 실행할 수 있습니다.
1) Ollama 설치
아래 Ollama 공식 사이트에서 파일을 다운받고 설치해줍니다.
- Ollama 공식 사이트 : https://ollama.com/download
설치를 완료하셨으면 아래 명령어를 통해 제대로 설치가 됐는지 확인합니다. 만약 ollama 버전이 출력되지 않으면 환경 변수를 설정해야합니다.
# Windows PowerShell
ollama --version
2) 환경 변수 추가 (위 과정에서 ollama 버전이 출력되지 않을 경우)
(Windows 11 기준)
(1) Win + S → "환경 변수" 검색 → "시스템 환경 변수 편집" 실행
(2) 시스템 속성 창에서 "환경 변수" 클릭

(3) 시스템 변수 → Path → "편집" 버튼 클릭

(4) "새로 만들기" 클릭 → Ollama 경로 추가 → 모두 확인 클릭
(Ollama 설치 경로는 설치 과정에서 사용자가 선택한 위치에 저장되며, ollama.exe 파일이 위치한 상위 폴더까지 경로로 설정하면 됩니다.)

3) Mistral small 3 모델 다운로드
아래 명령어를 통해 Mistral small 3 모델을 다운로드합니다.
# Windows PowerShell
ollama pull mistral-small:24b # mistral small 3 모델 다운로드
3. Mistral small 3 실행
아래 명령어를 통해 Mistral small 3 모델을 실행합니다.
# Windows PowerSehll
ollama list # 로컬 환경에 다운로드 된 모델 확인
ollama run [모델명] # 해당 모델 실행
다운로드 된 모델을 실행하는데는 바로 준비가 되었습니다. 아래의 프롬프트를 입력해서 질문해보았습니다.
- 질문 : 피보나치 수열에 대해 설명해줘.
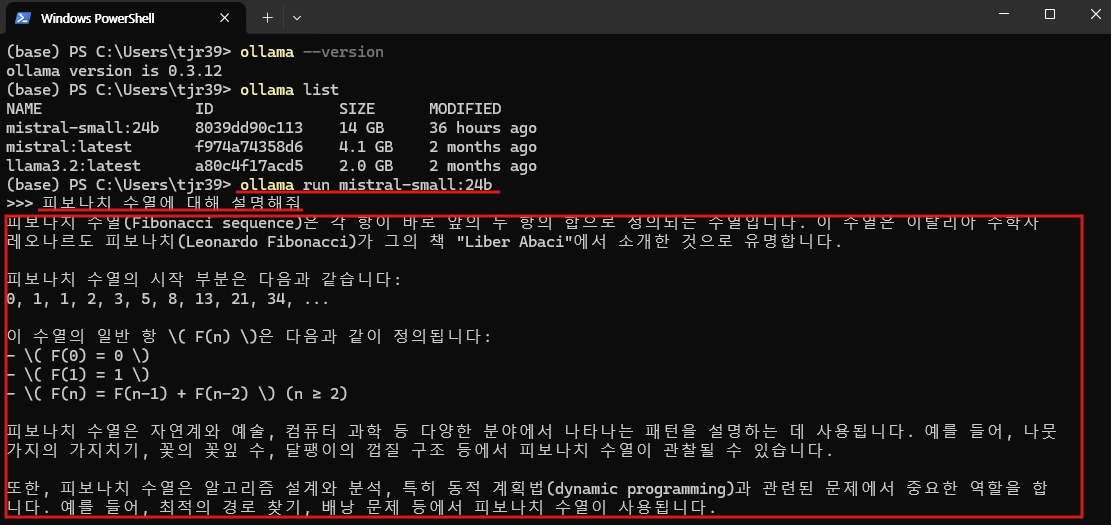
위 이미지는 Mistral Small 3 모델을 실행한 결과입니다. 실행 시 약 15GB의 VRAM이 사용되었으며, 답변 속도는 GPT-4o보다 약간 느린 속도로 생성되었습니다. 더 높은 컴퓨팅 성능에서 실행하면 더욱 빠른 응답이 가능할 것으로 보입니다.
다양한 질문을 테스트해 본 것은 아니지만, 한국어 질문에 대해 정확한 한국어 응답을 제공했으며, 질문을 인식하고 답변 방향을 설정하는 능력도 뛰어났습니다. 이전에 DeepSeek 모델을 실행할 때는 한국어 질문에도 간혹 중국어가 섞여서 출력되는 경우가 있었지만, Mistral Small 3에서는 이러한 오류 없이 정상적으로 작동했습니다.
로컬 환경에서 AI 모델을 실행하려는 분들께는 Mistral Small 3를 적극 추천드립니다.
오픈 소스로 공개된 모델임에도 불구하고, Mistral Small 3의 뛰어난 성능과 낮은 컴퓨팅 요구 사항은 정말 인상적이었습니다. 지금까지 다양한 오픈 소스 모델을 직접 실행하며 비교해왔지만, 이 모델은 현재까지 가장 만족스러운 성능을 보여주는 모델 중 하나라고 생각됩니다.
특히, 상대적으로 적은 연산 자원만으로도 빠른 속도로 답변을 생성한다는 점이 매우 놀라웠습니다. 보통 고성능 AI 모델은 높은 하드웨어 사양을 요구하지만, Mistral Small 3는 효율적인 최적화를 통해 낮은 VRAM에서도 원활하게 작동하면서도 뛰어난 성능을 유지한다는 점에서 큰 강점을 가지고 있습니다.
오픈 소스 모델을 로컬에서 실행하려는 사용자들에게는 가장 추천할 만한 모델 중 하나로 손꼽을 수 있을 것 같습니다.
앞으로도 더 좋은 글 작성할 수 있도록 노력하겠습니다.
좋은 하루 되세요! 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [오픈 소스 AI] Deepseek와 동급의 무료 고성능 추론 모델, QwQ를 소개합니다. (0) | 2025.03.15 |
|---|---|
| 국내 기업 카카오의 오픈 소스 AI 모델, Kanana를 소개합니다. (0) | 2025.03.05 |
| [오픈 소스 AI] Suno와 같이 노래를 생성 해주는 AI 모델, "YuE"를 소개합니다. (0) | 2025.02.10 |
| [오픈 소스 AI] [로컬 환경] DeepSeek의 두 번째 이미지 생성 모델, JanusPro를 소개합니다. (0) | 2025.02.02 |
| [오픈 소스 AI] [로컬 환경] DeepSeek의 이미지 생성 모델, Janus를 소개합니다. (2) | 2025.01.30 |



