안녕하세요,
지난 포스팅에 이어 이번에는 DeepSeek에서 가장 최근에 선보인 모델, JanusPro를 소개하고자 합니다. 이 모델은 기존 방식보다 더 효율적으로 이미지를 생성할 수 있도록 개발되었습니다. 특히, 속도와 품질을 모두 고려한 최적화된 아키텍처를 적용해 다양한 환경에서 활용할 수 있도록 설계되었습니다. 이번 글에서는 JanusPro의 주요 특징과 로컬 환경에서 직접 설치하고 실행하는 방법을 자세히 알아보겠습니다.
Janus Pro
JanusPro는 DeepSeek이 개발한 고급 멀티모달 AI 모델로, 이미지 이해와 생성 기능을 하나의 모델에 통합하여 더욱 정교한 결과를 제공합니다. 기존 방식과 달리, JanusPro는 이미지 이해와 생성 과정을 독립적인 경로로 처리하면서도 통합된 트랜스포머 아키텍처를 활용하여 두 작업을 효율적으로 수행합니다. 이를 통해 각 작업 간의 간섭을 최소화하면서도 모델의 유연성을 극대화하였으며, 보다 자연스럽고 세밀한 이미지 분석 및 생성을 가능하게 했습니다. 또한, DeepSeek-LLM-1.5B-base 또는 DeepSeek-LLM-7B-base를 기반으로 구축되었으며, SigLIP-L을 시각 인코더로 사용하여 멀티모달 이해 능력을 강화하였습니다.
- DeepSeek 공식페이지 : https://www.deepseek.com/

이미지 생성 과정에서는 VQ tokenizer를 사용하여 384×384 해상도의 이미지를 생성할 수 있으며, 다운샘플 비율 16을 적용하여 보다 정밀한 이미지 표현이 가능합니다. 이를 통해 콘텐츠 제작, 디자인, 의료 분석 등 다양한 분야에서 활용될 수 있습니다. 또한, 자기회귀 언어 모델(autoregressive language model)을 기반으로 한 미니멀한 아키텍처를 도입하여 복잡한 구조 수정 없이도 효율적인 학습이 가능하도록 설계되었습니다.
현재 이 모델은 로컬 환경에서 사용이 가능할 뿐만 아니라, 허깅페이스 스페이스에서 무료로 이용해볼 수 있습니다. 아래 링크를 통해 DeepSeek 허깅페이스에 접속하여 직접 사용가능합니다.
- DeepSeek 허깅페이스: https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B
주요 특징
JanusPro의 주요 특징으로는 다음과 같습니다.
- 멀티모달 통합 모델
- 이미지 이해와 생성을 하나의 모델에서 동시에 처리하도록 설계
- 독립적인 경로로 작업을 수행하면서도 통합된 트랜스포머 아키텍처를 활용하여 높은 효율성 제공 - DeepSeek-LLM 기반 언어 모델
- DeepSeek-LLM-1.5B-base 또는 DeepSeek-LLM-7B-base를 기반으로 정확한 텍스트 생성 및 이미지 설명 가능
- 자연어와 이미지 데이터를 효과적으로 연결 - SigLIP-L 시각 인코더 적용
- SigLIP-L을 활용하여 이미지 분석 및 객체 인식 능력 향상
- 이미지 속 다양한 요소를 정밀하게 분석하고 텍스트로 변환 가능 - VQ tokenizer 기반 이미지 생성
- 384x384 해상도의 이미지 생성 지원
- 사실적이고 정밀한 이미지 표현이 가능하여 창작 및 디자인 활용도 증가
라이선스
JanusPro 모델은 이전 모델과 동일하게 DeepSeek 라이선스를 따르며, 복제, 수정, 배포 및 상업적 활용이 가능합니다. 다만, 불법적이거나 윤리적으로 문제가 될 수 있는 용도는 엄격히 금지됩니다. 예를 들어, 군사적 목적, 허위 정보 생성 및 유포, 개인 식별 정보의 무단 사용, 차별적이거나 혐오적인 콘텐츠 제작, 자동화된 법적 의사 결정 등에는 사용할 수 없습니다. 또한, Janus 모델을 수정하거나 배포할 경우 원본 라이선스를 유지하고 사용 제한 조항을 포함해야 합니다. DeepSeek은 라이선스 위반 시 모델 사용을 제한할 권리를 가지며, 모든 법적 분쟁은 중국(중화인민공화국) 법을 따릅니다.
목차
1. 실행 환경
2. JanusPro 설치
3. JanusPro 실행
실행 환경
- 운영체제 : Windows 11
- Python : 3.10.0
- torch : 2.3.1+cu121
- torchvision : 0.18.1+cu121
- decorator : 5.1.1
- GPU : NVIDIA GeForce RTX 4060 Ti
JanusPro 설치
1) 깃허브 코드 다운로드
아래 Janus 깃허브 페이지에서 코드를 다운받습니다.
- Janus 깃허브 페이지 : https://github.com/deepseek-ai/Janus
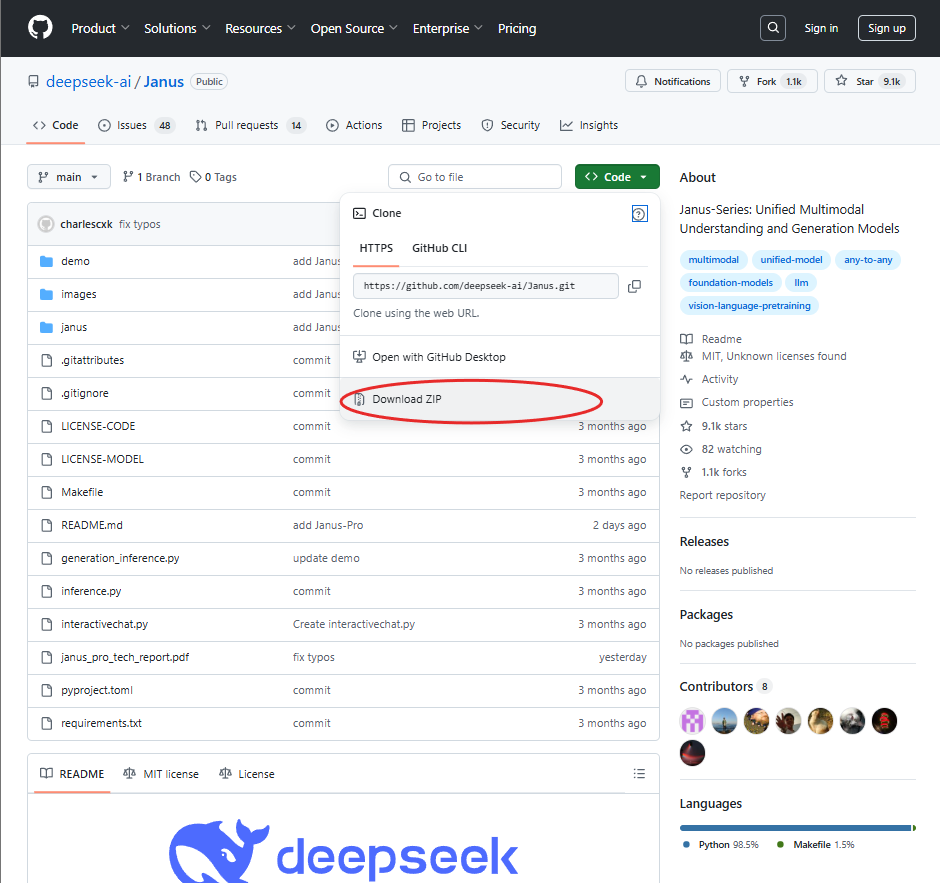
해당 코드를 다운로드 하셨으면 압축을 풀어줍니다.
2) 가상 환경 생성 (선택 사항)
아래 명령어를 사용하여 conda 가상 환경을 생성할 수 있습니다. conda가 설치되지 않았거나 설치를 원하지 않는 경우, 이 단계를 건너뛰어도 무방합니다.
# Windows PowerShell
conda create -n JanusPro python=3.10
conda activate JanusPro
3) 필수 패키지 다운로드
아래 명령어를 사용하여 필수 패키지를 설치합니다. 실행 전에 DeepSeek 깃허브에서 다운로드한 파일 위치로 이동한 후 명령어를 실행해야 합니다.
# Windows PowerShell
cd E:\ai_model\JanusPro # 깃허브에서 다운받은 폴더 경로
pip install -e .[gradio] # 필요 패키지 다운로드
pip install decorator # 필요 패키지 다운로드
pip install torch==2.3.1+cu121 -f https://download.pytorch.org/whl/torch_stable.html # torch 패키지 버전 수정
pip install torchvision==0.18.1+cu121 --index-url https://download.pytorch.org/whl/cu121 # torchvision 패키지 버전 수정
4) 모델 다운로드 및 실행
아래 명령어를 사용하여 Janus를 실행시켜줍니다. 이 명령어를 실행하면 Janus 실행에 필요한 모델들을 다운받게 됩니다.
# Windows PowerShell
python demo/app_janusPro.py
JanusPro실행
위 명령어를 통해 JanusPro 모델을 실행할 수 있습니다. 이 모델을 실행하면 Janus 모델과 동일한 웹 인터페이스(UI)를 제공합니다.
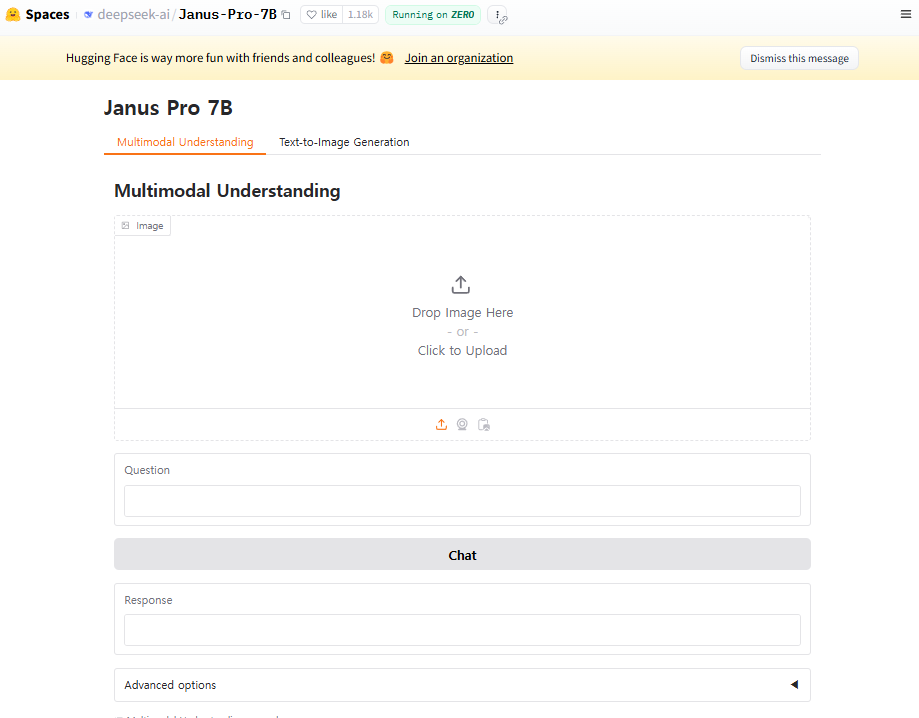
- Multimodal Understanding (멀티모달 이해)
- Text-to-Image Generation (텍스트 기반 이미지 생성)

Janus 모델과 비교를 위해 이전 포스팅에서 이미지 이해 및 생성에 사용한 프롬프트를 똑같이 사용해보겠습니다.
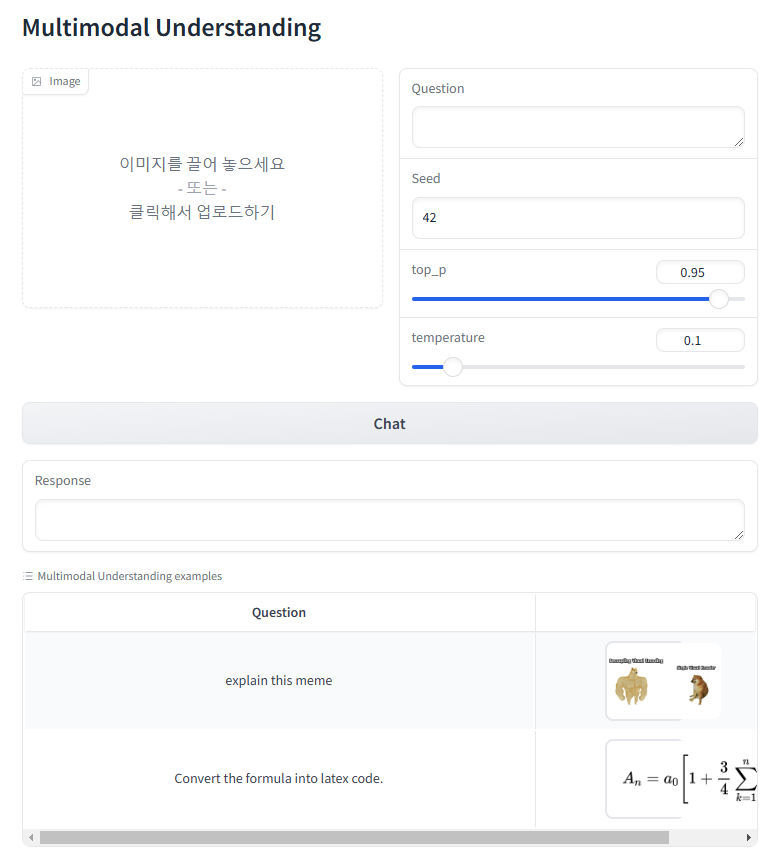
1) Multimodal Understanding
사용자가 입력한 이미지와 텍스트를 분석하여 의미를 파악한 후, 이를 바탕으로 적절한 설명을 생성하거나 특정 작업을 수행합니다.
다음과 같이 테스트를 진행했습니다.
- 목적 : 입력한 이미지를 인식하고 이를 설명할수 있는지 확인
- 이미지 삽입 : 테스트용 이미지
- 입력 프롬프트 : Describe the image content in detail

- 결과 : The image shows a person standing outdoors, surrounded by blooming cherry blossoms. The individual is wearing a light-colored, long-sleeved shirt with a ruffled hem. They have long, dark hair adorned with a white flower on one side. The person is also wearing a black mask, covering their nose and mouth. The background includes a wooden structure, greenery, and a clear blue sky.
이전 모델은 불필요한 요소까지 과도하게 묘사하는 경향이 있었던 반면, JanusPro 모델은 이미지의 핵심 내용만 정확하고 간결하게 표현해 주었습니다.
2) Text-to-Image Generation 실행
사용자가 입력한 텍스트(프롬프트)에 기반하여 해당 내용에 맞는 이미지를 생성합니다.
다음과 같이 테스트를 진행했습니다.
- 목적 : 고양이 이미지 생성
- 입력 프롬프트 : A highly detailed, ultra-realistic painting of a tuxedo cat wearing an elegant black tuxedo with a white bow tie. The cat has piercing green eyes and a sophisticated expression, sitting in a luxurious Victorian-style lounge with warm lighting. The fur texture is soft and detailed, reflecting individual hairs. The tuxedo is perfectly tailored, with fine silk fabric and shiny buttons. The scene has cinematic lighting with dramatic shadows and highlights, creating a refined and elegant atmosphere. The background features a classic fireplace, a golden chandelier, and deep red velvet curtains, enhancing the aristocratic feel. The image should be 8K, ultra HD, with photorealistic rendering and artistic depth.

- 생성결과



한 번의 생성 과정에서 5장의 이미지가 생성되며, 현재 실행 환경에서는 약 5분 정도의 시간이 소요되었습니다. 또한, VRAM은 약 25~30GB가 사용되었습니다. 생성된 결과는 이전 모델에 비해 확연히 개선되었으며, 기존 모델에서 종종 나타나던 AI 이미지 특유의 비정상적인 모습이나 부자연스러운 자세 등이 이번 JanusPro 모델에서는 거의 발생하지 않았습니다.
JanusPro 모델은 보다 자연스럽고 정교한 이미지 생성 능력을 갖춘 AI 모델로, 기존의 문제점을 효과적으로 개선하면서도 뛰어난 성능을 보여주었습니다. 특히, 불필요한 세부 묘사를 줄이고 핵심적인 요소만 정확하게 표현하는 점에서 더욱 실용적이며, 생성된 이미지의 품질 또한 이전 모델보다 월등히 향상되었습니다.
이번 테스트를 통해 JanusPro 모델이 이미지 이해와 생성에서 한층 발전된 기술력을 반영하고 있으며, 다양한 활용 가능성을 지닌 모델임을 확인할 수 있었습니다. 이러한 모델이 현재 오픈 소스로 공개된 점은 앞으로도 발전 가능성은 물론, 다양한 산업 분야에서 폭넓게 활용될 것으로 기대됩니다.
감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [오픈 소스 AI] [로컬 환경] 저용량 고성능의 SLM, Mistral Small 3를 소개합니다. (0) | 2025.02.13 |
|---|---|
| [오픈 소스 AI] Suno와 같이 노래를 생성 해주는 AI 모델, "YuE"를 소개합니다. (0) | 2025.02.10 |
| [오픈 소스 AI] [로컬 환경] DeepSeek의 이미지 생성 모델, Janus를 소개합니다. (2) | 2025.01.30 |
| [오픈 소스 AI] 새로운 물질의 구조를 설계해주는 AI, MatterGen을 소개합니다. (0) | 2025.01.27 |
| [오픈 소스 AI] [로컬 환경] 저화질 영상을 고화질로 만들어주는 AI, STAR를 소개합니다. (0) | 2025.01.21 |



