안녕하세요,
지난 포스팅에서 우리는 OmniGen을 활용하여 텍스트를 기반으로 이미지를 생성하고, 특정 이미지를 수정하는 방법에 대해 살펴보았습니다. 이번 글에서는 첫 번째 포스팅에 이어, OmniGen의 심화 기능에 대해 다뤄보려 합니다. 여러 이미지를 활용해 특정 포즈의 이미지를 생성하거나, 다른 이미지의 스타일을 적용하는 등 OmniGen의 확장된 기능을 알아보겠습니다.
OmniGen
OmniGen은 VAE(Variational Autoencoder)와 Transformer 모델을 결합한 통합 이미지 생성 모델입니다. 이전 포스팅에서는 OmniGen을 활용하여 텍스트를 기반으로 이미지를 생성하거나 특정 이미지를 수정하는 방법을 다뤘습니다. 이 모델은 단순히 텍스트 기반 생성뿐만 아니라, 여러 이미지를 참고하여 특정 포즈의 이미지를 생성하거나, 다른 이미지의 스타일을 가져오는 등 다양한 이미지 생성 기능을 제공합니다. 이번 포스팅에서는 OmniGen의 이러한 다양한 기능들에 대해 알아보겠습니다.
- OmniGen 깃허브 : https://github.com/VectorSpaceLab/OmniGen
- 이전 포스팅 (OmniGen 이미지 생성) : https://marcus-story.tistory.com/92
사전준비사항
이 포스팅은 ComfyUI에서 OmniGen 모델을 활용하는 방법에 대한 내용입니다. 본문을 읽기 전에 아래 항목들을 미리 설치해 주시기 바랍니다.
- ComfyUI 설치 방법 : [Macus' Story] - [이미지 생성 AI] [로컬 환경] ComfyUI 이용하여 이미지 생성하기 1탄
- ComfyUI-Manager 설치 방법 : [Marcus' Story] - [이미지 생성 AI] [로컬 환경] ComfyUI 이용하여 이미지 생성하기 2탄 : ComfyUI-Manager
- OmniGen 모델 설치 : [Marcus' Story] - [이미지 생성 AI] [로컬 환경] ComfyUI 이용하여 영상 생성하기 6탄 : OmniGen AI, txt2img, img2img
목차
1. 실행 환경
2. ComfyUI 사용 노드
3. 포즈 추출 및 이미지 생성 1
4. 포즈 추출 및 이미지 생성 2
1. 실행 환경
- 운영체제 : Windows 11
- ComfyUI : 0.2.7
- ComfyUI-Manager : V2.51.9
- Python : 3.10.0
- torch : 2.3.1 + cu121
- GPU : NVIDIA GeForce RTX 4060 Ti
2. ComfyUI 사용 노드
이번 포스팅에서 사용하는 커스텀 노드는 이전 포스팅에서 사용한 것과 동일합니다. 이전 포스팅에서 커스텀 노드를 모두 다운로드했다면, 바로 다음 단계로 진행하시면 됩니다. 아래는 이번 포스팅에 사용된 ComfyUI 커스텀 노드 목록입니다. 모델 실행에 필수적인 노드를 "필수"로 표기하였으며, 사용에 필수적이지 않은 노드는 "선택사항"으로 표기하였습니다.
- OmniGen-ComfyUI: ComfyUI에서 OmniGen 모델을 활용할 수 있도록 지원하는 커스텀 노드입니다. 이를 통해 텍스트-투-이미지 생성, 이미지 편집, 세그멘테이션, 포즈 추정 등 다양한 작업을 수행할 수 있습니다. 설치 시, ComfyUI의 models/Omnigen 디렉토리에 OmniGen 모델 파일을 배치하고, Comfy Manager를 통해 해당 노드를 설치하면 됩니다. (필수)
- Use Everywhere (UE Nodes) : 이미지 생성 툴에서 다양한 기능을 확장해주는 플러그인입니다. 이번에는 "Anything Everywhere"를 사용했습니다. (선택사항)
3. 포즈 추출 및 이미지 생성 1
특정 이미지의 인물의 포즈를 skeleton 형태로 추출한 후, 이를 기반으로 새로운 이미지를 생성하는 방법입니다. 이 방식을 사용하면 특정 이미지의 인물을 그대로 따라하는 새로운 이미지를 생성할 수 있습니다. 노드 구성은 아래와 같습니다.
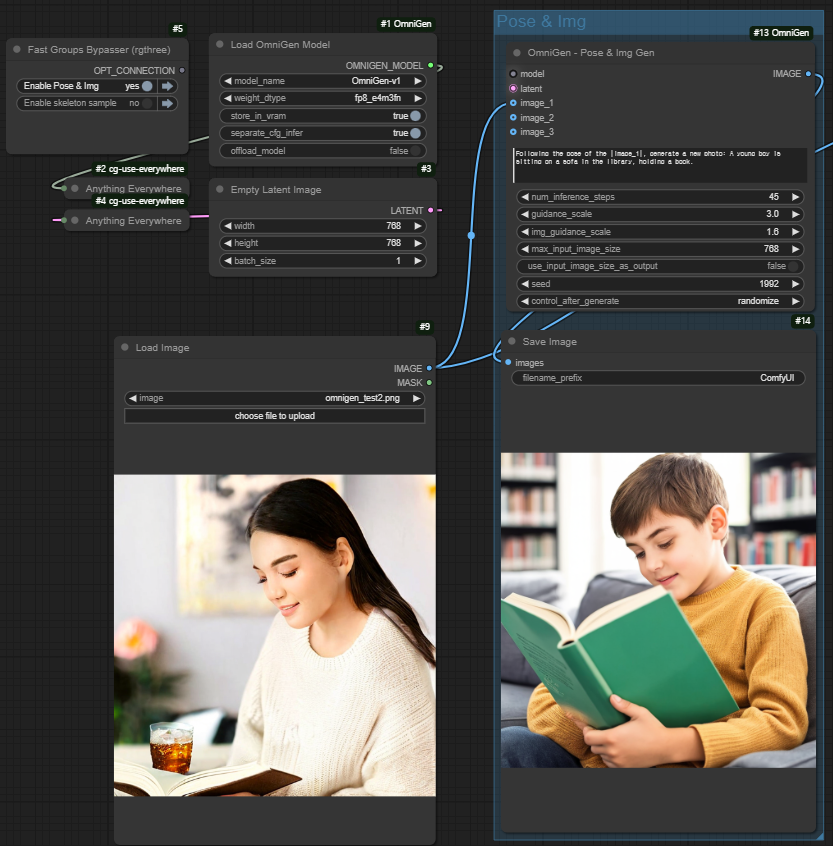
이번에 생성한 이미지는 Load Image를 통해 입력받은 이미지의 포즈를 기반으로 새로운 이미지를 생성하는 방식으로 동작합니다. 먼저, 입력된 이미지를 기반으로 인물의 포즈를 스켈레톤 형태로 분석하고 추출합니다. 이 추출된 포즈 데이터는 OmniGen 모델의 입력값으로 사용되어, 포즈를 유지하면서도 스타일이나 배경이 달라진 새로운 이미지를 생성합니다. 이를 통해 원본 이미지의 인물 포즈는 그대로 살리면서도 창의적이고 독창적인 결과물을 만들어낼 수 있습니다. 최종적으로 생성된 이미지는 원하는 파일명으로 저장되어 다양한 활용이 가능합니다.
사용 프롬프트
- Pose & Img Gen 노드 : "Following the pose of the |image_1|, generate a new photo: A young boy is sitting on a sofa in the library, holding a book."
이미지에서 추출한 포즈를 확인하고 싶다면, 아래와 같이 별도의 노드를 추가로 구성하면 됩니다. 이를 통해 처음 입력받은 이미지에서 추출된 포즈 데이터를 시각적으로 확인할 수 있습니다. 추가된 노드는 추출된 스켈레톤 형태의 포즈를 렌더링하여 명확하게 보여주며, 이후 이미지 생성 과정에서 활용될 포즈 정보를 한눈에 확인할 수 있습니다.

사용 프롬프트
- Pose Extraction : "Detect the skeleton of human in the |image_1|"
- Img Generation : "Generate a new photo using the following |image_1| and text as conditions: A young boy is sitting on a sofa in the library, holding a book."
4. 포즈 추출 및 이미지 생성 2
이번에는 두 장의 이미지에서 특정 부분을 추출해서 새로운 이미지를 생성해 보겠습니다. 노드 구성은 아래와 같습니다.

위 노드 구성은 두 장의 이미지를 결합해 새로운 이미지를 생성하는 과정으로 이루어져 있습니다. 먼저 Load Image 노드를 사용해 기준이 되는 이미지와 추가적인 스타일이나 요소를 반영할 이미지를 업로드합니다. 이후 Load OmniGen Model 노드를 통해 OmniGen 모델을 로드하고, Empty Latent Image 노드에서 생성될 이미지의 크기와 관련 설정을 정의합니다. OmniGen - 2Img & Img Gen 노드는 두 이미지를 활용해 포즈와 스타일을 결합한 새로운 이미지를 생성하며, 최종 결과물은 Save Image 노드를 통해 저장됩니다. 이 과정으로 두 이미지를 기반으로 창의적인 결과물을 만들어낼 수 있습니다.
사용 프롬프트
- 2Img & Img Gen : "Two women stand close together with their arms around each other, smiling brightly as they face forward. They hold shopping bags in both hands, adding a lively and cheerful touch to the scene.
One woman is the woman in |image_1|, the other woman is the woman in |image_2|."
하나의 이미지에서 인물 정보를 가져오고, 다른 이미지에서 배경 정보를 추출하여 새로운 이미지를 생성하는 것도 가능합니다. 노드 구성은 동일하며, 텍스트 프롬프트를 적절히 조정하기만 하면 됩니다.

각 이미지에서 특성들을 완벽하게 반영하지는 못했지만, 어느 정도 특성을 반영하여 새로운 이미지를 생성했습니다. 노드 옵션 설정이나 이미지 크기 조정을 통해 더 나은 결과를 얻을 수 있을 것으로 보입니다.
사용 프롬프트
- 2Img & Img Gen : "Following the pose of the |image_1|, the location of the |image_2| and the woman of the |image_2|, generate a new photo: A woman is sitting on a bench, holding a book."
OmniGen 노드 구성 파일
OmniGen은 단 하나의 모델로 텍스트만을 이용해 다양한 이미지 컨트롤이 가능한 강력한 도구입니다. 이미지를 연결한 뒤 텍스트 프롬프트에 충분한 설명을 더하고, 적용 방식을 명확히 알려주면 이를 기반으로 새로운 이미지를 생성할 수 있습니다. 이는 텍스트와 이미지의 상호작용을 통해 창의적이고 독창적인 결과물을 만들어내는 데 큰 장점을 제공합니다. 그러나 현재 OmniGen은 아직 프롬프트를 잘못 해석하는 경우가 종종 있으며, 특히 손을 표현하는 데 있어 다소 부족한 부분이 있었습니다. 앞으로 이러한 부분이 개선된다면 OmniGen은 더욱 완벽한 이미지 생성 도구로 발전할 가능성이 큽니다.
감사합니다. 😊



