안녕하세요,
지난 포스팅에서는 PuLID-Flux 모델을 활용해 실사 이미지의 인물 얼굴 특징을 학습하고 일관된 이미지를 생성하는 방법을 소개했습니다. 그러나 이 방법에는 애니메이션 이미지의 특징을 충분히 학습하지 못하는 한계가 있었습니다.
이번 포스팅에서는 SD(Stable Diffusion) 모델을 활용해 애니메이션 이미지의 특징도 효과적으로 학습하여 일관된 이미지를 생성하는 방법을 다뤄보겠습니다. 이를 통해 다양한 스타일의 이미지를 균일하게 표현할 수 있는 기술적 접근을 살펴보겠습니다.
IPAdapter
IPAdapter는 사전 학습된 텍스트-이미지 확산 모델에 이미지 프롬프트 기능을 추가하는 경량 어댑터입니다. 이를 통해 텍스트와 이미지 프롬프트를 결합하여 보다 정교하고 풍부한 이미지를 생성할 수 있도록 지원합니다. ComfyUI_IPAdapter_plus는 이러한 IPAdapter 모델을 위한 참조 구현체로, 특히 이미지-이미지 조건부 생성에서 강력한 성능을 발휘하며, 참조 이미지의 주제나 스타일을 새롭게 생성되는 이미지에 쉽게 적용할 수 있는 기능을 제공합니다.
- ComfyUI-IPAdapter_Plus 깃허브 : https://github.com/cubiq/ComfyUI_IPAdapter_plus
GitHub - cubiq/ComfyUI_IPAdapter_plus
Contribute to cubiq/ComfyUI_IPAdapter_plus development by creating an account on GitHub.
github.com
주요 기능
IPAdapter의 주요 기능으로는 다양한 모델 지원과 이미지와 텍스트 조건의 결합을 통한 유연한 이미지 생성이 있습니다. 예를 들어 'PLUS' 모델은 강력한 스타일 전이를 지원하며, 'PLUS FACE' 모델은 인물 사진의 스타일 전환에 특화된 기능을 제공합니다. 이를 통해 사용자는 텍스트와 이미지를 동시에 활용해 보다 정밀한 이미지 결과물을 얻을 수 있습니다. 설치는 ComfyUI의 최신 버전을 바탕으로 이루어지며, 추가적인 커스텀 노드를 활용하여 쉽게 통합할 수 있도록 되어 있습니다.
사전 준비 사항
이 포스팅은 ComfyUI에서 Flux 모델을 활용하는 방법에 대한 내용입니다. 따라서 본문을 읽기 전에 ComfyUI와 ComfyUI-Manager를 미리 설치해 주시기 바랍니다.
- ComfyUI 설치 방법 : [Macus' Story] - [이미지 생성 AI] [로컬 환경] ComfyUI 이용하여 이미지 생성하기 1탄
- ComfyUI-Manager 설치 방법 : [Marcus' Story] - [이미지 생성 AI] [로컬 환경] ComfyUI 이용하여 이미지 생성하기 2탄 : ComfyUI-Manager
목차
1. 실행 환경
2. ComfyUI 사용 노드
3. 모델 다운로드 및 위치 설정
4. 노드 구성
5. 실행
1. 실행 환경
- 운영체제 : Windows 11
- ComfyUI : 0.2.7
- Python : 3.10.0
- torch : 2.3.1 + cu121
- xformers : 0.0.27
- GPU : NVIDIA GeForce RTX 4060 Ti
2. ComfyUI 사용 노드
아래는 이번 포스팅에서 사용된 ComfyUI 커스텀 노드입니다. 모델 실행에 필수적인 노드를 "필수"로 표기하였으며, 사용에 필수적이지 않은 노드는 "선택사항"으로 표기하였습니다.
- ComfyUI-IPAdapter_Plus : 텍스트-이미지 확산 모델에 이미지 프롬프트 기능을 추가하여 텍스트와 이미지를 결합해 정교한 이미지 생성을 가능하게 하는 경량 어댑터입니다. 이를 통해 사용자는 텍스트와 이미지 조건을 동시에 활용해 다양한 스타일과 주제를 표현하는 이미지 생성이 가능합니다. (필수)
- rgthree's ComfyUI Nodes : 이미지 생성과 편집 작업을 유연하게 수행할 수 있도록 지원하는 노드 세트로, 이미지 비교와 LoRA 모델 로드 등에 사용되었습니다. (선택사항)
3. 모델 다운로드 및 위치 설정
1) 이미지 생성 모델 (SDXL) 파일 다운로드
이미지를 생성할 모델로는 Stability ai에서 배포하는 기본 SDXL 모델을 사용하겠습니다. 이미 해당 모델을 가지고 있거나 다른 커스텀 된 SDXL 모델이 있다면 그 모델을 사용하셔도 됩니다.
- Stabilityai 허깅페이스 : https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/tree/main

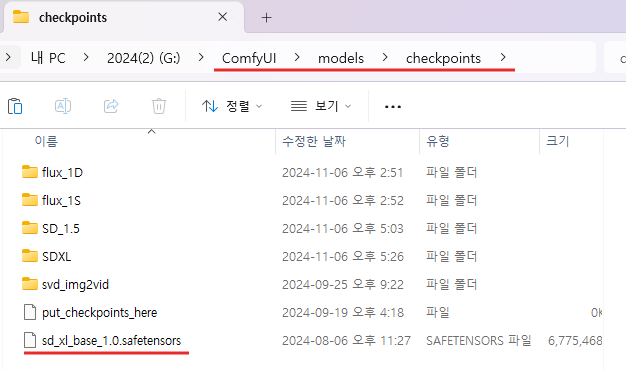
모델 파일 다운로드가 완료되면, 해당 파일을 아래 경로의 checkpoint 폴더로 이동합니다.
(ComfyUI 폴더) → (models 폴더) → (checkpoint 폴더)
2) ClipVision 모델 파일 다운로드
ClipVision 모델 파일은 ComfyUI-Manager를 통해 설치할 수 있습니다. 아래의 절차를 따라 ClipVision 모델 파일을 다운로드하시면 됩니다. 이번 포스팅에서는 CLIP-ViT-H-14-laion2B-s32B-b79K.safetensors 모델을 사용했습니다.
(ComfyUI 실행) → (Manager 실행) → (Model Manager 실행) →
→ (clipvision 검색) → (CLIPVision model (IP-Adapter) 설치)


3) ipadapter 모델 파일과 lora 모델 파일 다운로드
ipadapter 모델 파일과 lora 모델 파일을 아래 깃허브에서 다운받습니다.
- cubiq/ComfyUI_IPAdapter_plus 깃허브 : https://github.com/cubiq/ComfyUI_IPAdapter_plus?tab=readme-ov-file
해당 깃허브에는 다양한 버전의 모델 파일들이 있습니다. 상황에 맞는 버전의 파일을 다운로드 해줍니다. 이번 포스팅에서 사용한 모델은 ip-adapter_sdxl_vit-h.safetensors과 ip-adapter-faceid-plusv2_sdxl_lora.safetensors 모델을 사용했습니다.


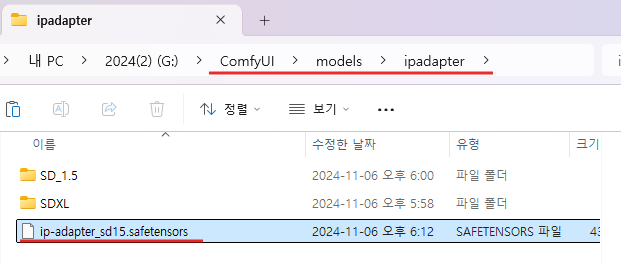
ipadapter 모델 파일 다운로드가 완료되면, 해당 파일을 아래 경로의 ipadapter 폴더로 이동합니다. 해당 폴더가 없는 경우 폴더를 생성해줍니다.
(ComfyUI 폴더) → (models 폴더) → (ipadapter 폴더)
lora 모델 파일 다운로드가 완료되면, 해당 파일을 아래 경로의 loras 폴더로 이동합니다.
(ComfyUI 폴더) → (models 폴더) → (loras 폴더)

4. 노드 구성
노드 구성은 아래와 구성했습니다.

Load Checkpoint 노드는 사전 학습된 Stable Diffusion 모델을 로드하여 이미지 생성의 기반을 마련합니다. 이어서 Power Lora Loader는 특정 Lora 모델을 추가하여 세밀한 제어가 가능하게 하며, 모델이 특정 스타일이나 특징을 반영하도록 돕습니다.
IPAdapter Model Loader와 IPAdapter Advanced는 텍스트와 이미지 프롬프트를 결합하여 참조 이미지의 주제나 스타일을 잘 반영한 일관된 이미지를 생성합니다. 또한, Load CLIP Vision 노드는 이미지의 특징을 학습해 생성 과정에 반영합니다.
Load Image 노드는 참조 이미지로 애니메이션 이미지를 로드하고, CLIP Text Encode 노드들은 긍정적 및 부정적 텍스트 프롬프트를 인코딩하여 이미지 스타일을 조정합니다. Empty Latent Image 노드는 기본 해상도를 설정하고, KSampler는 잠재 공간에서 샘플링을 통해 실제 이미지를 생성합니다.
생성된 잠재 이미지는 VAE Decode 노드를 통해 사람이 인식할 수 있는 이미지로 복원되며, 마지막으로 Save Image 노드가 이를 파일로 저장합니다. 전체 과정은 모델의 사전 학습된 지식과 텍스트, 이미지 프롬프트를 결합해 일관된 스타일의 이미지를 생성하는 방식입니다.
IPAdapter 노드 구성 파일
5. 실행
위 과정을 통해 애니메이션 캐릭터의 일관성을 유지하고 전혀 다른 상황의 이미지를 아래와 같이 생성하였습니다.
- 긍정 프롬프트 : high resolution, ultra-detailed, masterpiece, best quality, very aesthetic, detailed background, 1girl, solo, laughing, riding a bicycle, dutch angle, soft lighting, cherry blossom trees, pink petals falling, spring scenery,
- 부정 프롬프트 : (worst quality:2), (low quality:2), (normal quality:2), lowres, bad anatomy, bad hands, bad position, ((monochrome)), ((greyscale)), watermark, moles


이번 포스팅에서는 IPAdapter를 활용해 애니메이션 이미지의 특징을 학습하고 이를 기반으로 일관된 이미지를 생성하는 과정을 살펴보았습니다. 위에서 설명한 과정을 통해 생성된 이미지를 보면, 원래의 애니메이션 캐릭터와 거의 유사하게 재현된 것을 확인할 수 있습니다. 기술의 발전 덕분에 이제 이렇게 정교하게 스타일을 반영한 이미지 생성이 가능해졌는데요, 여러분이 보시기에는 이 결과가 어떠신가요? 직접 시도해 보시고 원하는 스타일로 재창조된 이미지를 만들어 보는 것도 좋은 경험이 될 것입니다. 앞으로도 다양한 기술을 활용한 이미지 생성 방법을 계속해서 공유하도록 하겠습니다.
감사합니다! 😊



