안녕하세요
오늘은 사진을 생생한 영상으로 변환해주는 AI 모델, Hallo를 소개해드리고자 합니다. Hallo는 단순한 사진을 오디오 음성에 맞춰 실제로 말하는 듯한 동영상으로 만들어주는 획기적인 AI 모델입니다. 이 모델은 지금까지 여러 AI들이 시도했던 입 모양 생성 기술을 뛰어넘어, 가장 현실적이고 자연스러운 결과를 제공합니다. Hallo를 사용하면 마치 사진 속 인물이 실제로 말하는 것처럼 생생한 영상을 만들어낼 수 있습니다. 특히, 이 기술은 영화 제작, 게임 개발, 가상 인플루언서, 언어 학습 도구 등 다양한 분야에서 큰 혁신을 불러올 것입니다. 이제 Hallo AI에 대해 자세히 살펴보겠습니다.
1. Hallo란?
Hallo 모델은 GitHub에서 오픈 소스로 공개된 혁신적인 AI 모델입니다. 이 모델은 이미지 파일과 오디오 파일을 입력으로 받아, 오디오 파일의 음성에 맞게 자연스럽고 현실감 있는 영상을 생성해줍니다. 예를 들어, 특정 인물의 사진과 그 인물이 말하는 음성 파일을 입력하면, 해당 인물이 실제로 그 말을 하고 있는 것처럼 보이는 동영상을 생성할 수 있습니다. 이 모델은 다양한 응용 분야에서 활용될 수 있으며, 특히 영화 제작, 게임 개발, 가상 인플루언서, 언어 학습 도구 등에서 큰 잠재력을 가지고 있습니다. Hallo 모델은 연구자와 개발자가 쉽게 접근하고 활용할 수 있도록 깃허브를 통해 소스 코드와 사용 방법을 자세히 제공하고 있습니다.
아래 영상은 Hallo AI를 활용하여 만들어진 영상 샘플입니다. 영상 속 좌측 아래의 작은 사진이 원본 이미지이고, 이를 음성 파일과 결합하여 영상으로 만들어낸 결과입니다.
Hallo 깃허브 - https://github.com/fudan-generative-vision/hallo
Hallo 모델은 깃허브에서 오픈 소스로 공개된 AI 모델로, 매우 자연스럽고 매끄러운 영상을 생성해줍니다. 지금까지 입 모양을 만들어주는 여러 AI들이 있었으나, 가장 현실적이고 자연스러운 결과를 제공하는 모델은 Hallo라고 생각됩니다.
Hallo 모델은 현재 깃허브에서 MIT 라이센스로 공개되어 있어, 누구나 자유롭게 소스를 열람하고 수정할 수 있으며, 상업적으로도 이용이 가능합니다. 이는 연구자와 개발자뿐만 아니라 상업적 목적으로 사용하는 기업들에게도 큰 장점을 제공합니다. 영화 제작, 게임 개발, 가상 인플루언서 생성, 언어 학습 도구 등 다양한 분야에서 활용될 수 있는 이 모델은, 기술의 발전과 함께 더욱 많은 응용 가능성을 열어주고 있습니다. GitHub 페이지에서는 소스 코드와 더불어 상세한 사용 방법과 예제도 제공하고 있어, 누구나 쉽게 접근하고 활용할 수 있습니다.
주의사항
Hallo AI로 생성한 영상은 현실감 있는 인물 이미지를 제공하여, 딥페이크와 같은 오용 가능성을 포함한 윤리적 문제를 초래할 수 있습니다. 반드시 이 점을 유념해 주시기 바랍니다. AI 기술을 사용할 때는 사회적 책임과 윤리적 기준을 준수하는 것이 중요합니다.
2. 실행환경
- 운영체제 : Windows 11 (64-bit)
- Python : 3.10.14
- conda : 24.5.0
- ONNX Runtime : 1.19.0
- CUDA : 12.5
- GPU : NVIDIA GeForce RTX 4060 Ti
3. Hallo 설치
1) 소스 파일 다운로드
Hallo AI 아래 GitHub에서 오픈 소스로 제공됩니다.
- Hallo 깃허브 : https://github.com/fudan-generative-vision/hallo?tab=readme-ov-file#download-pretrained-models
Hallo 깃허브에 접속하여 모든 파일을 다운받습니다. 코드를 다운받는 방법은 여러 가지가 있으나, 여기서는 압축 파일을 다운받습니다. (아래 이미지 참조) 압축을 풀고 내려받은 폴더를 "Hallo" 폴더로 지정합니다. (폴더명은 임의로 작성)

2) 가상 환경 구축 (Conda 활용)
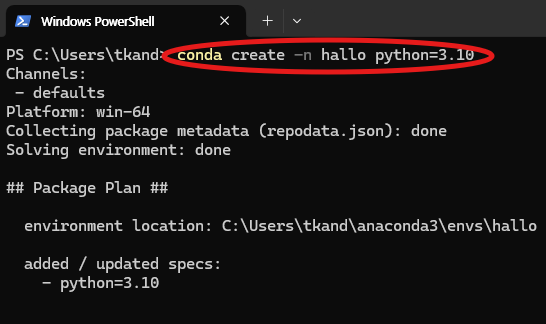
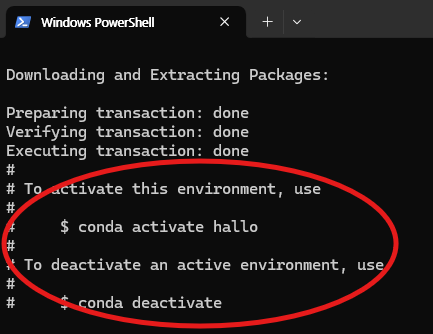
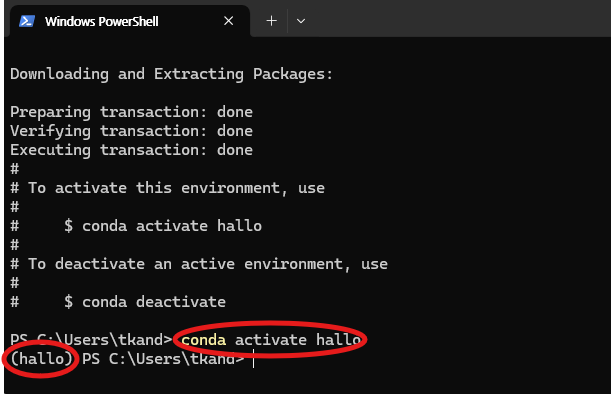
Conda를 활용하여 가상환경을 구축 및 실행 하겠습니다. 아래 명령어를 통해 conda 가상 환경 구축 및 실행시켜 줍니다. 가상환경이 활성화되면 커맨드 왼쪽 "(가상환경 이름)" 형태로 나타나게 됩니다.
conda create -n hallo python=3.10
conda activate hallo
아래 이미지는 위 명령어를 입력하고 정상적으로 실행된 결과의 예시입니다.
3) 패키지 설치
위에서 만든 가상환경에 여러 패키지를 설치해보도록 하겠습니다. 우선 가상환경을 활성화합니다. 이는 가상환경을 사용할 때의 장점, 즉 패키지 간의 충돌 방지 및 독립적인 환경 유지를 활용하기 위함입니다. 이미 활성화한 상태라면 바로 패키지 설치를 진행하시면 됩니다. 패키지 파일은 깃허브에서 다운받은 Hallo폴더(이하 "git_hallo" 폴더)에서 "requirements.txt" 파일을 이용하여 설치합니다. Windows PowerShell의 디렉토리 위치를 Hallo로 이동시켜줍니다. 이동하기 위한 명령어는 아래와 같습니다.
cd [드라이버]:/[폴더명][드라이브]와 [폴더명]은 GitHub에서 Hallo 파일을 다운로드할 때 사용한 드라이브와 폴더명을 말합니다.
아래 이미지는 예시입니다. 위 명령어를 입력하여 [H]드라이버, [Hallo] 폴더로 이동해줍니다.

위치 설정이 완료되면 Windows PowerShell에서 아래 명령어를 실행시켜줍니다.
# Windows PowerShell
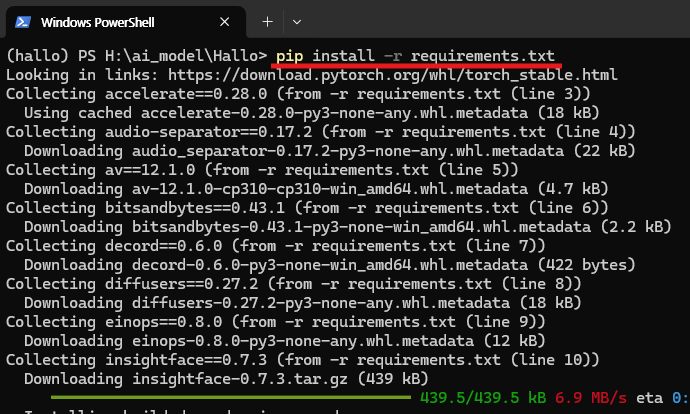
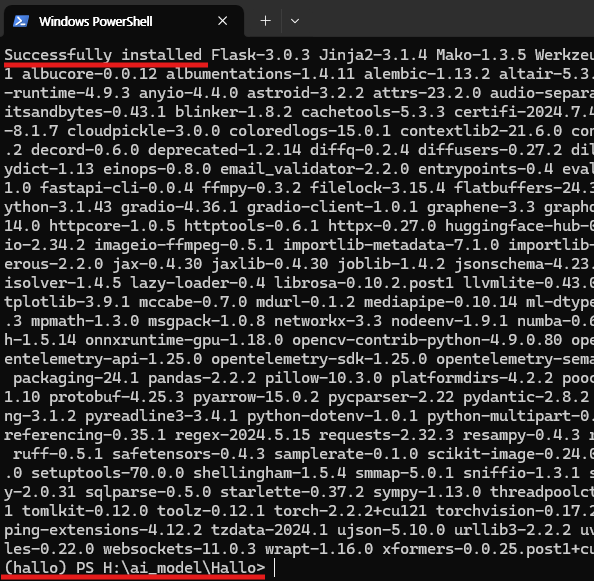
pip install -r requirements.txt
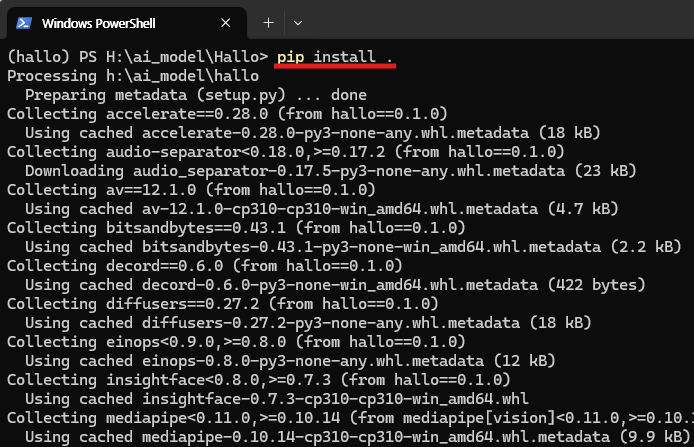
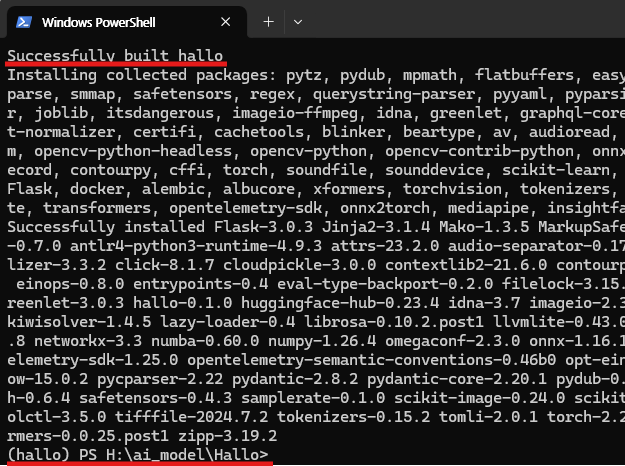
pip install .
※ 참고
( pip install -r requirements.txt )
- 설치 대상: requirements.txt 파일에 명시된 패키지들.
- 사용 시기: 프로젝트의 모든 의존성을 설치할 때.
- 필요 파일: requirements.txt.
( pip install . )
- 설치 대상: 현재 디렉토리에 있는 Python 패키지.
- 사용 시기: 로컬에서 패키지를 개발하거나 테스트할 때.
- 필요 파일: setup.py.
아래 이미지는 위 명령어를 입력하고 정상적으로 실행된 결과의 예시입니다.
4) FFmpeg 설치
FFmpeg는 멀티미디어 데이터를 처리하기 위한 강력하고 유연한 오픈 소스 프레임워크입니다. 주로 비디오와 오디오 파일의 변환, 편집, 스트리밍 등을 위해 사용됩니다. 다양한 멀티미디어 형식을 지원하며, 다양한 플랫폼에서 사용할 수 있습니다.
- 공식 사이트 URL : https://www.ffmpeg.org/download.html
- 구글에서 "ffmpeg" 검색 후 "Download FFmpeg" 클릭
설치를 완료하였으면 아래 명령어를 통해 설치가 완전히 이뤄졌는지 확인하실 수 있습니다.
# Windows PowerShell
ffmpeg -version
아래 이미지는 위 명령어를 입력하고 정상적으로 실행된 결과의 예시입니다.
5) 사전 학습 모델 다운
마지막으로 Hallo를 실행하기 위한 사전 학습된 모델들을 다운받아 줍니다. 해당 모델들은 Hallo HuggignFace에서 다운받으실 수 있습니다.
- Hallo 허깅페이스 : https://huggingface.co/fudan-generative-ai/hallo
허깅페이스에서 다운받는 사전 학습 모델 파일은 (Hallo 폴더) -> (pretrained_models 폴더)에 저장합니다. 이러한 사전 학습 모델 파일은 아래와 같은 형태로 구성되어야 합니다.
./Hallo/
|-- pretrained_models/
| |-- audio_separator/
| |-- download_checks.json
| |-- mdx_model_data.json
| |-- vr_model_data.json
| |-- Kim_Vocal_2.onnx
| |-- face_analysis/
| |-- models/
| |-- face_landmarker_v2_with_blendshapes.task # face landmarker model from mediapipe
| |-- 1k3d68.onnx
| |-- 2d106det.onnx
| |-- genderage.onnx
| |-- glintr100.onnx
| |-- scrfd_10g_bnkps.onnx
| |-- motion_module/
| |-- mm_sd_v15_v2.ckpt
| |-- sd-vae-ft-mse/
| |-- config.json
| |-- diffusion_pytorch_model.safetensors
| |-- stable-diffusion-v1-5/
| |-- unet/
| |-- config.json
| |-- diffusion_pytorch_model.safetensors
| |-- wav2vec/
| |-- wav2vec2-base-960h/
| |-- config.json
| |-- feature_extractor_config.json
| |-- model.safetensors
| |-- preprocessor_config.json
| |-- special_tokens_map.json
| |-- tokenizer_config.json `-- vocab.json
여기까지 준비하셨다면 Hallo 모델 설치가 완료됐습니다.
4. Hallo 실행
동영상을 생성하기 위해 Hallo 모델을 사용하려면, 다음 조건을 충족하는 이미지 파일과 음성 파일을 준비해야 합니다.
소스 이미지
- 정사각형으로 수정해야합니다.
- 이미지의 50%-70%는 얼굴이 나와야합니다.
- 얼굴은 정면을 향해야 하며, 회전 각도는 30° 미만이어야 합니다. (옆모습은 불가)
음성 파일
- 파일 형식 : .WAV
- 훈련 데이터 세트가 영어로만 구성되어 있으므로 영어여야 합니다.
- 보컬이 명확해야 하며, 배경음악은 허용됩니다.
이제, Hallo AI를 사용하기 위해 이미지와 음성 파일을 담을 폴더를 새로 만듭니다. 이미지 파일은 (sample_image
폴더)에, 음성 파일은 (sample_audios 폴더)에 저장합니다. 예시 파일 구성은 아래와 같습니다. 샘플 파일은 Hallo의 GitHub에서 제공하는 데이터를 사용했습니다.

./Hallo/
|-- sample_image/
| |-- 5.jpg
|-- sample_audios/
| |-- 1.wav
폴더명과 파일명은 임의로 설정할 수 있지만, Hallo AI를 실행할 때에는 해당 명령어에 맞게 경로를 수정해주어야 합니다.
파일 준비가 완료됐으면, 아래 명령어를 실행합니다.
# Windows PowerShell
python scripts/inference.py --source_image sample_image/5.jpg --driving_audio sample_audios/1.wav
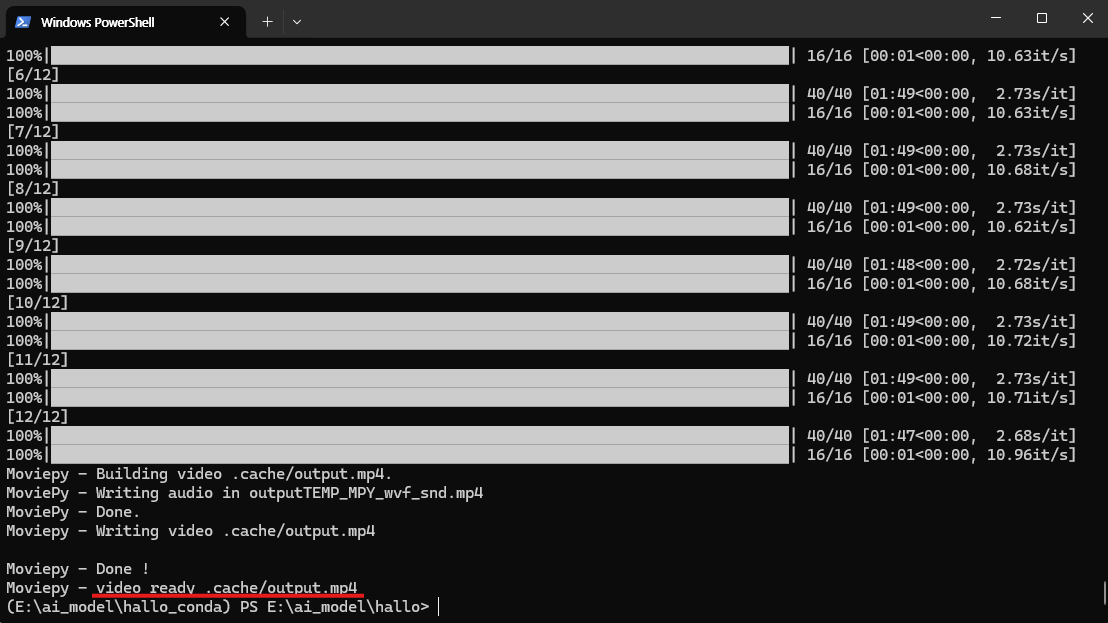
생성된 결과물은 (Hallo 폴더) 안의 (.cache 폴더)에 저장됩니다. 아래 영상은 Hallo AI를 사용해 생성한 예시입니다. 하나의 영상을 만드는 데 약 30분 정도가 소요되었습니다.
이로써 Hallo AI를 활용하여 영상을 만드는 방법에 대해 알아보았습니다.
Hallo 모델은 이미지와 음성을 기반으로 현실감 넘치는 영상을 생성하는 혁신적인 AI 도구입니다. 이 모델은 GitHub에서 오픈 소스로 제공되어 누구나 쉽게 접근하고 활용할 수 있습니다. 특히, 영화 제작, 게임 개발, 가상 인플루언서, 언어 학습 도구 등 다양한 분야에서 큰 잠재력을 가지고 있습니다.
Hallo 모델을 사용하여 동영상을 생성하려면 몇 가지 간단한 단계를 따라야 합니다. 먼저, GitHub에서 소스 파일을 다운로드하고, Conda를 이용해 가상 환경을 설정한 후 필요한 패키지들을 설치합니다. 또한, FFmpeg와 같은 추가 도구를 설치하고 사전 학습된 모델 파일을 준비해야 합니다. 이 모든 과정을 마치면, 준비한 이미지와 음성 파일을 사용해 Hallo 모델로 동영상을 생성할 수 있습니다.
사용자마다 가지고 있는 프로그램 환경이 다르기 때문에, Hallo AI를 실행하기 위해 추가로 설치해야 하는 프로그램이 더 있을 수 있습니다. 저의 경우 위에서는 다루지 않았지만 CUDA, xformers 등의 추가 설치가 필요했습니다. 이러한 프로그램들은 GPU 가속을 활용하여 성능을 최적화하는 데 중요할 수 있습니다. 따라서, 자신의 시스템 환경에 맞는 추가적인 도구들을 설치하고 설정하는 것이 필요할 수 있습니다.
이 글이 Hallo 모델을 시작하는 데 유용한 가이드가 되길 바랍니다. 앞으로도 Hallo 모델과 같은 혁신적인 AI 기술이 우리의 삶을 더욱 풍요롭게 만들기를 기대합니다. 궁금한 점이 있거나 도움이 필요하다면, 댓글을 남겨주세요. 감사합니다!
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [오픈 소스 AI] [로컬 환경] LG 에서 개발한 오픈소스 LLM, EXAONE 3.0을 소개합니다. (2) | 2024.08.16 |
|---|---|
| [영상 생성 AI] [로컬 환경] 오픈 소스 ToonCrafter를 소개합니다. (0) | 2024.07.28 |
| [이미지 생성 AI] Stable Diffusion 로컬 환경에서 사용하기 (0) | 2024.06.14 |
| 오픈소스 EEVE 모델 로컬환경에서 실행하기 3탄 (RemoteRunnable / Streamlit) (1) | 2024.05.28 |
| 오픈소스 EEVE 모델 로컬환경에서 실행하기 2탄 (LangChain / LangServe / ngrok) (0) | 2024.05.17 |



