안녕하세요,
오늘날 인공지능(AI)은 더 이상 특정 산업에 국한된 기술이 아니라, 일상과 업무 전반에 깊이 스며든 핵심 인프라로 자리잡고 있습니다. 생성형 AI의 발전과 함께 언어 이해, 코드 생성, 이미지 분석 등 다양한 영역에서 AI 모델들이 끊임없이 진화하며, 각기 다른 강점을 선보이고 있습니다.
이번 글에서는 AI 모델의 성능을 객관적으로 평가하는 주요 지표와 벤치마크 결과를 중심으로, 어떤 모델이 실제로 우수한 성능과 효율성을 보여주고 있는지 살펴보겠습니다. 이를 통해 서비스 개발이나 업무 자동화에 가장 적합한 AI 모델을 선택하는 데 도움이 될 인사이트를 제공하고자 합니다.
이번 글에서는 최신 LLM의 종합적 성능과 에이전트로서의 실제 문제 해결 능력을 세 가지 핵심 지표를 통해 함께 분석하고자 합니다. 단순히 언어 생성의 정교함을 넘어, 사용자 경험·객관적 성능·실행력의 세 관점에서 모델의 강점을 균형 있게 비교하는 데 초점을 두었습니다.
- 실사용자 투표 기반 순위 (LMArena) : 실제 사용자들이 다양한 모델을 직접 체험한 뒤 선호도를 투표한 결과를 종합한 지표로, 체감 성능과 만족도를 반영하는 가장 현실적인 평가 기준입니다.
- 종합 벤치마크 점수 (Artificial Analysis) : 표준화된 테스트셋을 활용하여 논리적 추론·창의적 문제 해결·멀티모달 이해력등을 수치화한 객관적 평가 지표로, 모델 간 순수 성능 비교에 활용됩니다.
- GAIA 벤치마크 점수 (GAIA Leaderboard) : GAIA는 단순 정답률보다 외부 도구 사용·다단계 사고·상황 기반 문제 해결 능력을 중심으로 모델의 실행력을 평가하는 지표입니다. 따라서 GAIA 점수는 실제 환경에서 모델이 얼마나 ‘행동 가능한 지능(Agentic Intelligence)’을 보여주는지를 판단하는 기준으로 해석할 수 있습니다.
AI 모델 선택 가이드 (전체 요약)
| 활용 목적 | 추천 모델 | 주요 이유 / 특징 |
| 최고 수준의 전반적 성능 | - GPT-5 (high) - GPT-5 Codex (high) |
LMArena·Artificial Analysis 모두에서 최고 점수를 기록한 모델. 언어 이해, 추론, 코딩, 멀티스텝 작업 등 전 영역에서 우수한 성능을 보임. |
| 균형 잡힌 종합형 모델 (성능·비용) | - Gemini-2.5 Pro | Text·WebDev 부문 모두 상위권 유지. 고성능과 효율의 균형이 뛰어나며, 멀티모달 대응력 우수. |
| 언어 이해·서술형 작업 중심 | - Claude 4.1 Opus, - Claude 4.5 Sonnet |
자연어 처리와 논리 전개에 강점. 문서 작성·요약·창의적 글쓰기 등 언어 기반 작업에 적합. |
| 코딩·개발 환경 최적화 | - GPT-5 Codex (high), - Grok 4 Fast |
WebDev 평가 1위권. 코드 생성·디버깅·프레임워크 이해도에서 탁월하며, 개발 효율이 높음. |
| 실시간 응답·경량 운영형 서비스 | - Grok 4 Fast | 응답 속도와 처리 효율이 높아 실시간 번역·대화형 서비스·모바일 AI 환경에 적합. |
| 가성비 중심 연구·프로젝트용 | - GPT-OSS-120B (high), - DeepSeek R1 |
저비용(0.26~1.9 $) 대비 우수한 추론력. 연구·테스트·로컬 서비스 환경에 적합. |
| AI 에이전트 구축 및 협업 시스템 | - Claude Sonnet 4, - Gemini 2.5 Pro |
GAIA 리더보드 상위권 조합. 도구 활용·멀티스텝 플래닝·복합 문제 해결력에서 우수. |
| 로컬 실행·오픈소스 기반 운영 | - GPT-OSS-20B (high), - Llama Nemotron Super 49B v1.5 |
상용 수준 성능을 합리적 비용으로 구현 가능. 커스터마이징 및 로컬 실험 환경에 적합. |
LMArena — Text·WebDev 카테고리 TOP 모델 비교
이번 달에는 LMArena의 Text 및 WebDev 카테고리 모두에서 주요 모델 간의 순위 변동이 일부 관찰되었습니다. 특히 Gemini, Claude, GPT 계열 모델이 여전히 상위권을 유지하고 있으나, GPT-5의 WebDev 성능 향상과 Gemini-2.5-Pro의 사용자 선호도 지속이 주목할 만한 변화로 나타났습니다.
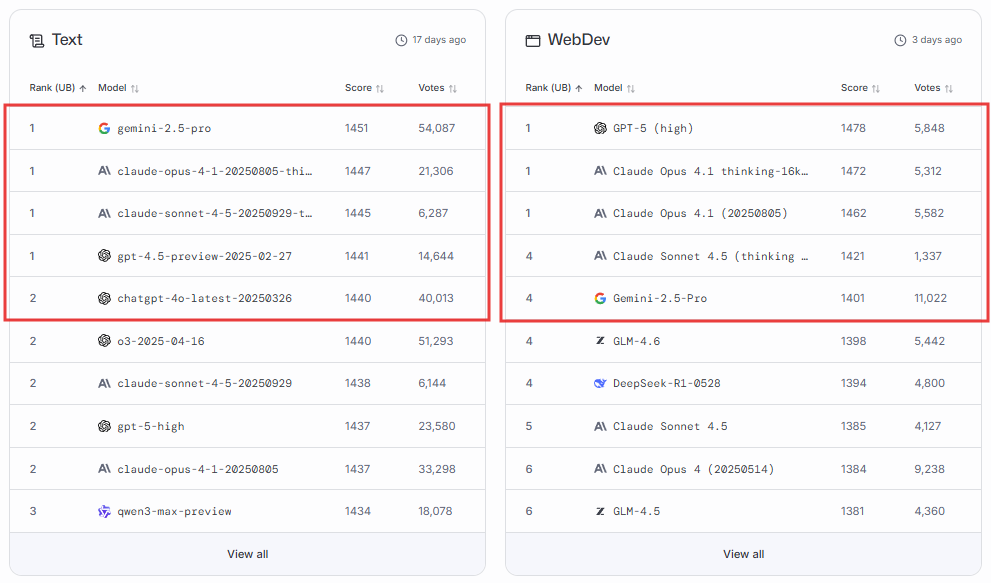
[ Text 모델 성적 ]
Text 카테고리는 모델의 언어 이해력, 논리적 추론, 문맥 유지 능력을 종합적으로 평가하는 영역입니다. 일상 대화, 창의적 글쓰기, 복합 질의응답 등 다양한 상황에서 얼마나 자연스럽고 일관된 응답을 제공하는지를 기준으로 순위가 결정됩니다.
즉, 이 부문은 모델이 언어를 얼마나 완성도 높게 다루고 사용자의 기대에 부합하는 대화를 만들어내는지를 보여주는 핵심 지표입니다.
2025년 10월 17일, LMArena 순위
- Gemini-2.5-Pro — 점수 1451 (54,087표)
- Claude-Opus-4.1-thinking (20250805) — 점수 1447 (21,306표)
- Claude-Sonnet-4.5 (20250929) — 점수 1445 (6,287표)
- GPT-4.5-Preview (20250227) — 점수 1441 (14,644표)
- ChatGPT-4o-Latest (20250326) — 점수 1440 (40,013표)
[요약]
10월 17일 기준, Gemini-2.5-Pro가 Text 부문 1위를 유지하며, 자연스러운 문체와 응답 일관성 측면에서 가장 높은 사용자 만족도를 기록하였습니다. Claude-Opus-4.1과 Claude-Sonnet-4.5는 언어적 세밀함과 문맥 적응 능력에서 여전히 강세를 보이며, GPT-4.5-Preview와 ChatGPT-4o가 그 뒤를 이어 상위권 경쟁을 이어가고 있습니다. 상위 5개 모델의 점수 차이는 불과 11점으로, 사용자 체감 품질이 거의 비슷한 수준임을 보여줍니다.
[ WebDev 모델 성적 ]
WebDev 카테고리는 코드 생성, 디버깅, 프레임워크 이해도 등 실제 개발 환경에서의 효율성을 중심으로 평가됩니다. 개발자의 생산성 향상, 오류 대응 능력, 실행 코드의 품질이 주요 기준으로 반영되며, 모델이 실무 환경에서 얼마나 안정적이고 신속하게 개발 업무를 지원하는지가 핵심 평가 요소입니다.
즉, 이 부문은 개발 편의성·정확도·작업 속도 향상 효과를 종합적으로 보여주는 영역이라 할 수 있습니다.
2025년 10월 31일, LMArena 순위
- GPT-5 (High) — 점수 1478 (5,848표)
- Claude-Opus-4.1-thinking-16k — 점수 1472 (5,312표)
- Claude-Opus-4.1 (20250805) — 점수 1462 (5,582표)
- Claude-Sonnet-4.5 (thinking) — 점수 1421 (1,337표)
- Gemini-2.5-Pro — 점수 1401 (11,022표)
[요약]
10월 31일 기준, WebDev 분야에서는 GPT-5 (High)가 가장 높은 점수를 기록하며, 코드 정확도와 문제 해결 효율성에서 최상위 성능을 보였습니다. Claude-Opus 시리즈는 여전히 안정적인 성능을 유지하며, 장기 맥락 이해 및 코드 구조 파악 능력에서 강점을 유지했습니다. 반면, Text 부문에서는 선두를 지킨 Gemini-2.5-Pro가 이번에도 상위권에 포함되었으나, 개발 분야에서는 상대적으로 낮은 점수(5위)를 기록하여 영역별 차별화가 두드러졌습니다.
[LMArena 결과 종합 요약]
Text와 WebDev 두 카테고리의 결과를 종합하면, 모델별 특화 영역이 더욱 뚜렷해진 흐름을 확인할 수 있습니다.
- Gemini-2.5-Pro는 여전히 자연어 중심 대화에서 최상급 평가를 받으며, 언어적 표현력과 사용자 친화적 응답 품질로 강세를 유지하고 있습니다.
- GPT-5 (High)는 WebDev 분야에서 확실한 우위를 점하며, 개발용 AI 모델의 새로운 기준으로 자리잡고 있습니다.
- Claude-Opus-4.1 시리즈는 두 분야 모두에서 안정적으로 상위권을 유지하며, 균형 잡힌 성능을 가진 범용형 모델로 평가되고 있습니다.
Artificial Analysis — AI 종합 성능 및 비용 비교
Artificial Analysis는 사용자 투표가 아닌 표준화된 벤치마크 테스트를 통해 모델의 언어 이해력, 논리적 추론, 코딩 능력, 수학적 사고력 등을 다각도로 평가합니다. MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode 등 총 10가지 주요 벤치마크 결과를 종합하여 모델의 지적 완성도와 효율성을 함께 비교합니다. 이를 바탕으로 2025년 11월 현재, 최고 성능을 보인 모델과 효율 면에서 주목받는 모델에 대해 살펴보겠습니다.


[AI 종합 성능 지수 TOP 5]
AI 종합 성능 지수는 각 모델이 얼마나 깊이 있는 이해와 논리적 사고를 수행할 수 있는가를 수치로 나타낸 척도입니다. 이 지수는 언어·코딩·수학·복합 문제 해결 능력을 모두 통합해 산출되며, 점수가 높을수록 다양한 상황에서 복잡한 문제를 안정적으로 해결할 수 있는 지능 수준이 높음을 의미합니다.
2025년 11월 기준 순위 (Artificial Analysis)
- GPT-5 Codex (high) — 68점
- GPT-5 (high) — 68점
- Grok 4 — 65점
- Claude 4.5 Sonnet — 63점
- MiniMax-M2 — 61점
[요약]
2025년 11월 기준으로 GPT-5 Codex (high)와 GPT-5 (high)가 공동 1위를 유지하며, 언어 이해력과 코딩·논리적 추론 능력 전반에서 가장 높은 지능 지수(68점)를 기록했습니다. 그 뒤를 xAI의 Grok 4가 65점으로 추격하며, 빠른 처리 속도와 코드 해석 능력에서 강점을 보였습니다. Claude 4.5 Sonnet은 언어적 안정성과 사고력에서 꾸준한 성능을 유지하며 4위를 차지했으며, MiniMax-M2는 61점으로 새롭게 상위권에 진입하며 중국계 모델 중 가장 높은 순위를 기록했습니다. 이번 지표는 상위 모델 간 점수 차가 5~7점 내외로 좁혀지며, AI 모델 간 성능 격차가 점점 미세해지고 있는 흐름을 보여줍니다.
[모델 성능별 비용]
AI 모델을 평가할 때는 단순히 성능 지수만 보는 것이 아니라, 각 성능 수준을 달성하기 위해 필요한 비용 구조를 함께 이해하는 것이 중요합니다. 이번 비교에서는 Artificial Analysis의 ‘Intelligence vs. Cost to Run’(2025년 11월 기준) 데이터를 기반으로, 지능 지수(성능 점수)에 따른 토큰 단가를 함께 정리했습니다.
2025년 11월 기준 순위 (Artificial Analysis)
| 구분 | 성능 지수 |
모델명 | 비용 (10만 토큰당 $) |
설명 |
| 상용 모델 |
60점 이상 |
GPT-5 (high) | 3.44 | 최고 성능이지만 비용이 매우 높아, 연구·프리미엄 서비스용에 적합. |
| GPT-5 Codex (high) | 3.44 | 개발용으로 튜닝된 고비용 모델, 정확도와 안정성이 강점. | ||
| Grok 4 Fast | 0.28 | 낮은 비용(0.28 $) 대비 빠른 처리와 안정적 성능을 갖춘 효율 최상위 모델. | ||
| 60점 미만 |
Gemini-2.5 Pro | 3.44 | 성능과 비용의 균형이 뛰어나 실무용 범용 모델로 적합. | |
| Claude 4.1 Opus | 30.00 | 최고 수준의 언어 품질을 제공하지만 비용(30 $)이 가장 높음. | ||
| 오픈 소스 모델 |
60점 이상 |
MiniMax-M2 | 0.53 | 오픈소스 중 최고 성능(61점)·저비용(0.53 $) 모델, 개발·분석형 워크로드에 효율적. |
| GPT-OSS-120B (high) | 0.26 | 상용급 품질을 0.26 $에 제공하는 초저비용 오픈소스 대형 모델. | ||
60점 미만 |
DeepSeek R1 0528 | 1.98 | 중간 비용(1.98 $)으로 긴 문맥·코드 추론 지원, 실용성 우수. | |
| Llama Nemotron Super 49B v1.5 | 0.17 | 0.17 $ 수준의 초저비용으로 텍스트·코딩 작업에 안정적. | ||
| GPT-OSS-20B (high) | 0.09 | 0.09 $의 최소 비용으로 구동 가능한 초경량 모델, 테스트용에 적합. |
비용 : 비용은 입력(Input) 토큰과 출력(Output) 토큰의 가격을 3:1 비율로 가중 평균하여 계산한 값입니다.
[Artificial Analysis 결과 종합 요약]
2025년 11월 기준, GPT-5 (high)와 GPT-5 Codex (high)가 여전히 가장 높은 지능 지수를 기록하며 전반적인 성능 우위를 이어가고 있습니다. 두 모델 모두 초고품질 응답과 정밀한 추론 능력으로 연구·프리미엄 서비스 환경에 적합한 대표 상용 모델로 평가됩니다.
Claude 4.1 Opus는 여전히 높은 언어 품질과 논리적 일관성을 유지하고 있으나, 30달러/10만 토큰으로 가장 비용이 높은 모델에 속합니다. 반면, Grok 4 Fast는 0.28달러의 낮은 비용 대비 빠른 처리 속도와 우수한 성능을 보여 효율 중심 모델로 주목받고 있습니다.
오픈소스 영역에서는 MiniMax-M2가 61점의 높은 지능 지수와 저비용(0.53달러)을 동시에 달성하며 가장 효율적인 모델로 평가됩니다. GPT-OSS-120B 역시 0.26달러로 상용급 품질을 제공하며, DeepSeek R1 (0528)은 1.98달러의 중간 비용으로 긴 문맥 처리와 코드 추론을 지원해 실용적 모델로 자리하고 있습니다.
전체적으로 GPT-5 시리즈가 성능 절대 우위를 유지하는 가운데, 상용 모델은 정확성과 안정성, 오픈소스 모델은 비용 효율성과 접근성을 중심으로 각자의 경쟁 구도를 형성하고 있습니다.
GAIA 리더보드 – 실제 문제 해결력 평가
GAIA 리더보드는 AI 에이전트가 도구(tool) 활용, 멀티스텝 플래닝, 실시간 정보 검색, 코드 실행 등 실제 업무 시나리오를 얼마나 효과적으로 수행할 수 있는지를 측정하는 지표입니다. 단순한 정답률이 아닌, 현실적 환경에서의 실행력과 적응력을 평가한다는 점에서 의미가 큽니다.
평가 과제는 웹 검색, 데이터 분석, 문서 요약, 복합 추론 등 다양한 실제 업무 단계를 포함하며, 각 에이전트가 이를 얼마나 높은 성공률로 수행하는지를 기준으로 점수가 산출됩니다.
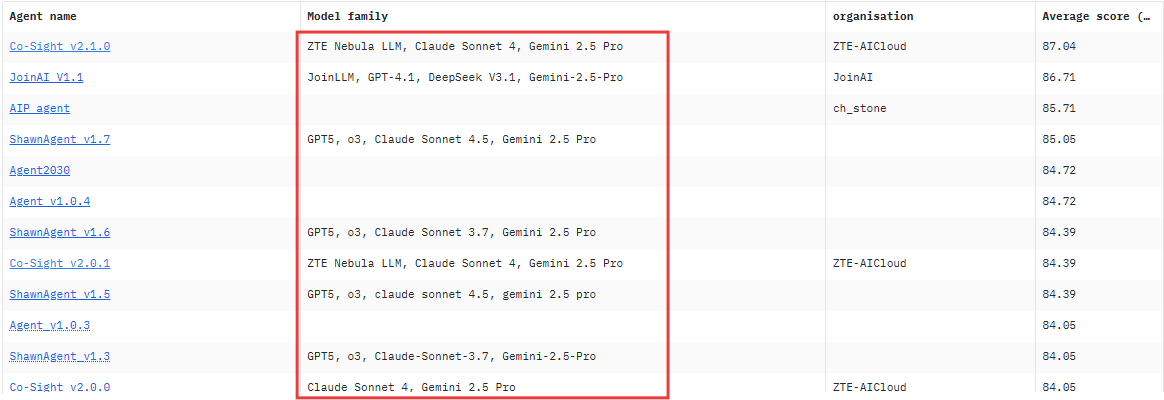
2025년 11월 GAIA 리더보드에서는 여전히 Claude Sonnet 4와 Gemini 2.5 Pro를 결합한 에이전트들이 상위권을 유지하고 있습니다. 특히 ZTE-AICloud의 Co-Sight v2.1.0이 평균 87.04점으로 1위를 기록했으며, JoinAI v1.1(86.71점), AIP Agent(85.71점), ShawnAgent v1.7(85.05점)이 그 뒤를 이었습니다.
이들 상위권 에이전트들은 공통적으로 Claude Sonnet 4·Gemini 2.5 Pro·GPT-5·o3 등의 멀티모델 구성을 활용하고 있으며, 복합 문제 해결과 정보 연계 작업에서 높은 안정성을 보였습니다. 또한 DeepSeek V3.1 기반의 JoinAI 모델도 꾸준히 상위권에 포함되어, 오픈소스 모델의 실무 적용 가능성이 점차 확대되고 있음을 보여줍니다.
[GAIA 결과 요약]
| 에이전트 사용 모델 | 에이전트 활용도 / 성능 요약 |
| Claude Sonnet 4 | 대부분의 상위권 에이전트에서 공통적으로 사용되며, 복합 추론·계획 수립·정보 요약 능력에서 가장 안정적인 성능을 보임. |
| Gemini 2.5 Pro | Claude와 함께 조합된 에이전트들이 평균 85점 이상을 기록하며, 도구 활용·데이터 분석·검색 기반 추론에 강점을 보임. |
| GPT-5 / o3 | ShawnAgent 시리즈 등에서 멀티모델 구조로 포함되어, 코드 실행·복합 연산 처리 능력 향상에 기여함. |
| DeepSeek V3.1 / R1 | JoinAI 등 복합형 에이전트에서 보조 모델로 자주 활용되며, 저비용·고효율형 실시간 추론 지원에 강점을 보임. |
2025년 11월 기준으로 작성된 이번 포스팅은 AI 모델의 벤치마크 성능과 실제 활용성을 함께 분석하여, 목적별 최적의 선택 기준을 제시했습니다. 각 모델은 성능, 비용, 언어 처리 능력, 실행 효율 등에서 뚜렷한 개성을 보이며, 활용 환경에 따라 선택의 기준이 달라집니다. GPT-5 시리즈는 여전히 전반적인 성능에서 독보적 우위를 유지하고 있으며, Claude와 Gemini 계열은 안정성과 실무 적합성 측면에서 우수한 평가를 받고 있습니다. 한편, Grok·MiniMax·DeepSeek·GPT-OSS 계열은 비용 효율성과 유연한 활용성을 기반으로 실용적인 대안으로 자리잡고 있습니다.
이번 내용을 통해 최신 AI 모델들의 특징과 강점을 이해하고, 자신의 서비스·업무·연구 환경에 가장 적합한 모델을 합리적으로 선택하는 데 도움이 되기를 바랍니다.
감사합니다. 😊
[참고 링크]
- 실사용자 투표 기반 (LMArena) : https://lmarena.ai/leaderboard
- 종합 벤치마크 점수 (Artificial Analysis) : https://artificialanalysis.ai/
- GAIA 벤치마크 점수 (GAIA Leaderboard) : https://huggingface.co/spaces/gaia-benchmark/leaderboard
'AI 소식' 카테고리의 다른 글
| AI 입문자를 위한 구글 학습 플랫폼, Google Skills를 소개합니다. (0) | 2025.10.27 |
|---|---|
| 2025년 10월 AI 모델 성능 비교: GPT-5, Claude, Gemini, DeepSeek 최신 순위 정리 (0) | 2025.10.10 |
| GPT-5 Pro와 Sora 2 공개! 2025 OpenAI DevDay 주요 내용 정리 (1) | 2025.10.08 |
| AI 검색 플랫폼 퍼플렉시티, Comet 브라우저와 Search API 공개 (0) | 2025.10.06 |
| 구글이 발표한 AP2: 에이전트 기반 상거래(Agent Commerce)를 위한 오픈 프로토콜 (1) | 2025.09.29 |



