안녕하세요,
사람처럼 자연스럽게 말하고 움직이는 캐릭터를 직접 만들어볼 수 있다면 어떨까요? 이제는 복잡한 기술 없이도 이미지와 음성만으로 말하는 캐릭터 영상을 손쉽게 만들 수 있는 시대가 되었습니다. Meta와 워털루 대학교가 공동 개발한 AI 모델은 누구나 쉽게 캐릭터 애니메이션을 생성할 수 있도록 설계되었습니다. 아직은 개발 초기 단계에 있지만, 현재 공개된 기능만으로도 매우 인상적인 결과를 보여주며 많은 주목을 받고 있습니다.
이번 글에서는 이 모델, MoCha AI의 주요 특징과 사용 방법, 그리고 실제 생성된 결과를 함께 살펴보겠습니다.
MoCha AI 란
MoCha AI는 메타(Meta)와 워털루 대학교의 공동 연구팀이 개발한 차세대 디지털 캐릭터 생성 AI로, 텍스트를 기반으로 애니메이션 캐릭터를 자동 생성하는 기술입니다. 사용자가 입력한 텍스트 설명을 바탕으로, 해당 내용을 시각적으로 표현하는 애니메이션 캐릭터를 자동으로 생성하는 것이 핵심 기능입니다.
- MoCha AI 공식페이지 : https://www.mocha-ai.org/
기존의 캐릭터 애니메이션은 고도의 정밀성과 많은 노동력을 요구하는 작업이었지만, MoCha는 이 과정을 AI 기반으로 자동화하여, 영화 수준의 고품질 결과물을 빠르게 생성할 수 있도록 합니다. 이 기술은 단순히 입 모양만을 맞추는 기존의 "talking head" 방식에서 한 단계 나아가, 음성 및 자연어 입력만으로도 전신 동작, 감정 표현, 입 모양 동기화가 가능한 디지털 캐릭터를 만들어냅니다. 또한, 클로즈업부터 와이드샷까지 다양한 카메라 앵글을 지원하며, 하나의 장면에서 여러 캐릭터가 자연스럽게 상호작용하는 것도 구현할 수 있습니다.
주요 특징
- 텍스트-투-애니메이션 생성 : 사용자가 입력한 텍스트를 이해하고, 해당 내용을 반영한 캐릭터, 동작, 감정 표현, 카메라 구도까지 포함된 풀바디(full-body) 애니메이션 자동 생성
- 음성 및 텍스트 기반 애니메이션 : 음성 오디오와 텍스트 프롬프트를 함께 활용하여, 캐릭터의 입 모양, 표정, 몸짓, 감정 표현을 자연스럽게 연출
- 사실적인 립싱크 및 감정 표현 : 입력된 음성과 일치하는 정밀한 립싱크를 구현하고, 텍스트 내용과 음성의 뉘앙스를 반영한 자연스러운 표정 및 감정 표현 생성
- 자연스러운 전신 동작 생성 : 단순 얼굴 표현을 넘어, 인물의 움직임을 맥락에 맞게 연출하는 유기적이고 부드러운 전신 애니메이션 생성
- 다중 캐릭터 상호작용 지원 : 하나의 장면에서 여러 캐릭터가 등장하여 턴 기반 대화를 주고받으며, 상황에 맞는 자연스러운 상호작용 연출 가능
MoCha 성능
MoCha 모델은 다양한 장면에서 자연스럽고 정교한 디지털 캐릭터 애니메이션을 구현하는 데 있어 뛰어난 성능을 보입니다. 다른 영상 생성 모델들과 비교해도 현재 가장 우수한 결과를 나타내며, 이는 MoChaBench Leaderboard의 점수를 통해 명확히 확인할 수 있습니다.
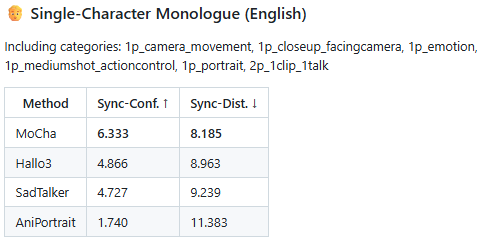
왼쪽 리더보드는 단일 인물의 영어 모놀로그(독백) 장면에서의 성능을 비교한 것으로, MoCha는 다른 모델들(Hallo3, SadTalker, AniPortrait)보다 가장 높은 동기화 신뢰도(Sync-Conf. 6.333)와 가장 낮은 동기화 거리(Sync-Dist. 8.185)를 기록했습니다. 이는 음성과 입 모양의 정확한 일치를 구현하며, 립싱크와 표정 연출에서 MoCha가 매우 뛰어난 정밀도를 갖추고 있음을 보여줍니다.
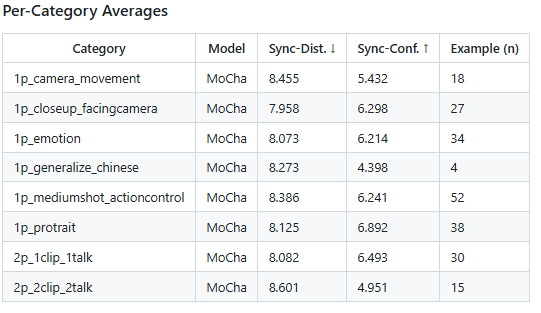
오른쪽 리더보드는 MoCha의 성능을 장면 유형별로 나누어 평가한 결과를 담고 있습니다. 카메라 이동, 클로즈업, 감정 표현, 전신 동작 제어, 다자간 대화 등 총 8가지 카테고리에서 평가되었으며, 각 항목별 평균 동기화 거리와 신뢰도 점수가 기록되어 있습니다. MoCha는 모든 항목에서 고르게 안정적인 성능을 보였으며, 특히 감정 표현(1p_emotion), 정면 클로즈업(1p_closeup_facingcamera), 포트레이트 장면(1p_portrait)에서 높은 동기화 신뢰도를 기록해 표정 및 감정 전달 능력이 매우 우수함을 확인할 수 있습니다.
MoCha AI 체험하기
MoCha AI는 현재 아래 링크를 통해 직접 사용해볼 수 있습니다.
- MoCha AI 체험해보기 : https://www.mocha-ai.org/human-like
[사용 방법]
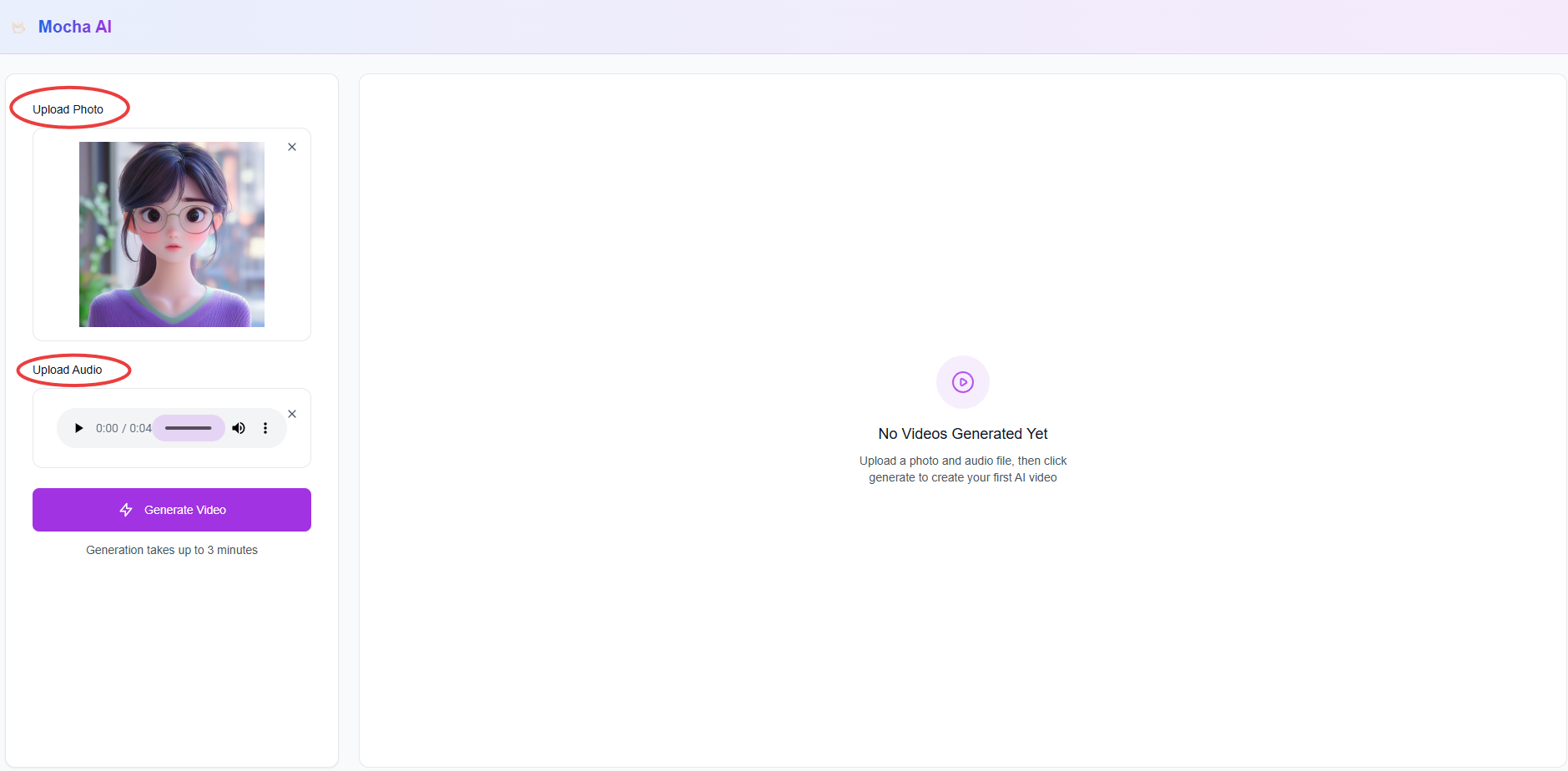
MoCha AI는 매우 간단한 절차로 말하는 캐릭터 영상을 생성할 수 있습니다. 먼저, 화면 왼쪽의 ‘Upload Photo’ 항목에서 원하는 인물 이미지를 업로드합니다. 애니메이션 스타일이든 실사 스타일이든 상관없이 사용할 수 있으며, 별도로 준비한 이미지가 없다면 기본으로 제공되는 샘플 이미지를 그대로 사용해도 됩니다. 그다음, ‘Upload Audio’ 항목에서 캐릭터가 말할 음성 파일을 업로드합니다. 사용자 목소리나 대사 음성을 사용할 수 있고, 마찬가지로 직접 준비한 파일이 없을 경우 기본 제공 음성을 사용할 수 있습니다. 이미지와 음성을 모두 업로드한 뒤에는 ‘Generate Video’ 버튼을 클릭하면 업로드한 이미지가 음성에 맞춰 자연스럽게 말하는 영상이 자동으로 생성됩니다.
[영상 생성]
두 가지 유형의 이미지를 사용하여 MoCha AI를 활용해 영상을 생성했습니다. 하나는 실사에 가까운 인물 이미지, 다른 하나는 애니메이션 스타일의 인물 이미지였으며, 각각의 이미지에 맞춰 자연스럽게 말하는 캐릭터 영상이 자동으로 생성되었습니다. 음성은 MoCha에서 기본으로 제공하는 오디오 파일을 사용했으며, 별도의 편집 없이 이미지와 음성만으로도 고품질의 결과물이 만들어졌습니다.
[사용 이미지]


[생성 영상]
지금까지 사용해본 다양한 영상 생성 모델 중에서, MoCha AI가 만들어낸 결과물이 가장 자연스럽게 느껴졌습니다. 입 모양의 움직임과 표정 변화 등 전반적으로 매우 정교하게 구현되었습니다. 생성 속도 또한 인상적이었습니다. 약 4초 분량의 영상이 5초 이내로 빠르게 생성되었으며, 기다림 없이 곧바로 결과물을 확인할 수 있었습니다.
MoCha AI는 아직 정식 출시 전임에도 불구하고, 매우 우수한 성능을 보여주고 있습니다. 이미지와 음성만으로 생성된 캐릭터의 립싱크, 표정, 동작이 놀라울 정도로 자연스럽고 완성도 높게 구현되었습니다. 정식 버전이 출시된다면 어떤 모습일지 더욱 기대되며, MoCha AI는 향후 디지털 캐릭터 생성 기술의 새로운 기준이 될 수 있는 충분한 가능성을 보여주고 있습니다.
감사합니다. 😊
'AI 소식' 카테고리의 다른 글
| Gemini Diffusion이란? 구글 딥마인드의 차세대 AI 언어 모델 (0) | 2025.06.20 |
|---|---|
| WWDC25 요약, Apple Intelligence로 본 애플 AI 전략의 미래 (3) | 2025.06.12 |
| Gemini 2.5 Pro, Claude 제치고 1위! 웹개발에 강한 AI는? (4) | 2025.05.21 |
| 스스로 학습하는 AI 모델, Absolute Zero Reasoner에 대해 소개합니다. (1) | 2025.05.14 |
| 앞으로의 AI는 어떻게 달라질까? 핵심은 A2A와 MCP (0) | 2025.05.09 |



