안녕하세요,
최근, 굉장히 작은 크기임에도 불구하고 고품질의 대화 음성을 생성할 수 있는 오픈 소스 모델이 새롭게 등장했습니다. 이 모델은 가벼운 성능과 뛰어난 음질을 동시에 갖추고 있어, 음성 합성이나 대화형 AI 프로젝트에 관심 있는 개발자들에게 큰 주목을 받고 있습니다.
이번 포스팅에서는 이 모델의 주요 특징과 사용 방법에 대해 알아보겠습니다.
Dia AI란
Dia는 Nari Labs에서 개발한 1.6억 파라미터 규모의 오픈 웨이트 텍스트-투-스피치(TTS) 모델입니다. 대화형 스크립트를 입력받아 한 번에 자연스럽고 감정이 풍부한 음성을 생성할 수 있도록 설계되었습니다. 오디오 프롬프트를 통해 목소리의 감정과 톤을 세밀하게 조정할 수 있으며, 웃음소리나 박수소리 같은 다양한 비언어적 표현도 만들어낼 수 있습니다. 현재는 영어만 지원하지만, 향후 다국어 확장이 예정되어 있어 더욱 기대를 모으고 있습니다.
- Dia 프로젝트 페이지 : https://yummy-fir-7a4.notion.site/dia

주요 특징
- 우수한 성능의 소형 모델 : 약 16억 개(1.6B) 파라미터를 가진 소형 TTS 모델입니다. 비록 파라미터 수는 적지만, 매우 자연스럽고 감정 표현이 풍부한 대화형 음성을 생성할 수 있습니다.
- 대화 스크립트 전체 합성 : 대화 스크립트를 한 번에 처리하여, 문맥과 흐름이 자연스럽게 이어지는 음성을 생성할 수 있습니다. 오디오북, 드라마, 팟캐스트 등 몰입감이 필요한 콘텐츠에 적합합니다.
- 다중 화자 지원 : 텍스트 내 [S1], [S2] 등 화자 구분 태그를 사용해 여러 인물의 대화를 동시에 합성할 수 있습니다.
- 감정 및 목소리 스타일 조정 : 오디오 프롬프트를 통해 화자의 감정(기쁨, 슬픔, 분노 등)과 목소리 스타일을 세밀하게 조정할 수 있어, 더욱 풍부한 음성 표현이 가능합니다.
- 비언어적 효과음 삽입 : 텍스트 중간에 (laughs), (coughs) 등의 비언어적 표현을 삽입하면 실제 효과음처럼 자연스럽게 합성할 수 있습니다.
- 음성 클로닝 기능 : 짧은 음성과 텍스트를 입력하면 특정 인물의 목소리 스타일을 복제할 수 있습니다. (단, 저작권 및 초상권 문제 주의)
- 오픈소스 및 쉬운 접근성 : Apache 2.0 라이선스로 공개되어 누구나 자유롭게 사용할 수 있으며, Hugging Face Space를 통해 설치 없이 웹에서 체험할 수 있습니다.
주의 사항
Dia 모델은 Apache License 2.0 하에 배포되어 자유롭게 사용할 수 있으나, AI 기술의 책임 있는 활용을 위해 다음 사항을 반드시 준수해 주시기 바랍니다. 아래 내용은 Dia 프로젝트 개발팀에서 제시한 지침으로, 모델 사용 시 다음과 같은 행위는 삼가 주시기 바랍니다.
- 신원 도용 금지: 본인의 동의 없이 실제 인물을 모방하거나 유사한 음성을 생성하지 마십시오.
- 허위 정보 생성 금지: 가짜 뉴스나 오해를 불러일으킬 수 있는 콘텐츠를 생성하는 데 사용하지 마십시오.
- 불법 및 악의적 사용 금지: 법률을 위반하거나 타인에게 피해를 주는 목적으로 사용하지 마십시오.
AI 기술은 모두의 신뢰를 바탕으로 발전해 나가야 합니다. 우리 모두가 AI를 사용할 때 법적, 윤리적 기준을 준수하는 책임 있는 자세를 가져야 하며, 이를 통해 AI 기술이 더욱 건강하고 지속적으로 성장할 수 있도록 함께 노력해야 합니다.
라이선스
Dia는 Apache License 2.0 하에 오픈소스로 공개되었습니다. 이 라이선스는 매우 관대한 조건을 제공하여, 누구나 자유롭게 소스코드를 사용하고 수정할 수 있으며, 연구, 비상업적 용도는 물론 상업적 활용까지 제한 없이 허용됩니다. 이를 통해 개발자와 연구자들은 Dia 모델을 기반으로 다양한 실험과 응용은 물론, 실제 제품이나 서비스에도 자유롭게 적용할 수 있습니다.
목차
1. 실행 환경
2. Dia-1.6B 모델 설치
3. Dia-1.6B 모델 실행
1. 실행 환경
- 운영체제 : Windows 11
- Python : 3.10.0
- torch : 2.6.0 + cu126
- GPU : NVIDIA GeForce RTX 4060 Ti
2. Dia-1.6B 모델 설치
Dia 모델은 현재 허깅페이스와 깃허브에 "Dia-1.6B" 버전의 모델과 코드가 공개되어 있습니다. 이번에는 이 모델을 활용해 로컬 환경에 설치하고, 음성을 생성하는 방법을 살펴보겠습니다.
1) Dia-1.6B 코드 다운로드
아래 링크에서 제공되는 파일을 모두 다운로드해주세요.
- Dia-1.6B 깃허브: https://github.com/nari-labs/dia?tab=readme-ov-file
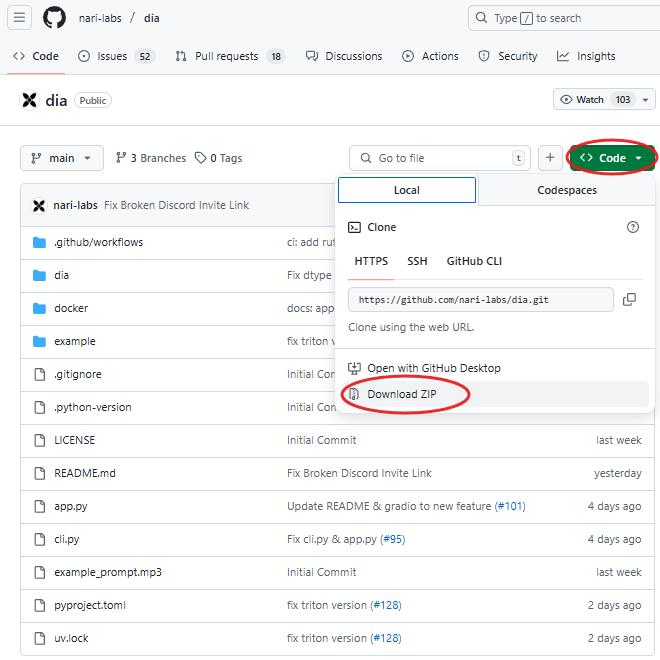
2) 가상 환경 설치 (선택사항)
프로젝트를 보다 깔끔하고 안정적으로 관리하기 위해 가상 환경을 생성하는 것을 권장합니다. 가상 환경을 사용하면 시스템 파이썬 환경과 독립적으로 패키지를 설치하고 관리할 수 있어, 프로젝트 간 패키지 충돌을 방지할 수 있습니다.
아래 명령어를 통해 가상 환경을 생성할 수 있습니다.
# Windows PowerShell
cd /path/to/dia # 깃허브에서 다운받은 폴더로 이동
python -m venv .venv # 가상 환경 생성
.\.venv\Scripts\Activate.ps1 # 가상 환경 실행
가상 환경을 성공적으로 활성화하면, 아래 이미지처럼 입력창 왼쪽에 "(.venv)" 가 표시됩니다. 이 표시가 보인다면 가상 환경이 정상적으로 설치 및 실행된 것입니다.

3-1) 필수 패키지 설치 및 실행
아래 명령어를 통해 Dia-1.6B 모델을 실행하는 데 필요한 필수 패키지를 설치하고, 모델을 실행할 수 있습니다. app.py 파일을 실행하면 Dia-1.6B 모델이 로드되며, 로컬에 모델 파일이 없는 경우 자동으로 다운로드가 시작됩니다. 다운로드가 완료되면 최종적으로 Dia-1.6B 모델이 작동하는 서버가 실행됩니다.
# Windows PowerShell
pip install -e . # 필수 패키지 설치
python app.py # dia-1.6B 모델 실행
3-2) GPU 실행 환경 (선택사항)
모델을 더 빠르고 효율적으로 실행하고자 할 경우, GPU 환경을 사용하는 것을 권장합니다. 특히 Dia-1.6B 모델은 음성 합성 시 연산량이 많기 때문에, GPU를 활용하면 음성 생성 속도와 응답성이 크게 개선됩니다. 아래 명령어를 통해 CUDA 12.6 환경에 최적화된 GPU 버전의 PyTorch 패키지를 설치할 수 있습니다.
# Windows PowerShell
pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
(참고사항)
- 위 명령어는 CUDA 12.6 버전에 최적화되어 있으므로, 사용 중인 GPU 드라이버가 CUDA 12.6을 지원하는지 미리 확인하는 것을 권장합니다.
- CUDA 드라이버가 설치되어 있지 않거나 버전이 맞지 않을 경우, GPU 가속이 정상적으로 동작하지 않을 수 있습니다.
3. Dia-1.6B 모델 실행
아래 이미지는 Dia-1.6B 모델이 정상적으로 실행된 화면입니다. Input Text 입력창에 생성할 대화 텍스트를 입력하면 음성 합성이 진행됩니다. 이번 테스트에서는 다음과 같은 프롬프트를 입력하여 실험을 진행했습니다.
[입력 프롬프트]
[S1] Hi, my name is Marcus. (clears throat) Nice to meet you.
[S2] Oh, hi! Nice to meet you.
[S1] (coughs) Sorry, I think I'm catching a cold.
[S2] Oh no, I hope you feel better soon!

[음성 생성 결과]
해당 모델을 통해 음성을 생성하는 과정에서 VRAM은 약 5.2GB가 사용되었으며, 약 50초 만에 음성 생성이 완료되었습니다. [S1]과 [S2] 태그를 활용하여 화자를 구분할 수 있었고, 특히 [S1]에서는 목소리 다듬기(clears throat)와 기침(coughs)과 같은 비언어적 표현이 매우 자연스럽게 재현되었습니다. 16억 파라미터 규모의 소형 모델임에도 불구하고 이 정도로 높은 품질의 음성을 생성할 수 있다는 점이 매우 인상적이었습니다.
또한, 이 모델을 활용하여 덴젤 워싱턴 배우의 목소리 스타일을 재현해보았습니다. 개인적으로 들어본 결과, 실제 목소리와 상당히 유사하게 느껴졌습니다.
지금까지 Dia-1.6B 모델을 로컬 환경에 설치하고 실행하는 방법에 대해 알아보았습니다. Dia는 자연스럽고 감정이 풍부한 대화형 음성을 생성할 수 있는 강력한 TTS 모델로, 연구 및 다양한 실험에 폭넓게 활용할 수 있는 높은 잠재력을 지니고 있습니다. 16억 파라미터 규모의 비교적 작은 모델임에도 불구하고, 특정 목소리 스타일을 자연스럽게 재현해내는 능력이 인상적이었으며, 다양한 감정 표현과 비언어적 소리까지 세밀하게 표현할 수 있다는 점이 특히 돋보였습니다. 또한, GPU 환경을 활용할 경우 모델을 더욱 빠르고 효율적으로 실행할 수 있어, 실시간 응용이나 대규모 음성 생성 작업에도 충분히 활용 가능성을 기대할 수 있습니다.
앞으로 다국어 지원과 기능 확장이 예정되어 있는 만큼, 한국어를 포함한 다양한 언어로 자연스러운 대화를 생성하는 기능 또한 기대해볼 수 있습니다. Dia 모델의 발전과 함께 더욱 풍부한 음성 생성 기술이 다양한 분야에서 활용되기를 기대합니다.
읽어주셔서 감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [오픈소스 AI] Qwen3 모델 사용법|로컬 환경에서 직접 실행하기 (3) | 2025.05.16 |
|---|---|
| [오픈 소스 AI] 한국어 최적화 오픈소스 AI, HyperCLOVA X SEED 설치 및 활용 가이드 (1) | 2025.05.06 |
| 마이크로 소프트에서 개발한 CPU만으로 작동하는 초경량 AI, Bitnet을 소개합니다. (1) | 2025.04.24 |
| [오픈 소스 AI] Meta가 공개한 최신 AI 모델, Llama 4를 소개합니다. (0) | 2025.04.15 |
| [오픈 소스 AI] 하나의 모델로 텍스트·이미지·음성·비디오를 모두 처리하는 AI 모델, Qwen 2.5 Omni를 소개합니다. (1) | 2025.04.12 |



