안녕하세요,
최근 인공지능 모델은 텍스트 기반 기능을 넘어, 음성과 같은 다양한 형태의 데이터를 자연스럽게 생성하고 제어하는 방향으로 빠르게 발전하고 있습니다. 특히 실제 사람과 유사한 음성을 생성하고, 말투와 감정까지 조절할 수 있는 음성 생성 모델이 등장하면서, 음성 인터페이스와 AI 서비스 전반의 활용 범위가 점차 확대되고 있습니다. 이러한 흐름 속에서 OpenBMB는 차세대 음성 생성 모델인 VoxCPM2를 공개했습니다.
이번 글에서는 VoxCPM2 모델의 개념과 주요 특징, 벤치마크 성능, 그리고 간단한 사용 방법에 대해 알아보겠습니다.
VoxCPM2 모델이란
2026년 4월, OpenBMB에서 차세대 음성 생성 모델 VoxCPM2를 공개했습니다. 이 모델은 텍스트를 자연스러운 음성으로 변환하는 TTS(Text-to-Speech) 작업을 중심으로 설계된 음성 생성 모델입니다. 기존 음성 합성 모델이 텍스트를 음소나 이산 토큰으로 변환한 뒤 음성을 생성하는 방식을 사용한 것과 달리, VoxCPM2는 연속적인 음성 표현 공간에서 직접 음성을 생성하는 구조를 채택하고 있습니다. 이를 통해 중간 변환 과정에서 발생할 수 있는 정보 손실을 줄이고, 보다 자연스러운 발화와 억양 표현을 가능하게 합니다. 또한 단순한 텍스트 음성 변환을 넘어, 텍스트와 음성 입력을 함께 활용하는 구조를 기반으로 음성 생성, 보이스 클로닝, 스타일 제어 등 다양한 음성 기반 작업을 하나의 모델에서 수행할 수 있도록 확장된 형태를 갖추고 있습니다.
- VoxCPM2 소개 페이지 : https://openbmb.github.io/voxcpm2-demopage/
VoxCPM2 Demo Page
Abstract: VoxCPM2 is a tokenizer-free Text-to-Speech system built on an end-to-end diffusion autoregressive architecture (LocEnc → TSLM → RALM → LocDiT), bypassing discrete tokenization to achieve highly natural and expressive synthesis. Based on a M
openbmb.github.io
[모델 정보 요약]
| 항목 | 내용 |
| 모델명 | VoxCPM2 |
| 개발사 | OpenBMB |
| 모델 유형 | 음성 생성 모델 (TTS / Speech Generation) |
| 파라미터 구조 | 약 2B (20억 파라미터) |
| 아키텍처 | Transformer 기반 음성 생성 구조 |
| 지원 입력 (Input) | 텍스트, 음성 |
| 지원 출력 (Output) | 음성 |
| 주요 특징 | - 토큰화 없이 직접 음성 생성 - 보이스 클로닝 지원 - 스타일 제어 가능 - 다국어 지원 (한국어 포함) |
| 사용 환경 | 서버 환경, GPU 기반 추론, 음성 서비스 시스템 |
| 라이선스 | Apache-2.0 |
| 모델 경로 | Hugging Face 제공 |
주요 특징
- 토크나이저 없이 음성을 직접 생성하는 구조 : VoxCPM2는 기존 TTS 모델에서 일반적으로 사용되던 음소 또는 이산 토큰 기반 방식 대신, 연속적인 잠재 공간에서 직접 음성을 생성하는 구조를 사용합니다. 이 방식은 정보 손실을 줄이고, 보다 자연스러운 발화와 감정 표현을 구현하는 데 기여합니다.
- 다국어 음성 생성 및 높은 음질 지원 : 다양한 언어 데이터를 기반으로 학습되어 여러 언어 환경에서 자연스러운 음성 생성이 가능하며, 고해상도 음성 출력(48kHz 수준)을 통해 실제 서비스 환경에서도 활용 가능한 품질을 제공합니다.
- 음성 스타일 제어 및 보이스 디자인 : 텍스트 입력만으로도 목소리의 특성(톤, 감정, 스타일 등)을 지정할 수 있으며, 이를 통해 특정 캐릭터나 상황에 맞는 음성을 생성할 수 있습니다. 단순 음성 생성을 넘어, “어떤 목소리로 말할 것인지”까지 제어할 수 있는 구조를 제공합니다.
- 정밀한 보이스 클로닝 기능 : 짧은 참조 음성만으로도 특정 화자의 목소리를 재현할 수 있으며, 감정이나 말하는 속도까지 조절 가능한 클로닝 기능을 제공합니다. 텍스트와 음성 정보를 함께 활용하는 경우, 음색뿐 아니라 리듬과 표현 방식까지 더욱 정밀하게 복제할 수 있습니다.
- 확장 가능한 멀티모달 기반 구조 : 텍스트와 음성을 동시에 처리할 수 있는 구조를 기반으로, 음성 생성뿐 아니라 다양한 음성 기반 응용 작업으로 확장이 가능합니다. 이는 단일 기능 모델이 아닌, 음성 중심 AI 시스템으로 활용될 수 있는 기반을 제공합니다.
- 실시간 활용을 고려한 성능 최적화 : 고성능 GPU 환경에서는 실시간에 가까운 속도로 음성 생성이 가능하도록 설계되어, 인터랙티브 서비스나 실시간 음성 응답 시스템에도 적용할 수 있는 수준의 성능을 제공합니다.
벤치마크 성능
VoxCPM2는 다양한 벤치마크에서 음성 유사도와 자연스러움 측면에서 강점을 보입니다. 특히 SIM(생성된 음성이 원본 화자의 음색·억양과 얼마나 유사한지를 평가하는 지표)에서 높은 값을 기록하며, 실제 화자에 가까운 자연스러운 음성 표현에 유리한 구조를 갖고 있습니다. 또한 다국어 평가에서도 안정적인 오류율을 유지하며, 특정 언어에 치우치지 않는 균형 잡힌 성능을 제공합니다. 이와 함께 스타일 제어 지표에서도 우수한 결과를 보이며, 자연스러운 음성과 표현력까지 함께 고려된 모델로 정리할 수 있습니다.
아래 표는 VoxCPM2 모델에 대한 벤치마크 결과입니다.
| 벤치마크 지표 | 세부 지표 | VoxCPM2 | Qwen3-TTS | FishAudio S2 |
| Seed-TTS-eval (제로샷 음성 생성 품질 평가) |
EN WER ↓ (영어 발음 오류율, 낮을수록 정확) |
1.84 | 1.23 | 0.99 |
| EN SIM ↑ (영어 음성 유사도, 높을수록 자연스러움) |
75.3 | 71.7 | - | |
| Hard CER ↓ (난이도 높은 문장 오류율, 낮을수록 우수) |
8.13 | 6.76 | 5.99 | |
| Hard SIM ↑ (복잡 문장 음성 유사도) | 75.3 | 74.8 | - | |
| CV3-eval (다국어 발음 오류율 평가) |
en WER ↓ (영어 오류율, 낮을수록 우수 ) | 5.00 | - | 2.43 |
| ko WER ↓ (한국어 오류율, 낮을수록 우수 ) | 5.69 | - | 2.76 | |
| Minimax MLS (다국어 음성 정확도 평가) |
English WER ↓ (영어 단어 오류율) | 2.289 | 0.934 | 1.620 |
| Korean WER ↓ (한국어 단어 오류율) | 1.962 | 1.755 | 1.180 | |
| English SIM ↑ (영어 음성 유사도) | 85.4 | 77.5 | 79.7 | |
| Korean SIM ↑ (한국어 음성 유사도) | 83.3 | 79.9 | 81.7 | |
| Internal 30-Lang (30개 언어 내부 평가) |
EN WER ↓ (영어 발음 오류율) | 0.42% | - | 1.03% |
| KO CER ↓ (한국어 문자 오류율) | 0.95% | - | 0.29% |
출처: Openbmb 깃허브
라이선스
VoxCPM2는 Hugging Face 및 GitHub를 통해 Apache 2.0 License로 공개되어 있습니다. 이 라이선스는 연구 목적뿐 아니라 상업적 활용까지 허용하는 오픈소스 라이선스로, 다양한 서비스 환경에서 유연하게 적용할 수 있는 구조를 제공합니다. 개인 프로젝트부터 기업 서비스까지 별도의 제약 없이 활용할 수 있으며, 모델 수정 및 재배포 또한 가능합니다.
Apache 2.0 License의 주요 특징은 다음과 같습니다.
- 연구 및 상업적 사용 모두 허용
- 모델 수정 및 파생 모델 생성 가능
- 재배포 및 배포 가능 (라이선스 및 저작권 고지 유지 필요)
- 특허 사용 권한(Patent Grant) 제공
- 개인, 기업, 서비스 등 다양한 환경에서 활용 가능
이 라이선스는 상업적 활용과 배포를 명확하게 허용하면서, 특허 권리까지 포함하고 있어 안정적인 서비스 구축과 확장이 가능한 오픈소스 라이선스 형태입니다.
주의사항
VoxCPM2는 강력한 음성 생성 및 보이스 클로닝 기능을 제공하는 모델로, 사용 시 책임 있는 활용이 요구됩니다. 특히 타인을 사칭하거나, 사기, 허위 정보 생성과 같은 용도로 사용하는 것은 엄격히 금지됩니다.
본 모델 사용 시 준수해야 할 주요 사항은 다음과 같습니다.
- 타인 음성 사칭, 사기, 허위 정보 생성 등 악의적 사용 금지
- 생성된 음성 및 콘텐츠는 AI 결과물임을 명확히 표시
- 사용자 혼동을 유발할 수 있는 형태의 무단 활용 제한
- 법적·윤리적 기준을 준수한 범위 내에서 활용 권장
이와 같은 기준을 준수함으로써, 모델의 기능을 안전하고 신뢰 가능한 방식으로 활용할 수 있습니다.
간단한 사용 예시
VoxCPM2는 텍스트를 자연스러운 음성으로 변환하거나, 음성 스타일을 제어하는 다양한 작업에 활용할 수 있는 모델입니다. 웹 기반 데모부터 로컬 GPU 실행까지 여러 방식으로 사용할 수 있으며, 목적에 따라 빠른 테스트부터 실제 서비스 개발까지 확장할 수 있는 구조를 제공합니다.
이번 예시에서는 1) 허깅페이스 데모 페이지, 2) 로컬 GPU 기반 실행으로 나누어 살펴보겠습니다. 웹 기반 방식은 모델의 동작을 빠르게 확인하는 데 적합하며, 로컬 실행은 보다 자유로운 커스터마이징과 서비스 연동에 적합합니다.
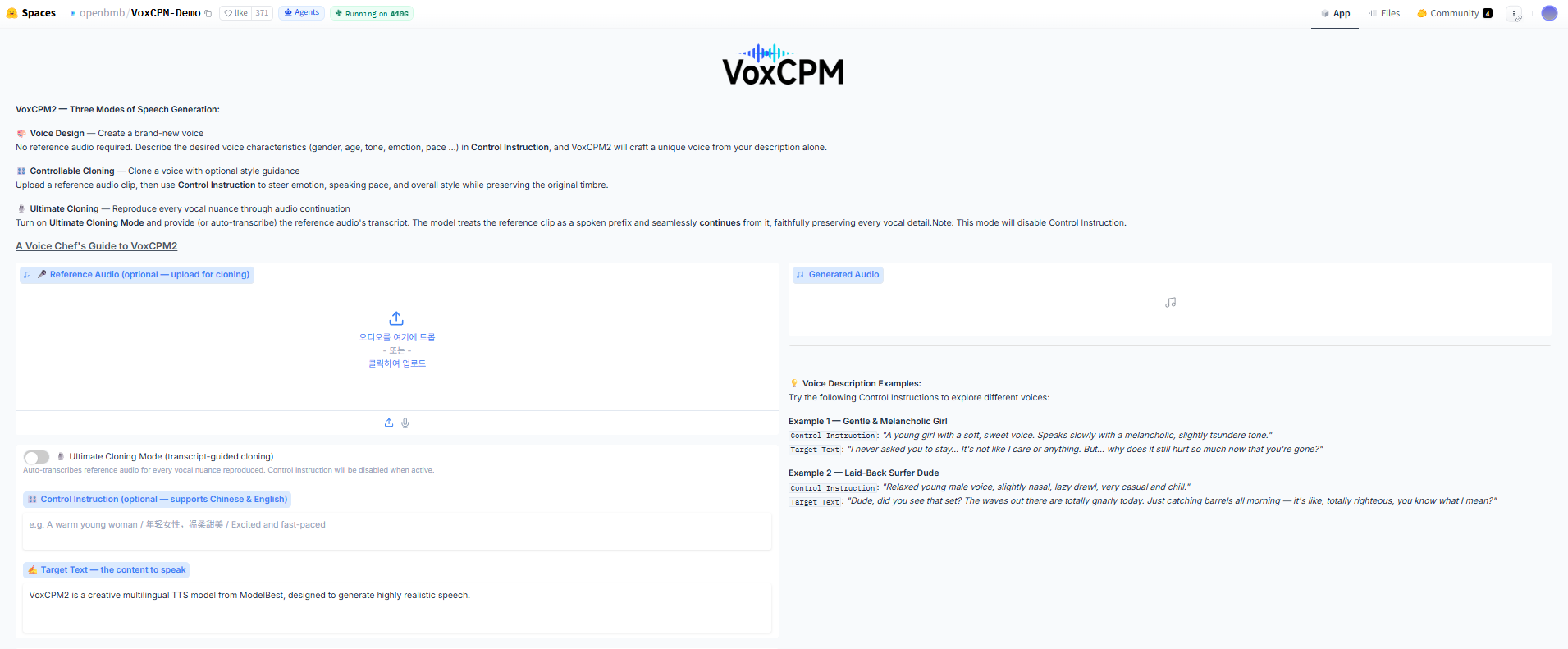
1. 허깅페이스 데모 페이지에서 바로 사용
VoxCPM2는 허깅페이스 데모 페이지를 통해 별도의 설치 없이 바로 사용할 수 있습니다. 브라우저에서 텍스트를 입력하면 즉시 음성 결과를 생성할 수 있으며, 보이스 클로닝이나 스타일 제어 기능도 함께 확인할 수 있습니다. 프롬프트 입력만으로 다양한 음성 생성 결과를 테스트할 수 있어, 모델의 특징과 성능을 직관적으로 파악하는 데에 적합한 환경입니다.
- 특징: 설치 없이 즉시 사용 가능, 웹 기반 인터페이스, 빠른 테스트 가능
- 비용: 무료 또는 사용량 기반 (플랫폼 정책에 따라 상이)
- 활용: 음성 생성 품질 확인, 보이스 클로닝 테스트, 초기 기능 검증
- 경로: https://huggingface.co/spaces/openbmb/VoxCPM-Demo
2. 로컬 GPU 기반 실행
VoxCPM2는 로컬 GPU 환경에서 직접 실행하여 사용할 수 있습니다. 모델 가중치를 다운로드한 뒤 Python 기반 환경에서 호출하여 음성 생성 작업을 수행할 수 있으며, 입력 텍스트뿐 아니라 음성 스타일이나 화자 특성까지 세밀하게 제어할 수 있습니다. 이 방식은 프롬프트 구성, 음성 출력 방식, 파라미터 조정 등 다양한 요소를 직접 설정할 수 있어, 실제 서비스 개발이나 커스터마이징이 필요한 환경에 적합합니다.
- 특징: 로컬 GPU 활용 가능, 세부 제어 및 커스터마이징 가능
- 비용: GPU 자원 기준
- 사용 환경: Linux / Windows (GPU 환경 권장)
- 활용: 음성 서비스 개발, 보이스 클로닝 시스템 구축, 맞춤형 음성 생성
- 모델 경로: https://huggingface.co/openbmb/VoxCPM2/tree/main (Openbmb 허깅페이스)
[패키지 설치]
로컬 환경에서 모델을 실행하기 위해서는 Transformers 패키지 설치와 Cohere Transcribe 모델 다운로드가 필요합니다. 해당 모델은 위 경로를 통해 다운로드하고, 패키지는 Windows PowerShell에서 아래 명령어를 통해 설치할 수 있습니다.
# Windows PowerShell
pip install voxcpm
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu126
[간단한 예시 코드 ]
# Python
from voxcpm import VoxCPM
import soundfile as sf
# 로컬 경로 지정
model = VoxCPM.from_pretrained(
"Path/to/openbmb/VoxCPM2", # 사용자 환경에 맞게 수정
load_denoiser=False
)
wav = model.generate(
text="안녕하세요. 반갑습니다. 마커스 블로그에 오신 것을 환영합니다. 좋은 하루 되세요!",
cfg_value=2.0,
inference_timesteps=10,
)
sf.write("output.wav", wav, model.tts_model.sample_rate)
[실행 결과]
VoxCPM2를 실제로 실행한 결과, 모델 로드 시간을 제외한 순수 추론 시간은 약 7초 정도 소요되었으며, 이 과정에서 약 6.7GB 수준의 VRAM이 사용되었습니다. 단일 음성 생성 기준으로 비교적 안정적인 자원 사용량을 보였으며, 일반적인 GPU 환경에서도 무리 없이 구동 가능한 수준으로 확인되었습니다.
이번 테스트는 Windows 환경에서 진행되어 일부 실행 오버헤드가 포함된 결과이며, Linux 환경에서 CUDA 및 실행 구성을 최적화할 경우 추론 속도는 더 단축될 수 있습니다. 특히 RTX 4090과 같은 고성능 GPU 기준에서는 RTF가 1.0 이하로 측정되어, 스트리밍 방식과 결합 시 실제 사용에서는 실시간에 가까운 음성 생성이 가능한 수준으로 활용할 수 있습니다.
[생성 결과]
VoxCPM2는 토크나이저 없이 음성을 직접 생성하는 구조를 기반으로, 음성 유사도와 자연스러움, 다국어 환경에서의 안정성을 균형 있게 확보한 음성 생성 모델입니다. 스트리밍 기반 생성과 실시간에 가까운 처리 성능을 제공하며, 보이스 클로닝과 스타일 제어까지 하나의 모델에서 수행할 수 있다는 점에서 기존 TTS 모델과는 다른 기술적 방향을 보여줍니다.
이러한 흐름은 음성 생성 기술이 단순한 발화 재현을 넘어, 말투와 감정, 미묘한 표현까지 자연스럽게 구현하는 단계로 발전하고 있음을 보여줍니다. 실제로 모델 결과를 통해 기계가 생성한 음성과 사람의 음성을 구분하기 어려운 수준에 점차 가까워지고 있으며, 향후에는 인간과 거의 구분되지 않는 음성 생성 기술이 등장할 것으로 보입니다.
감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [오픈소스 AI] 가장 가벼운 고성능 음성 AI, 샤오미 OmniVoice 모델 사용 가이드 (0) | 2026.05.14 |
|---|---|
| [오픈소스 AI] Qwen3.6-35B-A3B 공개 | 멀티모달·에이전트형 AI (0) | 2026.05.05 |
| [오픈소스 AI] GLM-5.1 모델 소개 | 코딩·에이전트 AI 성능, 비용, 간단한 사용 예시 (1) | 2026.04.14 |
| [오픈소스 AI] 구글 Gemma 4 공개: 멀티모달·온디바이스 모델 정리 (0) | 2026.04.03 |
| [오픈소스 AI] Cohere에서 공개한 ARS 모델, Cohere Transcribe를 소개합니다. | 음성 인식 모델 | Speech-to-Text (0) | 2026.03.31 |



