오픈AI의 ChatGPT를 시작으로 많은 LLM(거대언어모델)들이 등장하고 발전하고 있습니다. 초기에는 자체 평가를 통해 성능을 입증하고, 종종 GPT와 비교하여 성능이 높은지 낮은지 평가되었습니다. 그러나 객관적인 평가가 필요해지면서, 더 정확하고 세분화된 평가 방법이 도입되었습니다. 바로 특정 벤치마크나 데이터셋을 활용하는 방법입니다. 모델은 이러한 벤치마크나 데이터셋을 통해 출력된 값을 바탕으로 정확도와 성능이 평가됩니다.
오늘은 LLM을 평가하기 위해 사용되는 대표적인 벤치마크, 데이터셋에 대해 알아보겠습니다.
1. 벤치마크 / 데이터셋이란
벤치마크(Benchmark) 혹은 데이터셋(dataset)은 컴퓨터 과학 및 인공지능 연구에서 특정 시스템, 알고리즘, 모델의 성능을 평가하고 비교하기 위해 사용되는 표준화된 테스트나 일련의 테스트입니다. 벤치마크는 다양한 분야에서 사용되지만, 특히 머신러닝과 인공지능에서는 모델의 능력을 체계적이고 객관적으로 평가하는 중요한 도구입니다. 특정한 유형의 언어 이해 또는 생성 능력을 평가하기 위해 설계되었습니다.
쉽게 말하자면, LLM에게 벤치마크나 데이터셋은 시험지와 같습니다. LLM은 이 시험지(벤치마크, 데이터셋)를 보고 문제를 풀이하게 됩니다. 이후 정답률에 따라 그 성능이 수치화됩니다. 보통 100점을 만점으로 하고, 0점을 최저점으로 봅니다.
2. LLM 성능 평가에 사용되는 대표적인 벤치마크와 데이터셋
- ARC (AI2 Reasoning Challenge)
- 추론 능력 평가
- ARC는 기계 독해 및 추론 능력을 평가하기 위한 데이터셋입니다. 주로 과학적 사실과 논리를 기반으로 한 문제들로 구성되어 있으며, 중학교 수준의 과학 시험 문제를 포함합니다.
- 데이터셋은 'Easy'와 'Challenge' 두 부분으로 나뉘며, 후자는 더 복잡한 추론 능력을 요구합니다.
- HellaSwag
- 상식 추론
- HellaSwag는 문장 완성을 통해 모델의 상식 추론 능력을 평가하는 벤치마크입니다. 주어진 상황을 바탕으로 가장 자연스러운 후속 문장을 선택하는 문제들로 구성됩니다.
- 이 벤치마크는 모델이 단순한 패턴 인식이 아닌, 더 깊은 이해와 상식을 필요로 한다는 점에서 중요합니다.
- MMLU (Massive Multitask Language Understanding)
- 종합적 이해도 평가
- MMLU는 다중 과제 언어 이해를 평가하기 위한 벤치마크로, 다양한 주제와 난이도의 문제들로 구성되어 있습니다. 주제는 과학, 역사, 수학, 문화 등 매우 광범위합니다.
- 모델의 다재다능함과 다양한 주제에 대한 이해 능력을 평가하는 데 중점을 둡니다.
- TruthfulQA
- 허위 정보 인식
- TruthfulQA는 모델이 질문에 대해 얼마나 진실되고 정확하게 답할 수 있는지를 평가하는 벤치마크입니다. 주어진 질문에 대해 모델이 오해하거나 거짓된 정보를 제공하는지 여부를 테스트합니다.
- 이 벤치마크는 특히 정보의 신뢰성과 관련된 응용 분야에서 중요합니다.
- GPQA (General Purpose Question Answering)
- 다목적 질문 응답 평가
- GPQA는 다양한 주제와 복잡한 질문에 대한 대답을 평가하기 위한 벤치마크입니다. 이 데이터셋은 과학, 역사, 예술, 사회 등 다양한 주제의 질문을 포함하고 있습니다.
- 모델이 광범위한 도메인 지식을 바탕으로 정확하고 관련성 높은 답변을 생성할 수 있는 능력을 평가하는 데 중점을 둡니다.
- GSM8k (Grade School Math 8K)
- 수학적 추론
- GSM8k는 모델의 수학적 문제 해결 능력을 평가하기 위한 데이터셋입니다. 초등학교 수준의 수학 문제 8,000개로 구성되어 있습니다.
- 모델이 단순한 산술 계산부터 복잡한 문제 해결까지 다양한 수학적 과제를 얼마나 잘 수행하는지 평가합니다.
- MATH (Mathematics Aptitude Test of Humans)
- 고등학교 수학 문제 해결 평가
- MATH는 고등학교 수준의 다양한 수학 문제를 포함하는 데이터셋으로, 대수학, 기하학, 확률, 통계 등의 문제를 다룹니다.
- 모델의 고급 수학적 추론 능력을 평가하는 데 중점을 둡니다. 문제는 다양한 난이도의 수학적 개념을 포함하며, 모델이 복잡한 수학적 추론을 통해 문제를 해결할 수 있는지를 평가합니다.
- Winogrande
- 문맥 기반 추론
- Winogrande는 위노그라드 스키마(WSC, Winograd Schema Challenge)의 확장 버전으로, 문맥을 이해하고 대명사의 참조를 해결하는 능력을 평가합니다.
- 모델이 대명사가 지칭하는 대상(참조 해상도)을 정확하게 파악할 수 있는지 테스트합니다.
- HumanEval
- 프로그래밍 능력 평가
- HumanEval은 프로그래밍 언어 모델의 코딩 능력을 평가하기 위한 벤치마크입니다. 주어진 프로그래밍 문제를 해결하기 위해 작성된 코드의 정확성과 효율성을 평가합니다.
- 모델이 주어진 프로그래밍 문제를 정확하게 해결하고, 다양한 테스트 케이스에서 올바르게 작동하는지 평가하는 데 중점을 둡니다.
예시
아래의 표는 Meta에서 오픈 소스로 공개한 LLaMA3 모델에 대한 성능 지표를 보여줍니다. 이 표에서는 LLaMA3 모델과 이전 버전인 LLaMA2 모델의 성능을 비교하고 있습니다. LLaMA3 모델은 다양한 벤치마크와 데이터셋을 사용하여 테스트되었으며, 그 결과를 성능 지표로 나타냈습니다. 주요 성능 지표로는 MMLU, GPQA, HumanEval, GSM-8K, MATH 등이 포함됩니다. 이 표는 LLaMA3 모델과 LLaMA2 모델의 다양한 버전(7B, 13B, 70B)에서의 성능을 비교한 것입니다. 특히 LLaMA3 모델의 8B와 70B 버전의 성능이 두드러지게 향상된 것을 확인할 수 있습니다. 아래는 각 성능 지표에 대한 설명입니다.
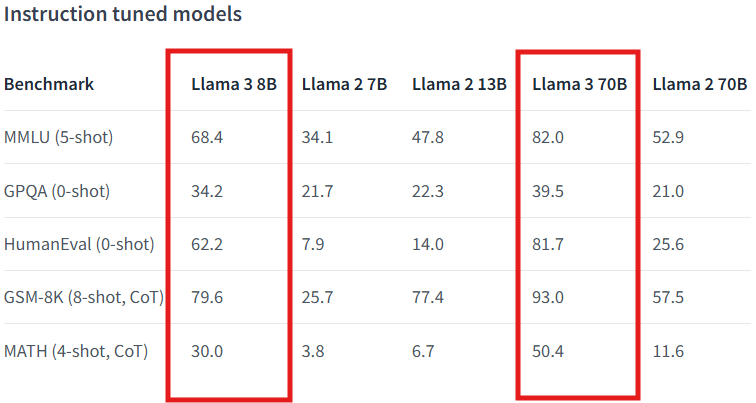
출처 : Meta 허깅페이스 (https://huggingface.co/meta-llama/Meta-Llama-3-8B)
LLaMA3 모델 성능표 설명
- MMLU (Massive Multitask Language Understanding, 5-shot): 모델이 다양한 주제와 난이도의 문제를 해결하는 능력을 평가합니다.
- GPQA (General Purpose Question Answering, 0-shot): 모델이 다양한 질문에 대해 정확하게 답변하는 능력을 평가합니다.
- HumanEval (0-shot): 모델이 주어진 프로그래밍 문제에 대해 정확한 코드를 생성하는 능력을 평가합니다.
- GSM-8K (8-shot, CoT): 초등학교 수준의 수학 문제 해결 능력을 평가합니다.
- MATH (4-shot, CoT): 고등학교 수준의 수학 문제 해결 능력을 평가합니다.
4. 벤치마크 데이터셋의 장점
벤치마크 및 데이터셋을 이용하여 LLM의 성능을 평가하는 이유는 여러 가지가 있습니다. 이러한 평가 방법들은 모델의 다양한 능력을 체계적이고 객관적으로 측정하는 데 중요한 역할을 합니다.
- 객관적인 성능 비교
- 벤치마크와 데이터셋은 모델 간 성능을 비교할 수 있는 객관적인 기준을 제공합니다. 동일한 테스트 환경과 문제를 사용함으로써, 어떤 모델이 더 우수한지 명확하게 알 수 있습니다.
- 다양한 능력 평가
- LLM은 다양한 작업을 수행할 수 있어야 합니다. 벤치마크와 데이터셋은 독해, 상식 추론, 수학적 문제 해결, 대명사 참조 해상도 등 다양한 측면에서 모델의 능력을 평가할 수 있도록 구성되어 있습니다.
- 예를 들어, ARC는 과학적 추론 능력을, HellaSwag는 상식 추론 능력을, 그리고 GSM8k는 수학적 문제 해결 능력을 평가합니다.
- 모델의 강점과 약점 식별
- 다양한 벤치마크를 사용하면 모델이 특정 영역에서 강점을 가지는지, 약점을 가지는지를 파악할 수 있습니다. 이는 모델을 개선하고 특정 작업에 최적화하는 데 중요한 정보를 제공합니다.
- 실제 사용 시나리오와의 연관성
- 벤치마크는 실제 응용 사례와 유사한 시나리오를 포함하도록 설계되어 있습니다. 이를 통해 모델이 실제 상황에서 어떻게 성능을 발휘할지 예측할 수 있습니다.
- 예를 들어, TruthfulQA는 정보의 정확성과 신뢰성이 중요한 실제 사용 사례에서 모델의 성능을 평가합니다.
- 연구와 발전 촉진
- 벤치마크와 데이터셋은 연구자들이 새로운 알고리즘과 모델을 테스트하고 발전시키는 데 필요한 도구를 제공합니다. 이를 통해 LLM 기술의 전반적인 발전을 촉진할 수 있습니다.
- 연구 커뮤니티는 이러한 평가를 통해 새로운 접근 방식과 개선 사항을 공유하고 비교할 수 있습니다.
- 투명성과 재현성 보장
- 공공 벤치마크와 데이터셋을 사용하면 연구 결과의 투명성과 재현성을 보장할 수 있습니다. 다른 연구자들이 동일한 조건에서 테스트를 수행하여 결과를 재현할 수 있습니다.
- 이는 학계와 산업계 모두에서 신뢰할 수 있는 연구 결과를 제공하는 데 중요합니다.
5. 그 이외의 방법
이 외로 LLM을 평가하는 방법으로는 LLM의 결과물을 사람이 직접 비교 평가하는 방법이 있습니다. 이 방법을 활용하는 대표적인 플랫폼은 Chatbot Arena로, 사용자가 익명의 LLM 두 명과 대화에 참여합니다. 사용자는 몇 차례의 대화를 기반으로 더 나은 성능을 보여준다고 판단하는 LLM에 투표합니다.
또한, 성능이 검증된 강력한 LLM을 사용하여 다른 LLM을 평가하는 다중 턴 질문셋인 MT-Bench도 있습니다. 이러한 대안적인 평가 방법들은 LLM의 성능과 안전성을 보다 정확하게 평가하는 데 기여할 수 있습니다.
이번 글에서는 LLM 모델의 성능을 평가할 때 사용되는 벤치마크와 데이터셋에 대해 알아보았습니다. ARC, HellaSwag, MMLU, TruthfulQA, GPQA, GSM8k, MATH, Winogrande, HumanEval 등 다양한 벤치마크와 데이터셋은 모델의 다양한 능력을 평가하고 강점과 약점을 식별하는 데 유용합니다. 이러한 평가는 모델의 성능을 객관적으로 비교하고 개선할 수 있는 중요한 도구로 활용됩니다. 앞으로도 중요한 평가지표나 새로운 벤치마크가 등장하면 이를 추가하여 최신 정보를 제공하도록 하겠습니다. 지속적인 연구와 평가를 통해 LLM 모델의 발전을 기대해 봅니다.
읽어주셔서 감사합니다 :)
'AI 용어' 카테고리의 다른 글
| 스테이블디퓨전 프롬프트 작성방법 (0) | 2024.08.25 |
|---|---|
| LLM의 경량화와 성능 개선 방법에 대해 알아보자. (0) | 2024.05.29 |
| 서버와 통신에 사용되는 FastAPI / RemoteRunnable에 대해 알아보자. (0) | 2024.05.23 |
| AI 학습을 위한 기본 용어에 대해 알아보자 (2) | 2024.05.21 |
| Fine-tuning과 RAG에 대해 알아보자. (0) | 2024.05.14 |



