안녕하세요,
최근 국내 대표 여행·레저 플랫폼 기업인 야놀자에서 한국어 활용에 특화된 AI 언어 모델 EEVE-Rosetta-4B를 공개했습니다. 이 모델은 구글 Gemma 기반을 토대로 파인튜닝된 것으로, 경량화된 구조를 갖추면서도 번역과 요약, 감성 분석 등 다양한 자연어 처리 작업을 지원합니다. 특히 한국어 번역 성능을 강화한 점이 돋보이며, 오픈소스로 제공되어 누구나 로컬 환경에서 직접 실행하고 활용해볼 수 있습니다.
이번 글에서는 EEVE-Rosetta-4B 모델의 특징을 살펴보고, 로컬 환경에서 실행하는 방법까지 단계별로 소개해 드리겠습니다.
EEVE-Rosetta-4B 모델이란
2025년 9월 1일, 국내 기업 야놀자는 한국어 번역에 특화된 언어 모델 EEVE-Rosetta-4B를 공개했습니다. 이 모델은 구글의 gemma-3-4b-pt를 기반으로 파인튜닝된 것으로, 텍스트 생성, 콘텐츠 요약, 언어 번역, 감성 분석 등 다양한 자연어 처리 기능을 수행할 수 있는 범용 모델입니다. 특히 Gemma3ForCausalLM 구성요소만을 추출하여 약 40억 개 파라미터(decoder-only) 규모로 경량화된 것이 특징입니다.
야놀자, 자체 개발한 번역 특화 LLM ‘EEVE ROSETTA’ 공개
글로벌 트래블 테크 기업 야놀자(총괄대표 이수진)가 번역 특화 LLM(거대언어모델) 'EEVE ROSETTA(이브 로제타)'를 누구나 사용 가능한 오픈소스 AI 플랫폼 Huggin
www.yanoljagroup.com
주요 특징
- 경량화 및 효율성 : 40억 파라미터 규모로 경량화된 구조를採용하여 기존 대형 번역 모델에 비해 연산량과 운영 비용을 크게 줄이면서도 높은 추론 정확도를 유지하도록 설계되었습니다.
- 광범위한 다국어 지원 : 영어, 중국어, 한국어를 비롯한 10여 개 언어 간 번역을 폭넓게 지원합니다. 일반적인 번역 특화 LLM이 영어와 중국어 중심으로 제한되는 것과 달리, EEVE-Rosetta는 다양한 언어 간 번역에 최적화되어 있습니다. 또한 Hugging Face 설명에 따르면 스페인어, 프랑스어, 독일어, 포르투갈어, 일본어, 아랍어, 러시아어, 힌디어 등이 포함되어 있으며, 베이스 모델이 지원하는 기타 언어에도 유연하게 대응할 수 있습니다.
- 고품질 다국어 번역 : EEVE-Rosetta는 번역 과정에서 원문이 지닌 문맥, 뉘앙스, 감정, 의미를 고려하여 매끄럽고 명확한 번역문을 생성합니다. 특히 JSON과 같은 구조화된 데이터를 번역할 때 원래 형식을 유지하도록 설계되어, 제품 카탈로그나 리뷰 등 다양한 로컬라이제이션 작업에 적합합니다.
- FP8 정밀도 활용 : 모델 이름에 포함된 “FP8”은 8비트 부동소수점(FP8) 정밀도를 사용한다는 의미입니다. 이 방식은 연산량을 줄이고 메모리 효율을 높여 모델 실행의 경제성과 효율성을 강화하는 데 기여합니다.
라이선스
EEVE-Rosetta-4B 모델은 Google Gemma-3-4B-PT를 기반으로 파인튜닝된 모델로, Gemma Terms of Use를 그대로 따르는 라이선스 체계를 갖추고 있습니다. 따라서 기업이나 개인은 이 모델을 상업적 목적으로 자유롭게 활용할 수 있으며, 모델이 생성한 출력물(Output)에 대한 권리 역시 전적으로 사용자에게 귀속됩니다. 다만 모델 자체를 배포하거나 재배포할 경우에는 Gemma Terms of Use 사본을 반드시 포함해야 하고, 수정한 경우에는 그 사실을 명시해야 합니다. 또한 Google이 정한 금지 용도(Prohibited Use Policy)와 관련 법규를 준수해야 하며, 모든 사용에 따른 책임은 사용자에게 있습니다.
자세한 내용은 아래 Gemma 라이선스를 참고해주시기 바랍니다.
Gemma 라이선스 : https://ai.google.dev/gemma/terms
EEVE-Rosetta-4B 모델 사용하기
1) 사전 준비 사항
EEVE-Rosetta-4B 모델은 허깅페이스를 통해 제공되고 있으며, 로컬 환경에서 파이썬을 사용해 직접 실행할 수 있습니다. 따라서 실행에 앞서 아래 링크를 통해 파이썬 및 EEVE-Rosetta-4B 모델을 미리 준비해주시길 바랍니다. (2025년 10월 10일 확인 결과, EEVE-Rosetta-4B 모델이 YanoljaNEXT-Rosetta-4B로 이름이 변경되었습니다. 참고해주시기 바랍니다.)
Python 설치 : https://www.python.org/downloads/
야놀자 허깅페이스 EEVE-Rosetta-4B 모델 다운로드 : https://huggingface.co/yanolja/YanoljaNEXT-Rosetta-4B/tree/main
2) 실행 환경
- 운영체제 : Windows 11
- Python : 3.10.11
- torch : 2.6.0 + cu126
- transformers : 4.56.0
- accelerate : 1.10.1
- GPU : NVIDIA GeForce RTX 4060 Ti (VRAM 16 GB)
3) 패키지 설치
EEVE-Rosetta-4B 모델을 실행하기 위해 필요한 패키지를 설치합니다. 아래 명령어를 Windows PowerShell에서 실행하면 됩니다.
# Windows PowerShell
pip install transformers accelerate compressed-tensors
pip install torch==2.6.0 --index-url https://download.pytorch.org/whl/cu126
4) 코드 작성
아래와 같이 EEVE-Rosetta-4B 모델과 간단한 문답을 주고받을 수 있는 코드를 작성합니다.
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "Path/to/EEVE-Rosetta-4B-FP8-2507" # 사용자 환경에 맞게 수정 (모델 경로)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
).eval()
# Example prompt
target_language = "Korean"
messages = [
{
"role": "system",
"content": (
f"Translate the user's text to {target_language}."
"Output only one sentence of the final translation"
"Do not print explanations, thought processes, or examples."
),
},
{"role": "user", "content": "Yanolja NEXT is a company that provides global cutting-edge technology for the hospitality industry."} # 프롬프트 입력
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
with torch.inference_mode():
outputs = model.generate(
**inputs,
max_new_tokens=512,
do_sample=False,
eos_token_id=tokenizer.eos_token_id,
)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
5) 실행 결과
EEVE-Rosetta-4B 모델을 로컬 환경에서 실행한 결과, 약 9.2GB의 VRAM을 점유하였으며 실제 추론 속도는 기대보다 다소 느리게 나타났습니다. max_new_tokens 값을 100으로 설정했을 때는 번역 과정이 완료되기까지 약 1분가량 소요되었고, 500으로 늘렸을 경우에는 약 5분 정도가 걸렸습니다.
이번 테스트에서 번역을 위해 입력한 프롬프트는 다음과 같습니다.
- 프롬프트 : Yanolja NEXT is a company that provides global cutting-edge technology for the hospitality industry.
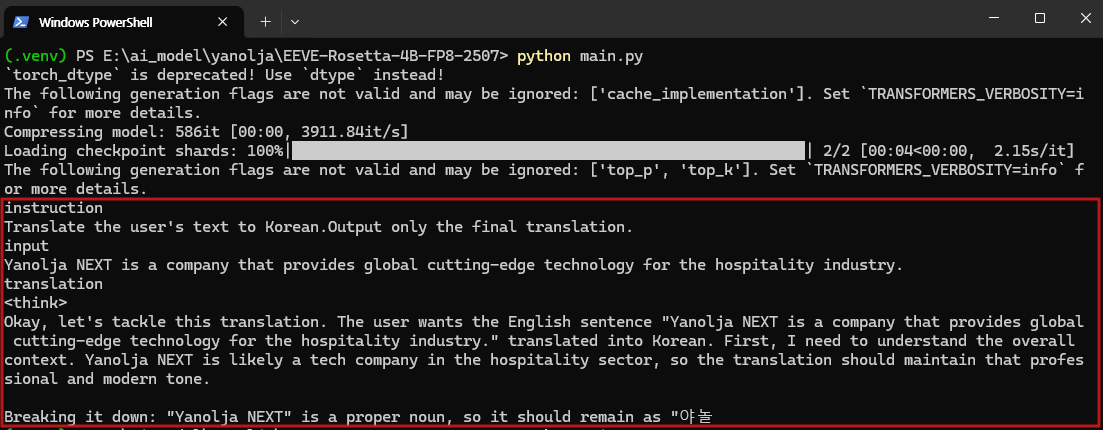

max_new_tokens 값에 따른 실행 결과를 비교하면, 100 토큰으로 제한했을 때는 모델이 사고 과정을 전개하는 데 대부분의 토큰을 소모하여 실제 번역문이 출력되지 않는 문제가 발생했습니다. 반면 500 토큰으로 확장했을 때는 번역문이 출력되었지만, 처리 시간이 지나치게 길어 실사용 환경에서 효율성이 떨어질 수 있다는 한계가 드러났습니다.
즉, 간단한 문장을 번역하는 데에도 1분 이상 소요되는 것은 상당히 비효율적이었으며, 특히 짧은 max_new_tokens 설정에서는 결과물이 나오지 않는 점이 큰 제약으로 확인되었습니다. 이는 모델이 학습 과정에서 사고 과정을 중시하도록 설계된 특성과도 관련이 있어, 실제 활용을 위해서는 토큰 길이 설정과 프롬프트 최적화가 반드시 필요할 것으로 보입니다.
EEVE-Rosetta-4B 모델은 구글 Gemma 기반을 토대로 한국어 번역에 특화되도록 파인튜닝된 모델로, 경량화된 구조(40억 파라미터)를 통해 비교적 적은 자원으로도 실행할 수 있다는 장점이 있습니다. 또한 다국어를 지원하면서도 한국어 번역 품질을 강화했고, 무엇보다 상업적 사용이 가능하도록 공개되어 있다는 점에서 기업과 개발자에게 실질적인 가치를 제공한다고 할 수 있습니다.
다만 간단한 문장 번역에도 다소 시간이 소요되는 점, 사고 과정을 중시한 학습 특성 때문에 짧은 토큰 설정 시 결과물이 제대로 출력되지 않는 한계가 아쉬움으로 남습니다. 그럼에도 불구하고 EEVE-Rosetta-4B는 국내 기업이 주도적으로 개발한 K-LLM의 의미 있는 진전으로, 앞으로 한국어에 최적화된 대규모 언어 모델이 더 빠르고 정교하게 발전해 나갈 가능성을 보여주는 사례라고 생각됩니다.
감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| AI 에이전트 최적화 모델, GUI-Owl 소개|오픈소스 VLM (1) | 2025.09.11 |
|---|---|
| [음성 생성 AI] 마이크로소프트 VibeVoice TTS 모델 소개 및 사용 가이드 (ComfyUI 활용) (4) | 2025.09.09 |
| 한국어 전용 LLM, Trillion Labs ‘Tri-7B’ 모델 소개|한국형 AI | KLLM (5) | 2025.08.29 |
| [오픈소스 AI] 일론 머스크의 xAI, Grok-2 초대형 언어 모델 공개 (3) | 2025.08.28 |
| [오픈소스 AI] GPT-5에 맞서는 오픈소스 AI, DeepSeek-V3.1 공개 (1) | 2025.08.22 |



