안녕하세요,
최근 OpenAI에서 GPT-5를 출시하며 LLM 시장에 또 한 번 큰 변화가 일어났습니다. GPT-5는 기존 GPT-4 시리즈보다 이해력, 추론 능력, 멀티모달 처리 성능이 전반적으로 향상되었으며, 특히 대규모 컨텍스트 윈도우와 빠른 응답 속도를 통해 실사용자 경험이 크게 개선되었습니다.
이번 글에서는 단순한 성능 수치뿐만 아니라 가격 대비 효율, 멀티모달 지원 여부, 웹 개발·코딩 특화 성능 등 다양한 관점에서 살펴보며, 2025년 8월 기준 주요 LLM 모델들의 순위 변동과 각 모델의 특화 강점에 대해 알아보겠습니다.
이번 포스팅에는 두 가지 주요 지표를 활용합니다. 실사용자 투표 기반 순위(Chatbot Arena)는 실제 사용자가 직접 모델을 사용한 뒤 투표로 평가한 결과로, 실제 체감 성능과 사용자 만족도를 반영합니다. 종합 벤치마크 점수(Artificial Analysis)는 다양한 표준 테스트셋을 활용해 모델의 추론 능력, 창의성, 멀티모달 이해력 등을 점수화하여 객관적인 성능을 측정합니다.
이 두 지표(벤치마크 성능과 실사용자 선호도)를 함께 살펴보며, 현재 시장에서 주목할 만한 모델과 그 특징을 비교 정리하고, 이어지는 본문에서 2025년 8월 최신 순위표와 모델별 장단점에 대해 살펴보겠습니다.
[참고 링크]
- 실사용자 투표 기반 (LMArena) : https://lmarena.ai/leaderboard
- 종합 벤치마크 점수 (Artificial Analysis) : https://artificialanalysis.ai/
AI 모델 선택 가이드 (전체 요약)
| 목적 | 추천모델 |
| 최고의 성능이 필요한 경우 | GPT-5 (high) |
| 웹 개발·코딩 작업 최적화 | GPT-5 (high) / Claude Opus 4.1 |
| 최저 비용 모델 | gpt-oss-20B |
| 강력한 오픈소스 AI | gpt-oss-120B / Qwen3-235B (Reasoning) |
| 한국어 최적화 모델 | EXAONE-4.0-32B |
LMArena - Text·WebDev 카테고리 TOP 모델 비교
LMArena에서는 LLM(대형 언어 모델)을 다양한 카테고리로 나누어 평가합니다. 아래 이미지는 2025년 8월 기준 Text와 WebDev 카테고리의 상위권 모델 순위를 보여주는 표로, 여러 AI 모델의 전반적인 성능과 과제별 순위를 한눈에 확인할 수 있습니다.
- 2025년 8월 11일 기준, 총 226개 모델이 평가되었으며, 3,820,820건의 투표 진행
- GPT-5, Gemini-2.5 Pro, Claude Opus 4.1, DeepSeek-R1, Grok-4 등 최신 플래그십 언어 모델이 포함

[ Text 모델 성적 ]
Text 카테고리는 LLM의 전반적인 언어 이해력, 추론 능력, 문맥 유지 능력 등을 종합적으로 평가하는 영역입니다. 이 순위는 주로 대화 품질, 질문·답변 정확도, 창의적 문장 생성 능력 등을 중심으로 평가되며, 광범위한 주제와 상황에서 모델이 얼마나 일관성 있고 유용한 답변을 제공하는지를 반영합니다.
2025년 8월 11일 기준 순위 (Chatbot Arena)
- GPT-5-high — 점수 1481 (3,181표)
- Gemini-2.5-pro — 점수 1458 (28,091표)
- o3 (2025-04-16) — 점수 1451 (34,027표)
- Claude Opus 4.1 (20250805) — 점수 1446 (5,187표)
- ChatGPT-4o (20250326) — 점수 1440 (32,125표)
[ WebDev 모델 성적 ]
WebDev 카테고리는 웹 개발 관련 작업에 특화된 LLM의 성능을 평가하는 영역입니다. 이 순위는 코드 작성 정확도, 버그 수정 능력, 웹 관련 라이브러리·프레임워크 이해도, 문서 작성 및 주석 품질 등을 중심으로 평가됩니다. 웹 개발 환경에서 실제로 얼마나 효율적이고 신뢰성 있는 도움을 줄 수 있는지를 보여줍니다.
2025년 8월 4일 기준 순위 (Chatbot Arena)
- GPT-5 (high) — 점수 1482 (3,651표)
- Claude Opus 4.1 (20250805) — 점수 1426 (1,402표)
- Gemini-2.5-Pro — 점수 1405 (7,085표)
- DeepSeek-R1 (0528) — 점수 1391 (4,650표)
- Claude Opus 4 (20250514) — 점수 1382 (9,004표)
최근 OpenAI가 GPT-5를 출시하며 LLM 시장에서 독보적인 성능을 입증하고 있습니다. GPT-5는 LMArena의 2025년 8월 최신 데이터에서 Text와 WebDev 두 카테고리 모두 1위를 차지하며, 전반적인 언어 이해력과 웹 개발 특화 성능에서 모두 우수한 결과를 보여주고 있습니다. Text 부문에서는 1,481점(3,181표)으로 2위 Gemini-2.5 Pro를 앞섰고, WebDev 부문에서도 1,482점(3,651표)으로 Claude Opus 4.1과 Gemini-2.5 Pro 등 경쟁 모델을 제치며 정상에 올랐습니다. 이러한 결과는 GPT-5가 출시 직후 전 영역에서 고른 성능 향상을 이루며, 플래그십 LLM으로서의 입지를 확고히 하고 있음을 보여줍니다.
Artificial Analysis - AI 종합 성능 및 가성비 비교
Artificial Analysis는 LLM(대형 언어 모델)의 성능을 다양한 표준 테스트셋을 기반으로 종합 평가합니다. MMLU-Pro, GPQA Diamond, Humanity’s Last Exam, LiveCodeBench, SciCode, AIME, IFBench, AA-LCR 등 총 8가지 평가 항목을 반영하며, 언어 이해력·추론 능력·코딩 및 수학적 사고·멀티모달 이해력 등 다방면의 성능을 점수화합니다.
아래 이미지는 2025년 8월 기준 AI 종합 성능 순위와 성능 대비 가격(가성비) 결과를 보여줍니다. 이를 통해 단순히 성능이 높은 모델뿐 아니라, 비용 효율이 우수한 모델까지 함께 파악할 수 있습니다.
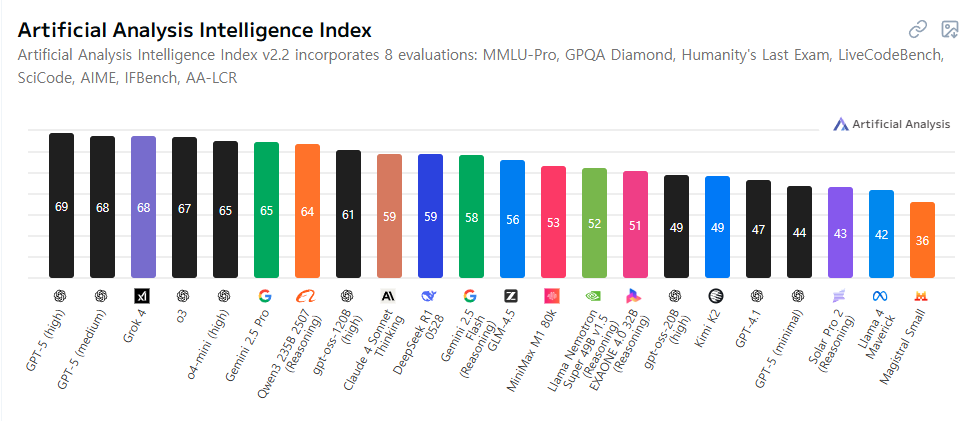

[AI 종합 성능 지수 TOP 5]
AI 종합 성능 지수는 다양한 벤치마크 테스트를 종합해 모델의 전반적인 지능 수준을 수치화한 지표입니다. 높은 점수일수록 언어 이해, 논리 추론, 창의적 문제 해결, 코드 작성 등 다양한 과제에서 우수한 성능을 발휘함을 의미합니다.
2025년 8월 기준 순위 (Artificial Analysis)
- GPT-5 (high) — 68.95점
- GPT-5 (medium) — 67.53점
- Grok-4 — 67.52점
- o3 — 67.07점
- o4-mini (high) — 65.05점
[가성비 우수 모델 TOP 5]
성능 대비 가격 지표(Intelligence vs. Price)는 모델의 종합 성능 점수를 100만 토큰당 사용 비용과 비교한 지표입니다. 우측 상단에 위치한 모델일수록 성능과 가격 효율성이 모두 뛰어난 것으로 평가됩니다.
2025년 8월 기준 순위 (Artificial Analysis)
- GPT-OSS-20B (high) — 고성능·저비용 오픈소스 모델 (100만 토큰당 $0.09)
- GPT-OSS-120B (high) — 대규모 파라미터 기반 고성능·저비용 모델 (100만 토큰당 $0.26)
- GLM-4.5 — 중국 Zhipu AI의 고성능·합리적 가격 모델 (100만 토큰당 $0.96)
- DeepSeek-R1 (0528) — 우수한 코딩·추론 성능 대비 합리적 가격 (100만 토큰당 $0.96)
- Gemini-2.5 Flash (Reasoning) — 빠른 응답 속도와 저렴한 가격이 장점 (100만 토큰당 $0.85)
GPT-5는 LMArena뿐만 아니라 Artificial Analysis에서도 최고의 성능을 입증하며 1위를 차지하고 있습니다. 2025년 8월 기준 종합 성능 지수에서 GPT-5(high)는 68.95점으로 가장 높은 점수를 기록했고, GPT-5(medium) 역시 67.53점으로 2위를 차지해 전반적인 언어 이해력과 추론 능력에서 탁월한 성능을 보여주고 있습니다.
더욱 주목할 점은 OpenAI가 공개한 오픈소스 모델인 GPT-OSS 시리즈의 활약입니다. GPT-OSS-20B와 GPT-OSS-120B 모델은 성능과 가격 효율성에서 모두 뛰어난 결과를 기록하며, 가성비 우수 모델 TOP 5에 이름을 올렸습니다. 특히 GPT-OSS-20B는 100만 토큰당 0.09달러라는 매우 저렴한 비용으로 고성능을 제공해, 상용 모델뿐 아니라 오픈소스 모델의 가능성까지 확인시켜 주고 있습니다.
종합적으로 살펴보면, GPT-5는 출시 직후부터 모든 주요 평가 지표에서 압도적인 성능을 보여주며 LLM 시장의 새로운 기준을 세우고 있습니다. LMArena에서는 Text와 WebDev 두 분야 모두에서 1위를 차지하며 전방위적인 활용성을 입증했고, Artificial Analysis에서도 최고 점수를 기록하며 언어 이해와 추론 능력, 멀티모달 처리 등 전 영역에서 우수한 결과를 거두었습니다.
특히 OpenAI의 오픈소스 라인업인 GPT-OSS 시리즈가 뛰어난 성능과 탁월한 가성비로 상위권에 오르며, 상용 모델 중심이었던 시장에 새로운 선택지를 제시한 점은 주목할 만합니다. 이러한 흐름은 앞으로 LLM 시장이 성능과 비용 효율성을 동시에 고려하는 방향으로 재편될 가능성을 보여주며, GPT-5와 GPT-OSS 모델이 그 변화를 선도하고 있음을 분명히 하고 있습니다.
감사합니다. 😊
[오픈소스 활용하기]
- 오픈소스 모델 GPT-OSS 활용하기 : [Marcus' Story] - GPT‑OSS, OpenAI의 오픈소스 AI 모델을 로컬에서 실행해보세요 | Ollama 활용법 | 오픈소스 AI
'AI 소식' 카테고리의 다른 글
| GPT-5 출시 이후 논란과 대응, GPT-4o·4.1 다시 제공 시작 (2) | 2025.08.18 |
|---|---|
| Anthropic Claude Opus 4.1 출시 | 벤치마크 성능·구독별 접근 권한 총정리 (6) | 2025.08.13 |
| OpenAI의 최신 AI 모델, GPT-5를 소개합니다. (5) | 2025.08.08 |
| 구글 AI를 1년간 무료로? 대학(원)생 대상 Google AI Pro 혜택 안내 (6) | 2025.08.08 |
| ChatGPT Agent 기능 업데이트: OpenAI가 만든 '작업형 AI'는 어떻게 달라졌나 (3) | 2025.07.27 |



