안녕하세요,
최근 AI 기술은 언어, 이미지, 영상은 물론 소리 분야에서도 눈부신 발전을 이루고 있습니다. 특히 주목할 만한 점은, 단 몇 초간의 음성 샘플만으로 특정 인물의 목소리를 정교하게 복제할 수 있는 AI 모델들이 등장하고 있다는 사실입니다. 이번에 소개해드릴 AI 모델 역시, 불과 15초 정도의 짧은 오디오 클립만 제공하면 해당 목소리를 그대로 재현해내는 놀라운 기술을 보여줍니다. 바로, 오늘 알아볼 Spark-TTS입니다.
그럼 Spark-TTS가 어떤 모델인지 자세히 살펴보겠습니다.
Spark-TTS
Spark-TTS는 대규모 언어 모델을 기반으로 한 고급 텍스트-투-스피치(Text-to-Speech) 시스템으로, 자연스럽고 정확한 음성 합성을 제공합니다. 이 모델은 연구와 실제 서비스 환경 모두에서 효율적이고 유연하게 활용할 수 있도록 설계되었습니다. Spark-TTS의 핵심은 자체 개발한 BiCodec 구조로, 음성을 언어적 내용과 화자 특성을 각각 담당하는 두 가지 토큰으로 나누어 처리하는 방식입니다. 이를 통해 성별, 음색, 높낮이, 말 속도 등 다양한 음성 속성을 정교하게 제어할 수 있습니다.
- Spark-TTS 프로젝트 페이지 : https://sparkaudio.github.io/spark-tts/
Spark-TTS
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens Xinsheng Wang1,2, Mingqi Jiang3, Ziyang Ma4,5, Ziyu Zhang6, Songxiang Liu7, Linqin Li3, Zheng Liang4, Qixi Zheng4, Rui Wang3, Xiaoqin Feng3, Weizhen Bian1, Zh
sparkaudio.github.io
주요 특징
- 단순화된 효율적 구조 : Qwen2.5 LLM 하나로 구성되어 별도의 음향 모델 없이 오디오를 직접 복원, 복잡도를 낮추고 처리 속도를 향상
- 제로샷 음성 클로닝 지원 : 특정 화자 데이터 없이도 목소리 복제가 가능, 다국어 및 코드 스위칭 환경에서도 자연스러운 전환 제공
- 중·영어 이중 언어 지원 : 중국어와 영어 모두에서 높은 자연스러움과 정확도로 음성 합성이 가능하며, 테스트 결과 한국어 역시 일정 수준으로 복제가 가능하지만 상대적으로 품질은 낮은 편
- 세밀한 음성 제어 : 성별, 음높이, 말 속도 등 다양한 음성 속성을 조절하여 가상 화자 생성 가능
주의 사항
이 프로젝트는 개인화된 음성 합성, 보조 기술, 언어 연구, 교육 목적, 그리고 기타 합법적인 응용 프로그램을 위한 제로샷 음성 복제 TTS 모델입니다. 사용에 앞서 반드시 아래 사항을 준수해 주시기 바랍니다.
- 무단 음성 복제, 사칭, 사기, 꼼수, 딥페이크 또는 기타 불법 활동에 사용 금지
- 현지 법률과 규정을 준수하고 윤리적 기준 적용
AI 기술은 책임감 있게 활용되어야 합니다. 앞으로 AI 연구와 응용 분야가 지속적으로 발전하기 위해서는, 우리 모두가 AI를 사용할 때 안전과 윤리 원칙을 철저히 준수하는 자세가 필요합니다.
라이선스
Spark-TTS는 Apache License 2.0 하에 배포되어, 사용자가 자유롭게 수정, 배포, 그리고 상업적 활용까지 할 수 있습니다. 단, 라이선스 조건에 따라 소스 코드 변경 시 변경 사항을 명시해야 하며, 원저작권과 라이선스 고지사항을 포함해야 합니다. 특허 권한까지 명확히 포함되어 있어, 상업적 프로젝트나 제품에 적용하기에도 적합한 오픈소스 라이선스입니다.
목차
1. 실행 환경
2. Spark-TTS 다운로드
3. Spark-TTS 실행
1. 실행 환경
- 운영체제 : Windows 11
- Python: 3.12.0
- torch : 2.5.1
- GPU : NVIDIA GeForce RTX 4060 Ti
2. Spark-TTS 다운로드
Spark-TTS는 아래 깃허브와 허깅페이스를 통해 코드와 모델 파일을 다운로드할 수 있습니다.
- Spark-TTS 깃허브 : https://github.com/SparkAudio/Spark-TTS
- Spark-TTS 허깅페이스 : https://huggingface.co/SparkAudio/Spark-TTS-0.5B/tree/main
다운로드 후 다음과 같이 파일을 구성해줍니다.
- 먼저 깃허브에서 Spark-TTS 코드를 다운로드하고, 압축을 풀어줍니다.
- 압축을 푼 Spark-TTS 폴더 안에 "pretrained_models/Spark-TTS-0.5B 폴더"를 새로 생성합니다.
- Hugging Face에서 받은 모델 파일들을 위에서 만든 pretrained_models/Spark-TTS-0.5B 폴더 안에 넣어주면 됩니다.


파일 설정이 완료되셨다면, 아래 명령어를 통해 필요한 패키지들을 설치해줍니다.
# WindowPowerShell
cd ./Path/to/Spark-TTS # 깃허브에서 다운받은 Spark-TTS 파일로 위치 이동
pip install -r requirements.txt # 필요 패키지 설치
pip install torch torchvision torchaudio # Pytorch 설치
PyTorch를 CUDA를 지원하는 버전으로 설치하여 GPU 가속을 활용하고 싶으신 경우, 자신의 그래픽 카드에 맞는 CUDA 버전으로 설치하셔도 괜찮습니다. 다만, Spark-TTS는 CPU 환경에서도 충분히 빠르게 실행되기 때문에, 특별한 필요가 없다면 기본 명령어로 설치하셔도 문제 없습니다.
3. Spark-TTS 실행
위 명령어를 사용하여 Spark-TTS를 실행시켜 줍니다.
# Windows PowerShell
python webui.py
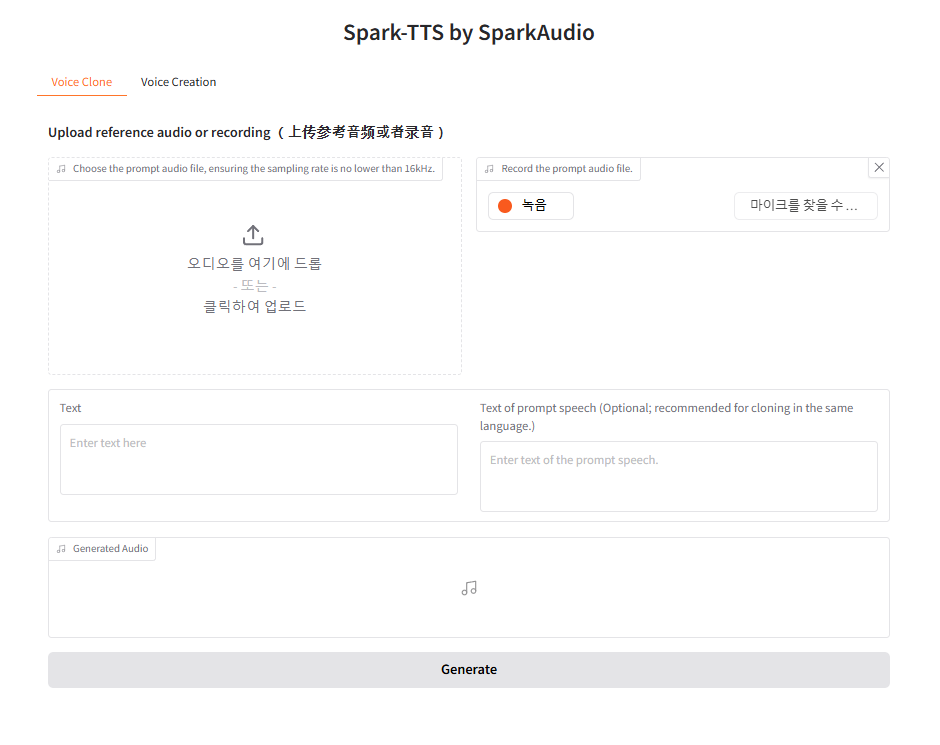
위 이미지는 Spark-TTS가 정상적으로 실행된 화면입니다. Web UI 화면(오른쪽 이미지)에서 복제할 음성을 업로드한 후, "Text" 입력란에 복제된 음성이 읽을 내용을 작성해주면 됩니다. 아래는 실제로 생성해본 결과입니다.
[AI 음성 생성 결과]
이번 테스트에서는 미국 영화 배우 덴젤 워싱턴의 목소리를 사용해 AI 음성 복제를 진행했습니다. 학습에 사용된 음성 데이터는 약 25초 분량입니다.
- 사용한 음성 : 미국 영화 배우, 덴젤 워싱턴
- 학습에 사용된 음성 길이 : 25초
Spark-TTS 모델은 1.1GB의 VRAM을 사용하여 처리되었으며, 음성 생성까지 소요된 시간은 약 17초였습니다. 비교적 짧은 학습 데이터와 낮은 리소스 환경에서도 자연스러운 덴젤 워싱턴의 목소리를 재현해내는 결과를 확인할 수 있었습니다.
짧은 25초 분량의 음성 데이터와 최소한의 자원으로도 특정 인물의 목소리를 정교하게 재현해내는 Spark-TTS의 성능은 정말 인상적입니다. 특히, 별도의 대규모 학습 없이 제로샷으로 이 정도의 결과를 보여준다는 점은 AI 음성 합성 기술의 빠른 발전을 실감하게 합니다.
하지만 이러한 기술의 발전과 함께 우리가 반드시 잊지 말아야 할 것이 있습니다. AI로 생성된 음성은 강력한 만큼 사칭, 딥페이크, 사기 등 악용 가능성 역시 존재합니다. AI를 사용하는 모두가 윤리적 책임을 깊이 인식하고, 기술을 올바른 방향으로 활용해야 합니다.
Spark-TTS가 보여준 놀라운 기술력은 분명 인상적이지만, 그만큼 책임감 있는 사용이 그 어느 때보다 중요해지고 있습니다.우리 모두가 AI 기술의 가능성을 존중하는 동시에, 윤리와 법적 기준을 지키며 건강한 AI 생태계를 만들어 가길 바랍니다.
감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [오픈 소스 AI] 로블록스가 만든 "텍스트 to 3D 모델", Cube 3D를 소개합니다. (0) | 2025.03.30 |
|---|---|
| [오픈 소스 AI] 음성 스타일까지 복제하는 AI, Sesame을 소개합니다. (0) | 2025.03.26 |
| 구글의 온디바이스 모델 Gemma3를 소개합니다. (0) | 2025.03.19 |
| [오픈 소스 AI] Deepseek와 동급의 무료 고성능 추론 모델, QwQ를 소개합니다. (0) | 2025.03.15 |
| 국내 기업 카카오의 오픈 소스 AI 모델, Kanana를 소개합니다. (0) | 2025.03.05 |



