안녕하세요,
이번에 소개해 드릴 AI는 영상을 분석하여 그에 맞는 소리나 음성을 생성해 주는 모델입니다. 이 모델은 AI가 영상을 보고 적절한 효과음, 음성, 혹은 음악을 자동으로 만들어 줍니다. 이제 영상뿐만 아니라, 그에 어울리는 소리까지 AI가 생성할 수 있게 되었습니다. 그럼, 이 AI 모델에 대해 자세히 알아보겠습니다.
MMAudio 란
MMAudio는 비디오와 텍스트 입력을 기반으로 동기화된 오디오를 생성하는 모델입니다. 이 모델의 핵심 혁신은 다양한 오디오-비주얼 및 오디오-텍스트 데이터 세트를 활용한 멀티모달 조인트 트레이닝을 가능하게 한다는 점입니다. 또한, 동기화 모듈을 통해 생성된 오디오가 비디오 프레임과 정밀하게 정렬되어, 자연스럽게 일치하는 영상과 오디오를 만들어냅니다.
- MMAudio 프로젝트 페이지 : https://hkchengrex.com/MMAudio/
주요 특징
- 멀티모달 공동 학습: 비디오-오디오 및 텍스트-오디오 데이터셋을 활용하여 다양한 입력에 대응하는 오디오 생성을 가능하게 합니다.
- 동기화 모듈: 생성된 오디오와 비디오 프레임을 정밀하게 동기화하여 자연스러운 합성을 보장합니다.
라이선스
MMAudio는 MIT 라이선스가 적용된 오픈소스 소프트웨어로, 상업적 용도를 포함하여 누구나 자유롭게 사용할 수 있습니다. 또한, 소스 코드를 수정하거나 새로운 형태로 배포하는 것도 가능합니다. 다만, 원작자의 저작권 표기를 반드시 유지해야 합니다.
사전 준비 사항
이 포스팅에서는 ComfyUI에서 MMAudio 모델을 활용하는 방법을 다룹니다. 본문을 읽기 전에 아래 항목들을 미리 설치해 주세요. 이번 포스팅에서는 Stability Matrix와 ComfyUI를 사용하여 진행했지만, 로컬에 직접 설치하여 실행해도 무방합니다.
[로컬에 직접 ComfyUI 설치하기]
- ComfyUI 설치: [Marcus' Story] - [ComfyUI] [로컬 환경] ComfyUI 로컬 환경에 설치 및 실행 방법
- ComfyUI-Manager 설치: [Marcus' Story] - [ComfyUI] [로컬 환경] ComfyUI 관리 도구, ComfyUI-Manager 설치하기
[Stabiliy Matrix&ComfyUI 설치하기]
- ComfyUI 설치: [Marcus' Story] - [ComfyUI] 초보자도 쉽게 따라하는 Stability Matrix 활용하기
- ComfyUI-Manager 설치: [Marcus' Story] - [ComfyUI] Stability Matrix에 ComfyUI-Manager 설치하기
목차
1. 실행 환경
2. ComfyUI 사용 노드
3. 다운로드 및 설치
4. 오디오 생성
1. 실행 환경
- 운영체제 : Windows 11
- ComfyUI : 0.3.24
- ComfyUI-Manager : V3.30
- Python : 3.10.11
- torch : 2.6.0 + cu124
- accelerate : 1.4.0
- GPU : NVIDIA GeForce RTX 4060 Ti
2. ComfyUI 사용 노드
이번 포스팅에서 사용하는 커스텀 노드는 다음과 같습니다.
모델 실행에 필수적인 노드는 "필수", 선택적으로 사용할 수 있는 노드는 "선택 사항"으로 표시했습니다.
- ComfyUI-MMAudio: ComfyUI에서 MMAudio 모델을 활용할 수 있도록 지원하는 커스텀 노드입니다. 이를 통해 MMAudio 모델 파일을 배치하고, 관련 노드를 추가할 수 있습니다. (필수)
- ComfyUI-VideoHelperSuite: ComfyUI에서 영상 생성을 지원하는 커스텀 노드입니다. 이를 통해 Load Video, Video Info, Video Combine 등의 노드를 사용할 수 있습니다. (필수)
3. 다운로드 및 설치
1) 커스텀 노드 다운로드
커스텀 노드는 ComfyUI-Manager를 통해 다운로드하고 설치할 수 있습니다. ComfyUI-Manager가 정상적으로 설치되어 있다면, ComfyUI 화면 상단에 "Manager" 버튼이 표시됩니다. 이 버튼을 클릭하여 실행하세요.

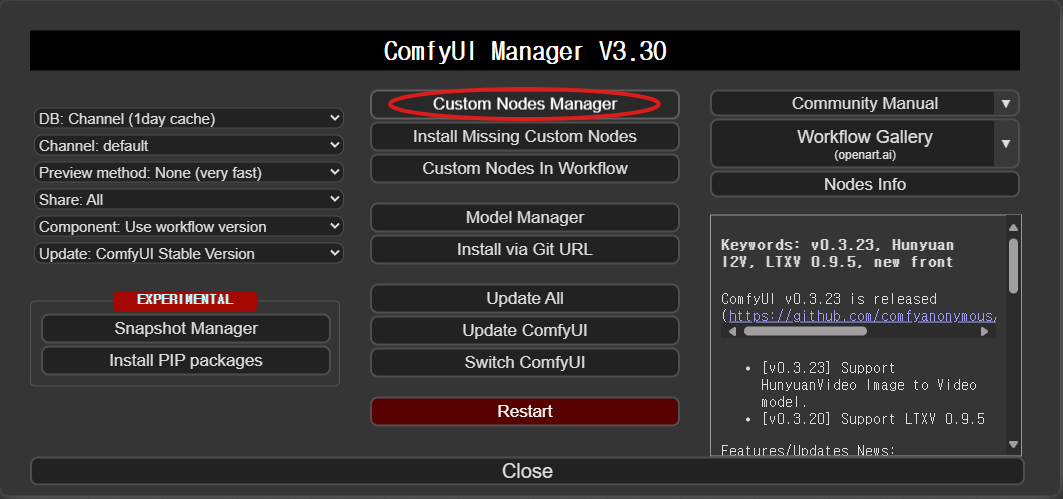
ComfyUI-Manager에서 MMAudio와 VideoHelperSuite를 검색한 후 설치합니다. 이미 설치되어 있다면, 최신 버전으로 업데이트하는 것을 권장합니다.
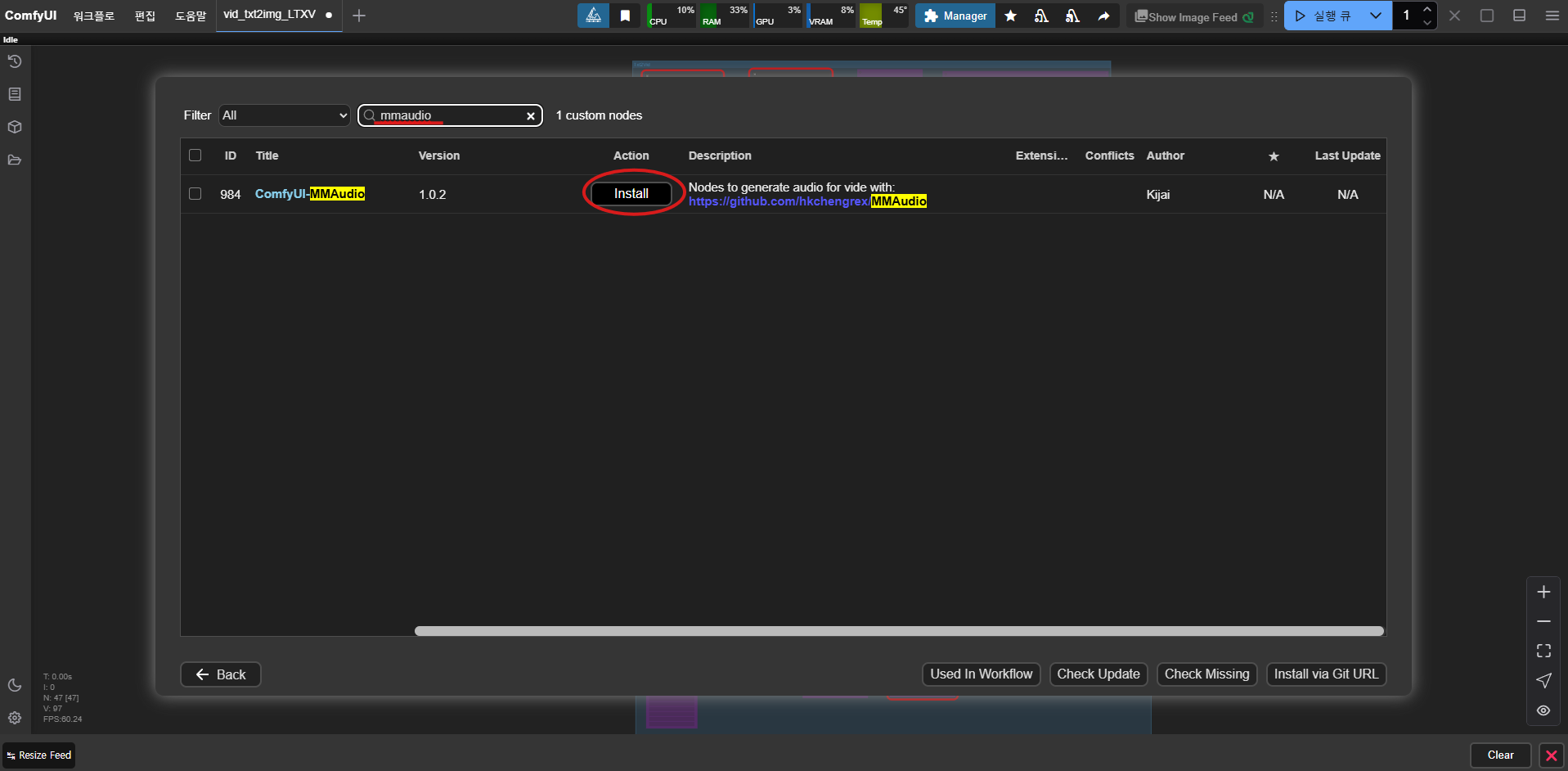
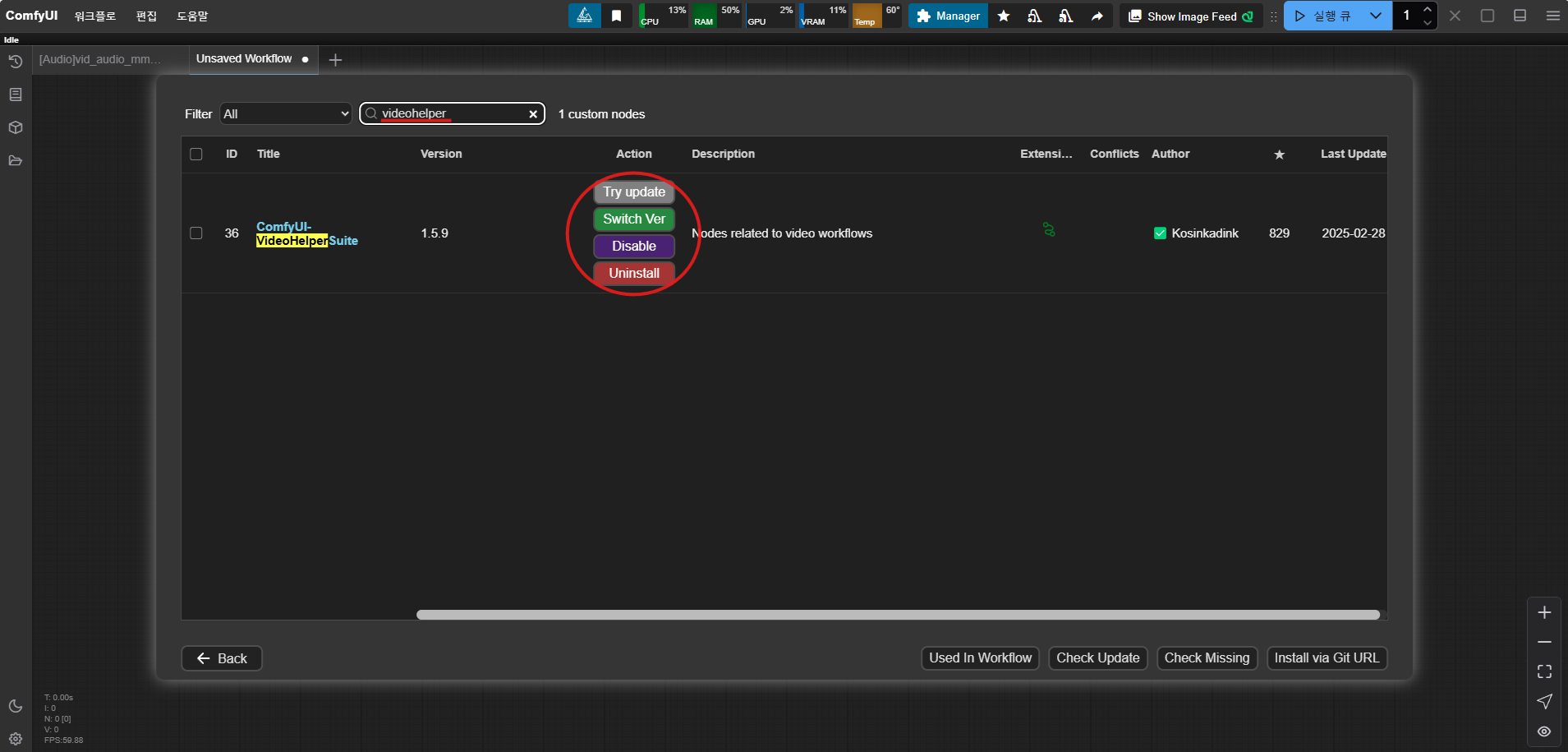
2) 필수 패키지 설치
아래 명령어를 통해 필수 패키지를 설치합니다.
# Windows PowerShell
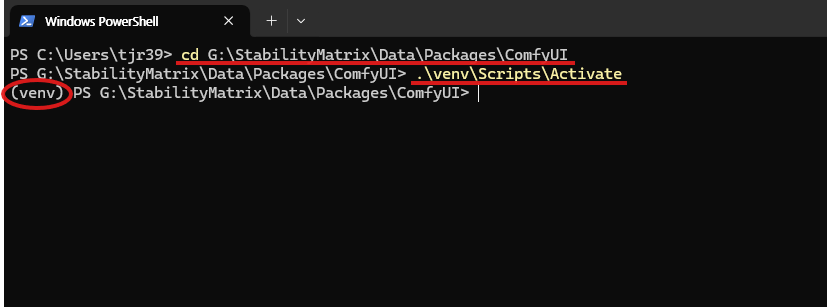
cd Path\to\StabilityMatrix\Data\Packages\ComfyUI # ComfyUI 가상 환경 경로로 이동
.\venv\Scripts\Activate # 가상 환경 활성화
pip install accelerate # accelerate 패키지 설치
ComfyUI의 가상 환경 경로는 Stability Matrix를 다운로드한 위치에서 확인할 수 있습니다. 해당 경로를 설정한 후 가상 환경이 정상적으로 활성화되면, 아래 이미지와 같이 "(venv)" 표시가 출력됩니다.
3) MMAudio 모델 다운로드 및 위치 설정
아래 Kijai의 Hugging Face 페이지에서 모델 파일을 다운로드합니다. 모델은 fp16 버전과 fp32 버전 두 가지가 제공되며, 이번 포스팅에서는 fp16 버전을 사용하였습니다.
- Kijai/MMAudio_safetensors 허깅페이스 : https://huggingface.co/Kijai/MMAudio_safetensors/tree/main

다운로드가 완료되면 해당 파일을 mmaudio 폴더로 이동시켜줍니다.
(StabilityMatrix) → (Data) → (Packages) → (ComfyUI) → (models) →(mmaudio)
4. 오디오 생성
이제 앞서 설치한 MMAudio 모델을 활용하여 직접 오디오를 생성해보겠습니다. 먼저 ComfyUI를 실행한 뒤, MMAudio workflow를 실행합니다. MMAudio workflow는 MMAudio 커스텀 노드를 설치할 때 자동으로 다운로드되며, 해당 파일은 아래 경로에서 찾을 수 있습니다. 이후, "mmaudio_test.json" 파일을 ComfyUI 실행 화면으로 드래그하여 실행하면 됩니다.
- MMAudio workflow 위치 경로 : (StabilityMatrix) → (Data) → (Packages) → (ComfyUI) → (custom_nodes) →(comfyui-mmaudio) →(example_workflows)

각 노드에 알맞은 데이터를 입력해 주세요.
- [Load Video 노드] : 오디오를 추가할 영상을 입력합니다.
- [MMAudio Sampler 노드] : 원하는 오디오를 프롬프트로 입력합니다.
- 긍정 프롬프트 : The sizzling and crackling sound of fresh vegetables roasting over an open flame.
- 부정 프롬프트 : voice
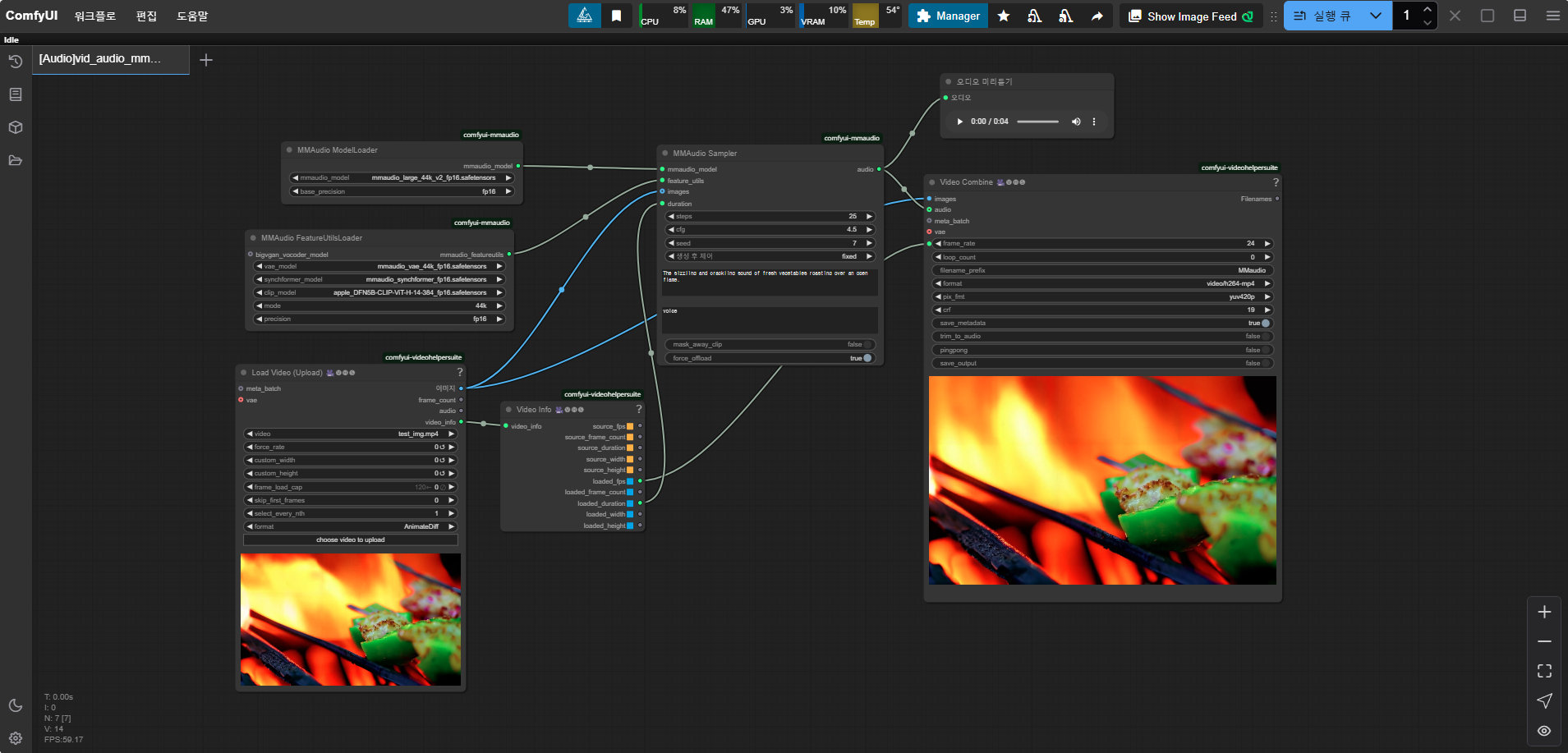
(결과)
[Load Video 노드]에 입력한 영상 (오디오 없음)
MMAudio를 통해 오디오를 생성한 영상
MMAudio를 사용하여 약 4초 길이의 영상에 오디오를 생성할 때, 약 8~9GB의 VRAM이 소요되었으며, 10초 이내로 빠르게 생성되었습니다. 이를 통해 짧은 길이의 영상에서는 매우 신속하게 오디오가 합성됨을 확인할 수 있습니다.
이제 AI는 단순한 보조 도구를 넘어, 영상을 분석하고 그에 적합한 오디오를 자동으로 생성할 수 있는 수준까지 발전하고 있습니다. AI 기술이 계속해서 고도화됨에 따라, 영상과 음성을 자연스럽게 결합하는 다양한 솔루션이 등장할 것으로 기대됩니다. 앞으로도 AI가 가져올 혁신적인 변화를 주목하며, 이를 적극적으로 활용하는 것이 중요할 것으로 보입니다.
감사합니다. 😊
'ComfyUI > 오디오 생성' 카테고리의 다른 글
| [ComfyUI + 오디오 생성 AI] Suno 무료 버전의 음원 생성 AI 모델, Ace-step를 소개합니다. (1) | 2025.05.30 |
|---|
