안녕하세요,
최근 들어 영상 생성 AI 기술이 빠르게 발전하면서 특히 중국의 기술이 눈에 띄는 성과를 보여주고 있습니다. 오늘은 이러한 흐름 속에서 주목받고 있는 중국 기업, 텐센트의 최신 AI 비디오 생성 모델, Hunyuan Video에 대해 소개하려고 합니다. 이번 포스팅에서는 ComfyUI를 활용하여 Hunyuan Video AI를 사용해보는 방법에 대해 소개하겠습니다.
Hunyuan Video
Hunyuan Video는 중국 텐센트가 개발한 최신 AI 비디오 생성 모델로, 텍스트 입력만으로 고품질의 비디오를 생성할 수 있습니다. 이 모델은 자연스러운 동작과 뛰어난 시각적 품질을 제공하며, 영화 제작에도 적합한 수준의 결과물을 만들어냅니다. Hunyuan Video는 성능 면에서 기존 상위 모델을 능가하며, 텍스트와 비디오 간의 높은 정렬도, 부드러운 모션 품질, 선명한 시각적 효과로 우수한 평가를 받았습니다.
- Hunyuan Video 공식사이트 : https://aivideo.hunyuan.tencent.com/

GitHub에서 제공되던 Hunyuan Video는 최소 45GB VRAM이 필요한 고사양 컴퓨팅 환경에서만 실행할 수 있었지만, ComfyUI v0.3.10 버전의 등장으로 이제 8GB VRAM을 가진 GPU에서도 실행이 가능해졌습니다. 이는 VAE Decode(타일) 또는 VAE Encode(타일) 노드를 통해 비디오 VAE에 시간적 타일링 기능을 지원함으로써, 기존에 요구되던 VRAM 용량을 크게 줄일 수 있게 되었습니다.
사전준비사항
이 포스팅은 ComfyUI에서 Hunyuan Video 모델을 활용하는 방법에 대한 내용입니다. 따라서 본문을 읽기 전에 ComfyUI와 ComfyUI-Manager를 미리 설치해 주시기 바랍니다.
- ComfyUI 설치 방법 : [Macus' Story] - [이미지 생성 AI] [로컬 환경] ComfyUI 이용하여 이미지 생성하기 1탄
- ComfyUI-Manager 설치 방법 : [Marcus' Story] - [이미지 생성 AI] [로컬 환경] ComfyUI 이용하여 이미지 생성하기 2탄 : ComfyUI-Manager
목차
1. 실행 환경
2. ComfyUI 사용 노드
3. 모델 다운로드 및 위치 설정
4. 노드 구성
5. 실행 (영상 생성)
1. 실행 환경
- 운영체제 : Windows 11
- ComfyUI : 0.3.10
- ComfyUI-Manager : V2.55.5
- Python : 3.10.0
- torch : 2.3.1 + cu121
- GPU : NVIDIA GeForce RTX 4060 Ti
2. ComfyUI 사용 노드
이번 포스팅에서는 별도로 다운로드한 커스텀 노드는 없지만, ComfyUI의 최신 버전으로 업데이트하는 것이 중요합니다. 최신 버전으로 업데이트하면 모델과의 호환성을 최대한 확보할 수 있으며, 성능 개선 및 버그 수정을 통해 최적의 결과를 얻을 수 있습니다. ComfyUI-Manager에서 "Update ComfyUI" 버튼을 클릭하여 최신 버전으로 간편하게 업데이트할 수 있습니다.
3. 모델 다운로드 및 위치 설정
ComfyUI에서 영상을 생성을 위한 Hunyuan Video 모델과 text_encoder모델, vae 모델을 다운로드합니다.
1) Hunyuan Video 모델 파일 다운로드
아래 ComfyUI 허깅페이스 페이지에서 "hunyuan_video_t2v_720p_bf16.safetensors"모델을 다운로드합니다.
- ComfyUI 허깅페이스 : https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/tree/main/split_files/diffusion_models
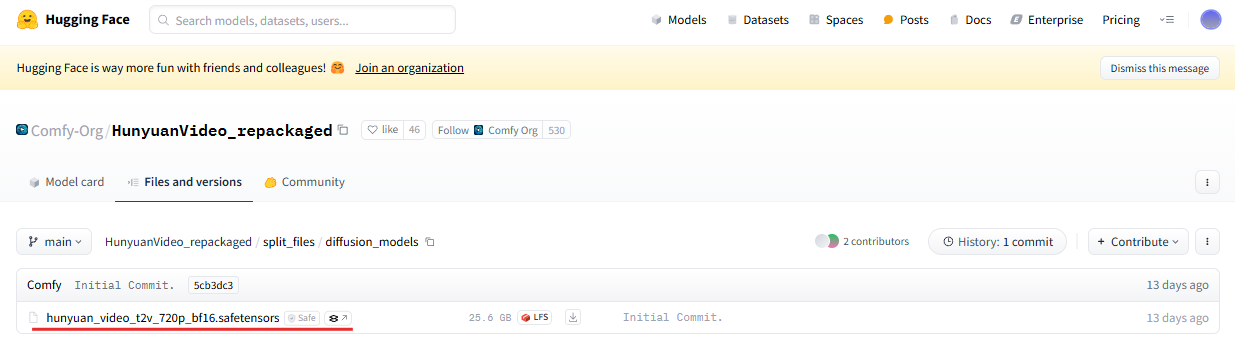
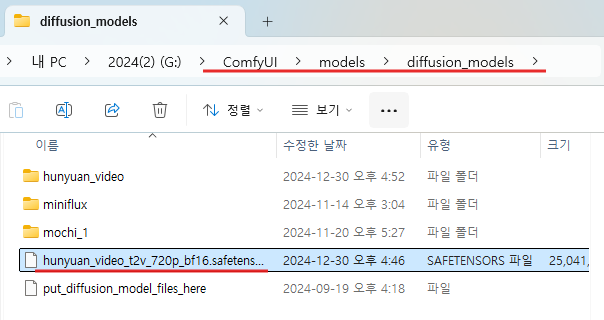
모델 파일 다운로드가 완료되면 해당 모델 파일을 diffusion_models 폴더로 이동시켜줍니다.
(ComfyUI 폴더) → (models 폴더) → (diffusion_models 폴더)
2) text_encorder 모델 파일 다운로드
아래 ComfyUI 허깅페이스 페이지에서 "clip_l.safetensors" 모델과 "llava_llama3_fp8_scaled.safetensors" 모델을 다운로드합니다. "llava_llama3_fp16.safetensors" 모델은 더 높은 컴퓨터 사양을 요구하므로, vram이 충분하신 분들만 다운로드 해주시길 바랍니다.
- ComfyUI 허깅페이스 : https://huggingface.co/Comfy-Org/HunyuanVideo_repackaged/tree/main/split_files/text_encoders
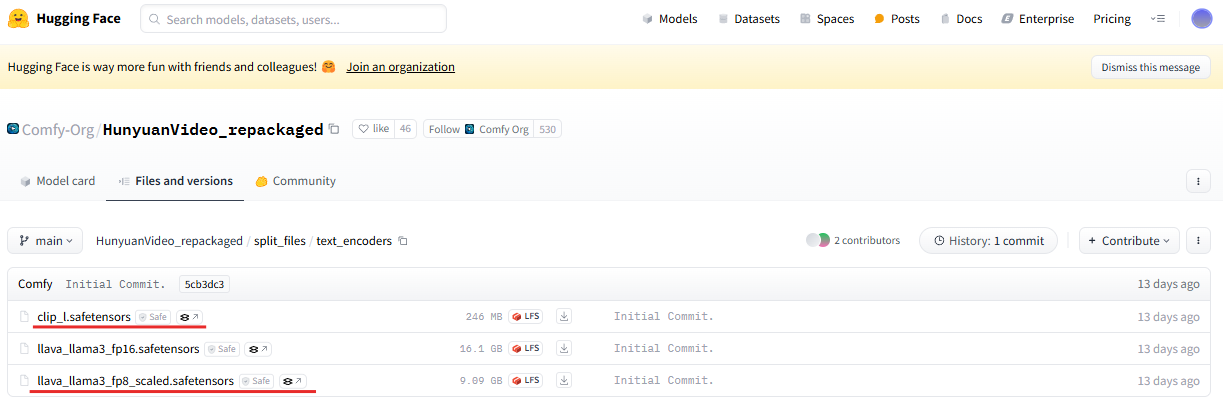
모델 파일 다운로드가 완료되면 해당 모델 파일을 text_encoders 폴더로 이동시켜줍니다.
(ComfyUI 폴더) → (models 폴더) → (text_encoders 폴더)

3) vae 모델 파일 다운로드
아래 ComfyUI 허깅페이스 페이지에서 "hunyuan_video_vae_bf16.safetensors"모델을 다운로드합니다.

모델 파일 다운로드가 완료되면 해당 모델 파일을 vae 폴더로 이동시켜줍니다.
(ComfyUI 폴더) → (models 폴더) → (vae 폴더)

4. 노드 구성
노드 구성은 현재 ComfyUI에서 제공해주는 노드를 그대로 사용했습니다. 아래 링크를 통해 노드를 다운로드 받으실 수 있습니다.
- ComfyUI 노드 제공 페이지 : https://comfyanonymous.github.io/ComfyUI_examples/hunyuan_video/
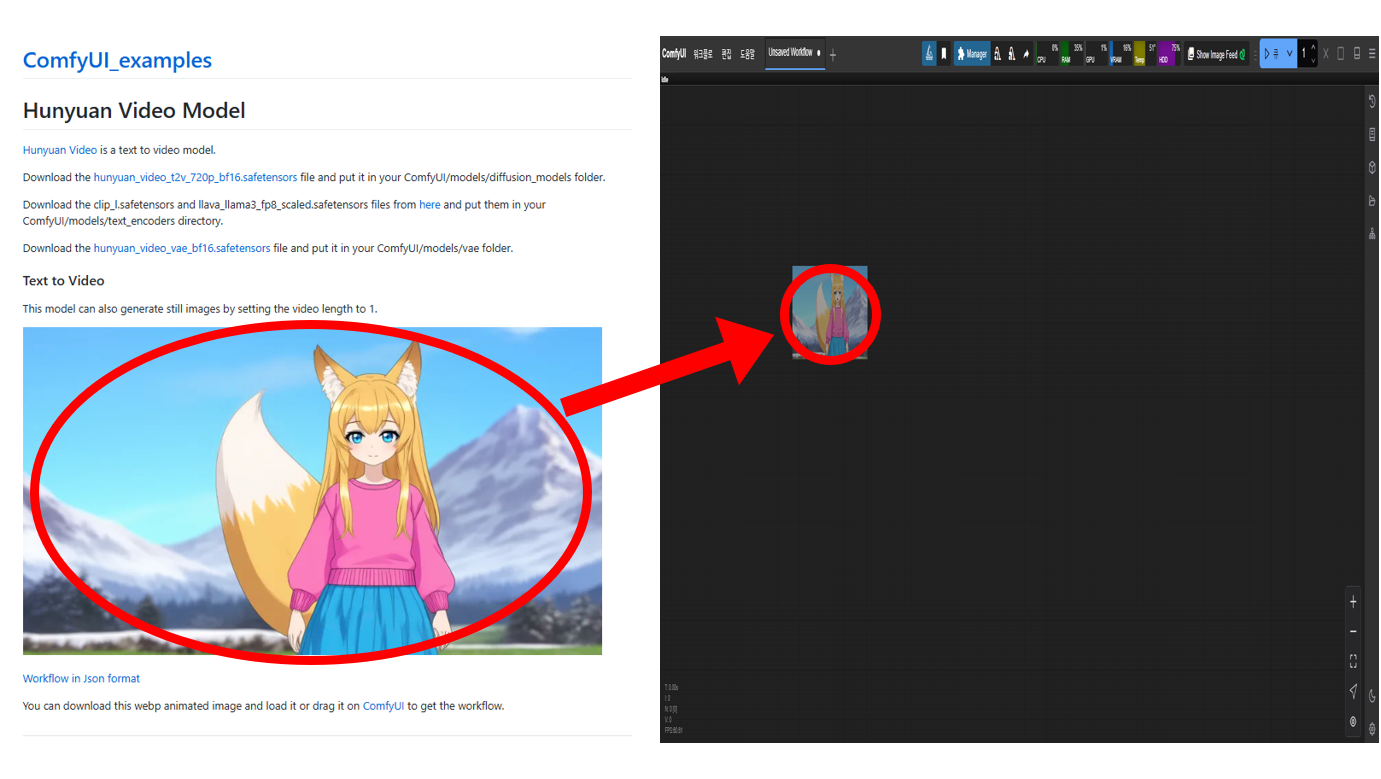
위 페이지에서 제공되는 이미지를 마우스 왼쪽 버튼으로 클릭한 상태에서, 현재 실행 중인 ComfyUI 창으로 드래그하면 Hunyuan Video를 실행하기 위한 노드들이 자동으로 구성됩니다.
5. 실행 (영상 생성)
영상 생성에는 fp8 버전 모델을 활용했습니다. 해상도는 848 x 480으로 설정했으며, 약 3초 길이의 영상을 제작했습니다. 현재 사용 중인 컴퓨팅 사양(VRAM 16GB) 기준으로, 이 조건에서 영상을 생성하는 데 약 20분이 소요되었습니다. 노드 옵션을 조금 더 조정하면 더 낮은 VRAM에서도 영상 생성이 가능할 것으로 보입니다.
영상 품질은 아직 더 검토가 필요하지만, 첫인상으로는 만족스러운 퀄리티를 보여주고 있습니다. 왼손 모양이 약간 어색하게 표현되었지만, 전체적으로 움직임이 자연스럽고 어색함이 적어 보입니다. 아래는 생성된 영상입니다.

처음 Hunyuan Video 모델이 공개되었을 때는 높은 컴퓨팅 사양이 요구되어 실행 자체가 어려웠지만, 이제는 낮은 VRAM 환경에서도 실행할 수 있도록 크게 개선되었습니다. 이로 인해 고사양 장비가 없어도 누구나 손쉽게 고퀄리티 영상을 생성할 수 있게 되었습니다. 이러한 기술적 발전은 AI 비디오 생성의 진입 장벽을 낮추고, 더 많은 사람들이 창의적인 작업에 활용할 수 있는 새로운 기회를 제공하리라 믿습니다.
앞으로도 다양한 조건에서 실험을 지속하며, 효율적인 방법과 뛰어난 결과물을 꾸준히 공유하겠습니다.
2024년 한 해 잘 마무리하시고, 행복한 시간 보내시길 바랍니다. 감사합니다. 😊
'ComfyUI > 영상 생성' 카테고리의 다른 글
| [ComfyUI] [영상 생성 AI] 텐센트의 비디오 생성 AI, HunyuanVideo-I2V를 소개합니다. (0) | 2025.03.12 |
|---|---|
| [영상 생성 AI] [로컬 환경] ComfyUI 이용하여 영상 생성하기 8탄 : Nvidia-cosmos 모델 (0) | 2025.02.18 |
| [영상 생성 AI] [로컬 환경] ComfyUI 이용하여 영상 생성하기 6탄 : LTX-Video AI (1) | 2024.12.05 |
| [영상 생성 AI] [로컬 환경] ComfyUI 이용하여 영상 생성하기 5탄 : Mochi AI (2) | 2024.11.20 |
| [영상 생성 AI] [로컬 환경] ComfyUI 이용하여 영상 생성하기 4탄 : PyramidFlowWrapper (1) | 2024.11.14 |



