안녕하세요,
스마트폰에서 음성 명령으로 검색을 하거나, 유튜브 영상에 자동 생성된 자막을 본 적이 있나요? 바로 이러한 기능들은 음성 인식 기술 덕분에 가능해진 것입니다. 특히, OpenAI가 개발한 Whisper는 그 중에서도 주목받는 음성 인식 AI 모델입니다. Whisper는 단순히 음성을 텍스트로 변환하는 것에 그치지 않고, 다양한 언어를 인식하고, 소음이 많은 환경에서도 정확하게 작동하도록 설계되었습니다. 이는 유튜브와 같은 플랫폼에서 제공되는 자동 자막 생성 기능과 같은 사례에서 활용될 수 있습니다. 이번 포스팅에서는 이러한 Whisper 모델에 대해 간단히 소개하고, 로컬 환경에서 설치 및 사용하는 방법에 대해 소개하도록 하겠습니다.
Whisper AI
Whisper는 OpenAI에서 개발한 대규모 다국어 음성 인식 모델로, 자동 음성 인식(ASR), 번역, 언어 식별 등 다양한 음성 처리 작업을 수행할 수 있습니다. 이 모델은 음성 파일을 인식하여 텍스트로 변환하며, 다양한 길이의 음성 데이터를 처리할 수 있습니다. 특히, Whisper는 소음이 많은 환경이나 저자원 언어에서도 우수한 성능을 발휘하도록 설계되었습니다. 또한, 사전 훈련된 모델로 별도의 fine-tuning 없이 바로 사용할 수 있으며, 언어 감지 기능을 통해 다국어 음성을 자동으로 인식합니다. "Whisper-large-v3"는 Whisper 모델 중 가장 큰 버전으로, 더 작은 모델에 비해 성능과 정확도가 향상되었습니다.
Whisper 라이선스
Whisper 모델은 Apache 2.0 라이선스 하에 제공됩니다. 이 라이선스는 비교적 자유로운 사용을 허용하며, 상업적 이용, 수정 및 배포가 가능합니다. 다만, Apache 2.0 라이선스는 소스 코드를 변경할 경우 그 변경 사항을 명시해야 하고, 라이선스 파일을 포함해야 한다는 조건이 있습니다.
- OpenAI Whisper 허깅페이스 : https://huggingface.co/openai/whisper-large-v3
openai/whisper-large-v3 · Hugging Face
Whisper Whisper is a state-of-the-art model for automatic speech recognition (ASR) and speech translation, proposed in the paper Robust Speech Recognition via Large-Scale Weak Supervision by Alec Radford et al. from OpenAI. Trained on >5M hours of labeled
huggingface.co
목차
1. 실행 환경
2. Whisper 설치
3. Whisper 실행
1. 실행 환경
- 운영체제 : Windows 11
- Python : 3.10.0
- accelerate : 1.0.1
- torch : 2.3.1 + cu121
- torchaudio : 2.3.1 + cu121
- transformers : 4.45.2
- GPU : NVIDIA GeForce RTX 4060 Ti
2. Whisper 설치
Whisper 모델을 실행하기 위해 필요한 패키지 및 모델을 다운받습니다.
1) Whisper-large-v3 모델 다운로드
아래 OpenAI 허깅페이스에서 Whisper-large-v3 모델파일을 다운받습니다.
- OpenAI Whisper 허깅페이스 : https://huggingface.co/openai/whisper-large-v3/tree/main
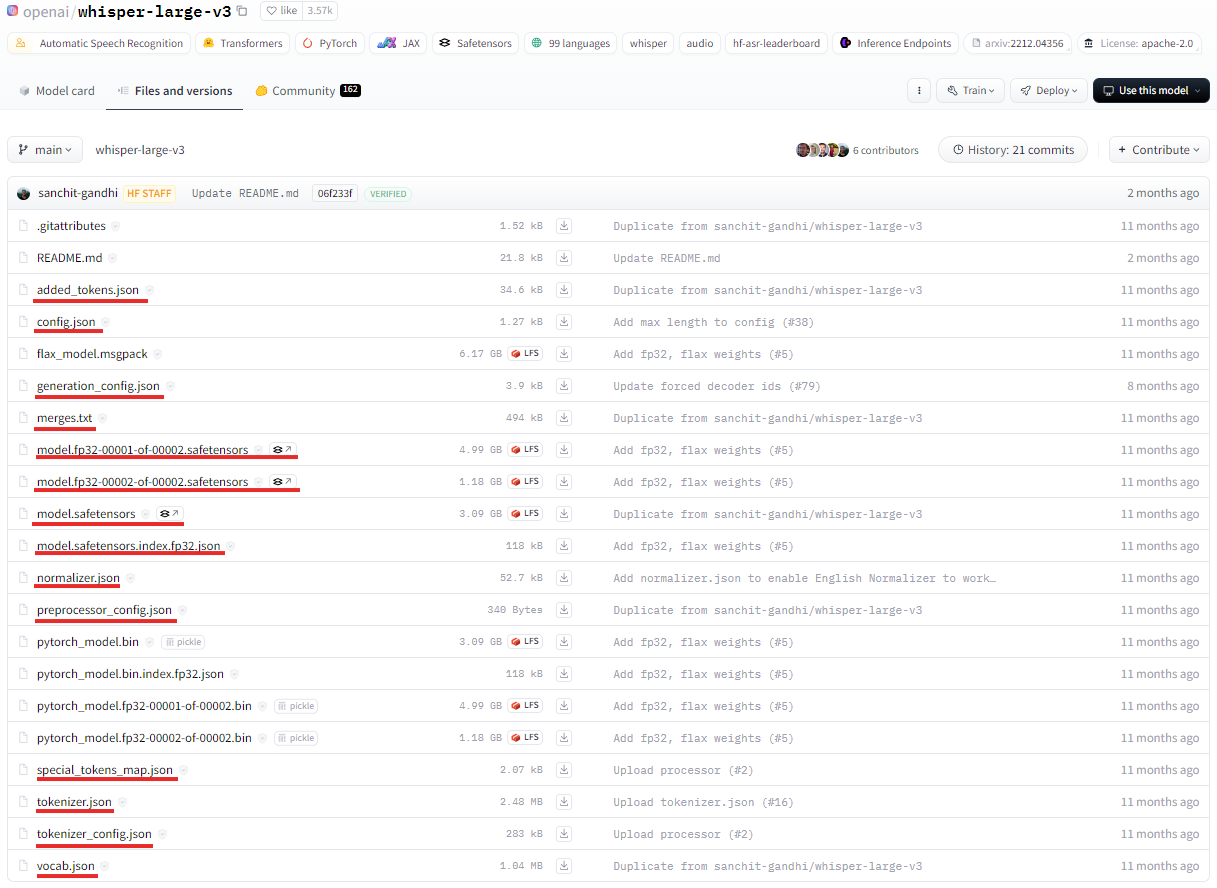
이 페이지에서 Whisper-large-v3 모델은 여러 파일 형식으로 제공됩니다. 각 형식은 사용 환경에 따라 다르게 선택할 수 있으며, 필요한 파일 형식만 다운로드하시면 됩니다. 이번 포스팅에서는 PyTorch를 사용하여 모델을 실행할 예정으로, 기본적으로 `pytorch_model.bin` 또는 `safetensors` 파일 중 하나를 다운로드하여 사용할 수 있습니다. 이번 포스팅에서는 safetensors 파일을 사용하여 모델을 실행해보도록 하겠습니다.
2) 필요 패키지 설치
아래 명령어를 통해 Whisper-large-v3 모델 실행에 필요한 패키지를 설치합니다.
# Windows Powershell
pip install torch torchaudio transformers accelerate
3) Python 코드 작성 및 파일 구성
아래와 같이 Python 코드를 작성합니다.
import torch
from transformers import AutoModelForSpeechSeq2Seq, AutoProcessor, pipeline
import torchaudio
# 장치 설정 (GPU가 있는 경우 GPU 사용)
device = "cuda:0" if torch.cuda.is_available() else "cpu"
torch_dtype = torch.float16 if torch.cuda.is_available() else torch.float32
# Whisper 모델과 프로세서 로드
model_id = "G:/whisper-large-v3/model"
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id, torch_dtype=torch_dtype, low_cpu_mem_usage=True, use_safetensors=True
)
model.to(device)
processor = AutoProcessor.from_pretrained(model_id)
pipe = pipeline(
"automatic-speech-recognition",
model=model,
tokenizer=processor.tokenizer,
feature_extractor=processor.feature_extractor,
torch_dtype=torch_dtype,
device=device,
)
# 로컬 음성 파일 로드
path_to_audio = "G:/whisper-large-v3/audio/1.wav"
waveform, sample_rate = torchaudio.load(path_to_audio)
# Whisper 모델에서 사용할 수 있는 16,000Hz로 샘플링 레이트 변환
if sample_rate != 16000:
waveform = torchaudio.transforms.Resample(orig_freq=sample_rate, new_freq=16000)(waveform)
sample_rate = 16000
# 변환한 오디오 데이터 사용
inputs = processor(waveform.squeeze().numpy(), sampling_rate=sample_rate, return_tensors="pt", language="en").to(device)
# 입력 자료형 변환
inputs["input_features"] = inputs["input_features"].to(dtype=torch_dtype)
# 모델 추론
with torch.no_grad():
generated_tokens = model.generate(inputs["input_features"])
# 텍스트로 변환
transcription = processor.batch_decode(generated_tokens, skip_special_tokens=True)
print("Transcription:", transcription[0])
4) 파일 구성
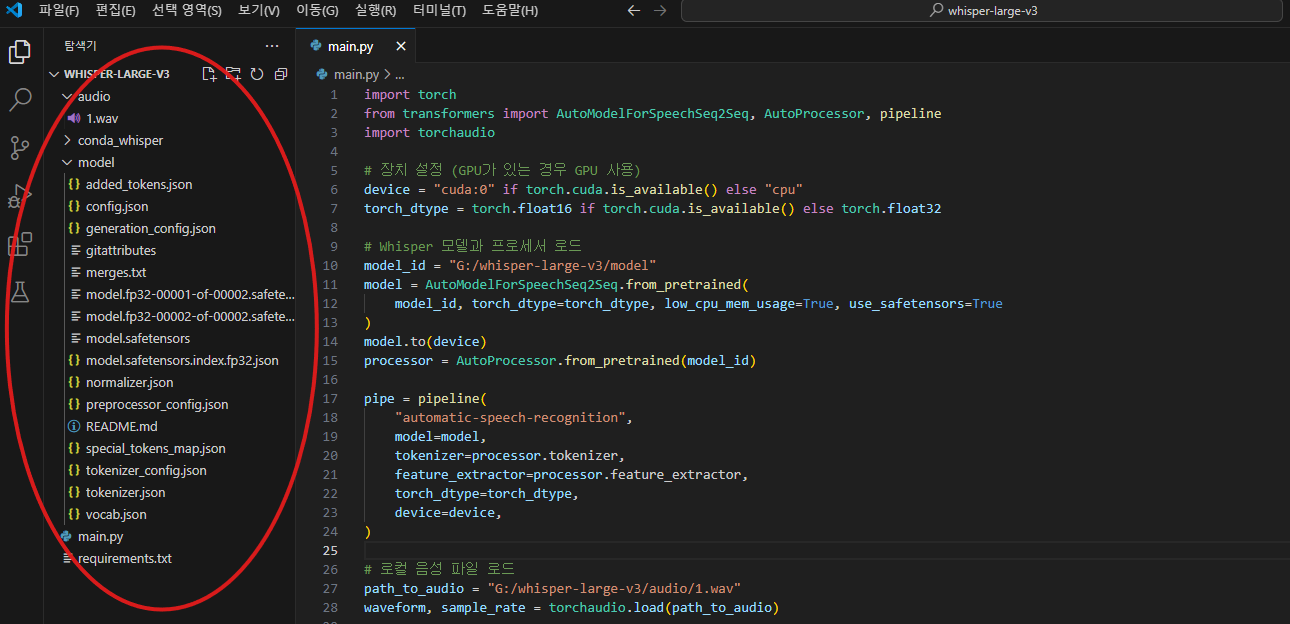
파일 구성은 다음과 같습니다. whisper-large-v3 폴더에는 audio와 model 폴더가 포함되어 있습니다. Hugging Face에서 다운로드한 파일들은 model 폴더에 저장했으며, 샘플로 사용한 음성 파일은 audio 폴더에 위치해 있습니다.
3. Whisper 실행
모든 준비가 완료되었습니다. 이제 Whisper AI를 사용해보겠습니다. 사용한 오디오 파일은 이전에 Hallo 모델을 소개할 때 사용했던 파일로, 아래 샘플 오디오로 확인하실 수 있습니다.
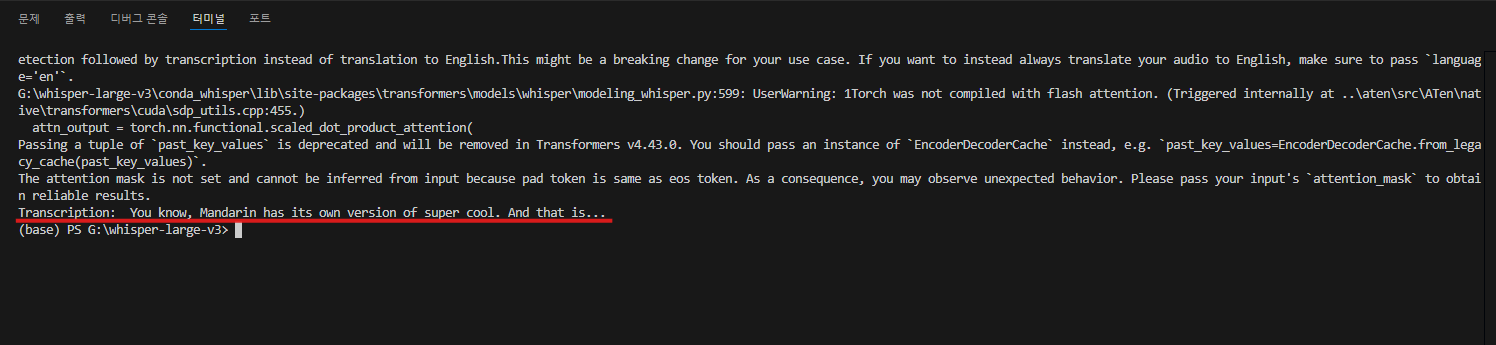
샘플로 사용한 오디오는 약 7초 정도의 길이입니다. 5초 정도의 음성은 정확히 인식하여 텍스트로 변환했으나, 마지막 부분의 발음은 인식하지 못했습니다. 실제 샘플 음성의 마지막 부분이 뭉개져 발음이 불분명했음을 고려하면, Whisper의 성능은 매우 인상적입니다. 특히 뚜렷하고 명확한 발음 부분은 거의 완벽하게 인식했으며, 이는 Whisper 모델이 실생활의 다양한 음성 환경에서도 상당히 높은 정확도를 보여줄 수 있음을 시사합니다.
지금까지 Whisper AI를 로컬 환경에서 사용하는 방법을 살펴보았습니다. Whisper는 음성 인식을 통해 다양한 언어를 처리할 수 있는 강력한 모델입니다. 이 글을 통해 Whisper를 로컬 환경에서 설정하고 사용하는 방법을 이해하는 데 도움이 되었기를 바랍니다. 직접 실험하면서 Whisper의 가능성을 확인해보고, 여러분의 프로젝트에 응용해 보세요. 앞으로도 Whisper와 같은 최신 AI 기술을 활용하여 보다 혁신적인 프로젝트를 만들어 나가길 기대합니다.
감사합니다. 😊
'AI 소식 > 오픈소스 AI 모델' 카테고리의 다른 글
| [영상 생성 AI] [오픈 소스] [로컬 환경] Genmo에서 개발한 영상 생성 AI, Mochi-1를 소개합니다. (0) | 2024.10.31 |
|---|---|
| [오픈 소스 AI] [로컬 환경] 음성을 복제하여 텍스트를 음성으로 바꿔주는 AI, SWivid TTS(Text to Speech)를 소개합니다. (2) | 2024.10.20 |
| [오픈 소스 AI] [로컬 환경] 국내 기업 올거나이즈에서 개발한 한국어 특화 AI 모델을 소개합니다. (0) | 2024.09.30 |
| [이미지 생성 AI] 무료 이미지 생성 AI, FLUX.1 에 대해 소개합니다. (2) | 2024.09.16 |
| [오픈 소스 AI] [로컬 환경] GPT-4o에 필적하는 메타의 새로운 AI 모델, Llama 3.1을 소개합니다. (7) | 2024.09.05 |



